万事开头难啊,刚开头确实不知道该怎么写才能比较有水平,这篇博客可能会比较长,隐马尔科夫模型将会从以下几个方面进行叙述:1 隐马尔科夫模型的概率计算法 2 隐马尔科夫模型的学习算法 3 隐马尔科夫模型的预测算法
隐马尔科夫模型其实有很多重要的应用比如说:语音识别、自然语言处理、生物信息、模式识别等等
同样先说一下什么是马尔科夫,这个名字感觉就像高斯一样,无时无刻的渗透在你的生活中,这里给出马尔科夫链的相关解释供参考:
马尔可夫链是满足马尔可夫性质的随机过程,是具有马尔科夫性质的随机变量的一个数列,![]() 是马尔可夫链(Markov Chain),描述了一种状态序列,其每个状态值取决于前面有限个状态。
是马尔可夫链(Markov Chain),描述了一种状态序列,其每个状态值取决于前面有限个状态。
举个例子,如果后一个状态的变换仅取决以前一时刻的状态的话,用公式来表示就是:
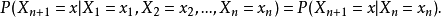
需要注意的就是马尔科夫链并没有限定后一个状态的变化仅仅取决于前一个状态,而是说取决于前面有限个状态!所以上述公式表示仅仅是马尔科夫链的一个特例,称之为一阶马尔科夫链.
需要知道的是一阶马尔科夫其实是为了精简计算而损失精确度的一个方法,因为当前状态的变化和越多的之前状态相关,则越能够精确的描述概率模型,所以如果考虑多阶马尔科夫比如M阶公式:
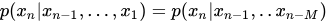 就是和前M个变量相关的意思!
就是和前M个变量相关的意思!
但是多阶马尔科夫链在考虑的精确度的同时就会损失掉简便计算的好处,导致产生非常复杂的计算量,可实现程度就会降低,所以,科学家们就想出了一种既能够使得当前状态变化和更多的前面发生的状态相关又不至于计算复杂度指数增长的方法,那就是今天的主角------隐马尔科夫模型
下面给出李航老师课本上的隐马尔科夫模型的定义:
隐马尔科夫是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程,隐藏的马尔科夫链生成的随机状态的序列被称为状态序列(state sequence),每个状态生成一个观测,由此而产生的观测的随机序列,称之为观测序列(observation sequence) ,序列的每一个位置都可以看作是一个时刻。
设Q是所有可能的状态的集合,V是所有可能的观测的集合 ,其中N是所有可能的状态数,M是所有可能的观测数 。
I是长度为T的状态序列,O是其对应的观测序列.
A是状态转移概率矩阵:,其中,
, 是在时刻t处于状态qi的条件下,在时刻t+1转移到状态qj的概率
B是观测概率矩阵: ,其中,
,是在时刻t处于状态qj的条件下生成观测vk的概率
π是初始时刻的概率向量 :,是时刻t=1处于状态qi的概率
综上所述,隐马尔科夫模型由三个参数构成:λ=(A,B,π)
说了这么一大堆,其实一张图就可以表述的很清楚:
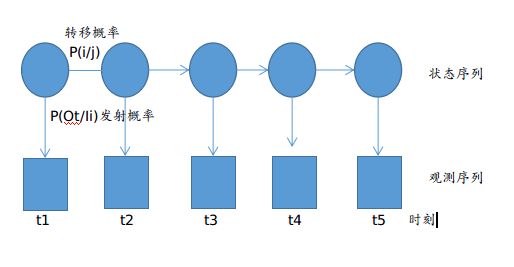
圆圈表示的是状态序列,圆圈和圆圈之间是状态转移概率,转移概率构成的矩阵就是状态转移概率矩阵A,许多方块表示的是观测序列,由圆圈到方块代表了隐藏状态到可观测状态的变化,对应着发射概率,发射概率组成的矩阵就是观测概率矩阵,每个点都代表着一个时刻。
从定义我们也可以知道隐马尔科夫模型作了两个基本的假设:
(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻t的状态只依赖于其前一个时刻的状态,与其他时刻的状态及观测无关,与时刻t也无关!这个从定义中显然是可以得到的公式: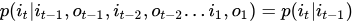
(2)观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,于其他观测及状态无关. 公式: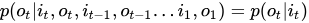
介绍到这里可能还是会有不少童鞋有疑惑,隐马尔科夫链怎么就能够在大大减少计算量的同时还可以增加状态变量的相关性呢?
我仔细考虑了一下,也许正是因为隐变量或者状态变量的引入,导致了这种相关性的大大增强,每一个观测变量的出现都只跟其对应的隐变量有关系,通过隐变量这个媒介,便间接的建立起和之前所有时刻的变量的相关性,这样在仍然只需要计算一个发射概率的同时,却大大增加了变量之间的相关性,达到了我们的目的!并且,此时的观测变量之间并不存在任何的马尔科夫性,从图中我们也可以看出,每个方块之间并没有箭头相联系!
下面正式进入我们今天要介绍的第一个task:隐马尔科夫模型的概率计算法
条件:给定模型 λ=(A,B,π)和观测序列,计算在模型λ下观测序列出现的概率
一般情况下有三种解法:1理论可行的暴力解法 2 前向解法 3 后向解法
首先介绍理论可行的暴力求解方法:
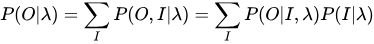
上述公式的意思就是将所有可能的长度为T的状态序列全都列举出来,然后求状态序列和观测序列的联合概率再求和!
分成了和
两部分以后再分别进行求解:
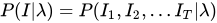
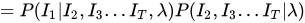
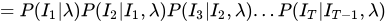 PS:这一步划简过程中用到了前面的齐次性假设
PS:这一步划简过程中用到了前面的齐次性假设
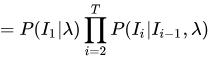
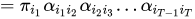
同样的:


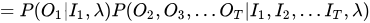 PS:这一步的划简过程应用了前面介绍的观测独立性假设
PS:这一步的划简过程应用了前面介绍的观测独立性假设
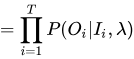
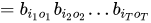
综上:
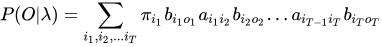
得到暴力求解的计算结果!其实得到的这个结果是非常直观的,从初始概率开始,发射概率产生观测,再继续转移,反复下去,直到产生整个观测序列!
但是这个方法也只是理论上可行,因为对于长链来水,我们没有办法从头到尾的挨个找下去。
前向算法:
首先给出前向概率的定义: 给定隐马尔科夫模型λ,定义到时刻t部分观测序列为,且状态为
的概率为前向概率,记作:
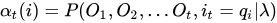
可以递推地求得前向概率及观测序列概率
通俗的说就是在时间点t时刻,已经得到的观测状态为,且t时刻对应的状态为
的概率!
具体的算法过程:
(1)初值:
(2)递推:对于t=1,2,.....T-1,

(3)终止:
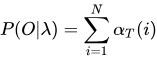
关键点在于递推的过程,可以这么理解,根据前向概率的定义的要求,最后一个时刻点的状态变量必须是,那么不管你什么从什么状态变过啦,都必须变成i状态在我这一步,而且对应的发射输出的结果是Ot+1!
这样就可以解释了前向概率,十分通俗易懂。画张图表示一下:
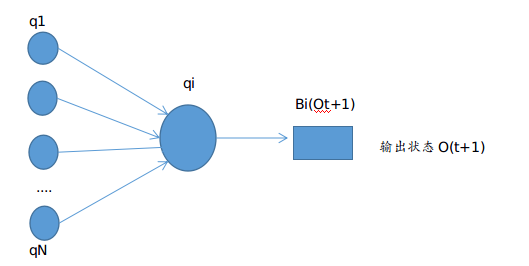
后向算法:
同样先给出后向概率的定义:给定隐马尔科夫模型λ,定义在时刻t状态为的条件下,从t+1到T的部分观测序列为
的概率为后向概率,记作:
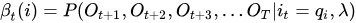
可以递推地求得后向概率及观测序列概率
后向算法的计算过程:
(1)初值:
(2)对t=T-1,T-2,......1
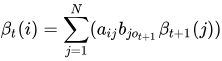
(3)终止:
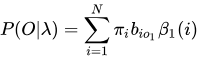
后向算法的递推过程比较有趣:
之前阅读真皮先生的博客HMM的时候,真皮先生的思路是已知是一个未来的概率,要求之前的,需要回退到隐状态上,再和转换概率相乘,就可以完成从后往前的这个变化过程,我在这里卡顿了好久,
一直不明白为什么回退到隐状态?为什么乘以发射概率就可以回退到隐状态呢?感兴趣的读者也可以先不看后面的自己思考一下
其实,由未来概率回退到隐状态上来这个思路是非常巧妙的,一开始我就是想不通,为什么这样可以回退到隐状态,后向概率明显是从后往前想,我们来仔细看后向概率的定义式:
很明显这里已知的发射状态是到t+1时刻的,并没有到t时刻,那为什么乘一个t时刻的Ot的发射概率就可以完成回退到隐状态来呢?我们来借鉴一下暴力解法当中的结论:
可以发现一个明显的连乘规律就是一个转移概率加一个发射概率之后必须再一个转移概率进行状态转移,再来一个发射概率,所以回到
我们的后向概率上来,当我们得到了时刻的状态之后,必须再和一个发射概率相乘,这样我们便可以巧妙的又回到隐状态的序列上来,只要再进行一步转移,就可以完成状态的回溯!太秒啦!
这样,这个迭代公式也可以解释的通了,得到t+1的后向概率,先乘一个发射概率,回退到状态序列之后,和所有可能得到i状态的转移概率相乘再求和,就是后向概率的迭代!
同样也用一幅图来表示,开局一幅图,文字全靠编:
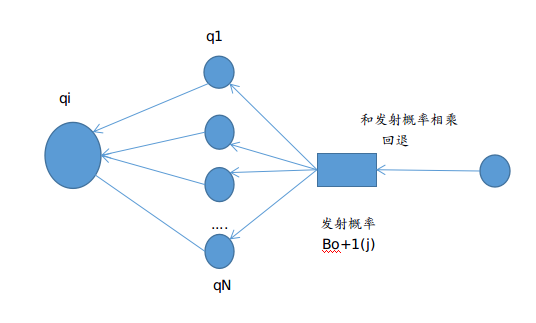
最后再送上一个神级后向概率推导公式(思路来自于真皮先生博客):
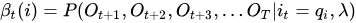
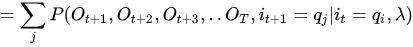
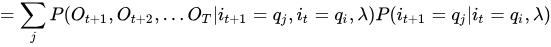
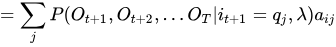
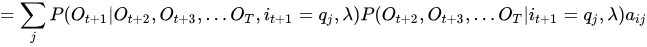

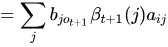
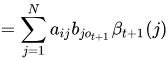
第一个问题的最后,总结一下一些概率与期望值的计算:
1 给定模型λ和观测O,在时刻t处于状态qi的概率,记作: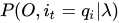 ,然后来推导一下这个公式,看看它和前向后向概率的关系:
,然后来推导一下这个公式,看看它和前向后向概率的关系:
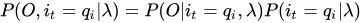
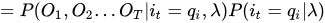
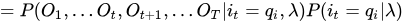 PS:从t这个地方隔断,可以慢慢感觉到前向概率和后向概率要暴露出来了!
PS:从t这个地方隔断,可以慢慢感觉到前向概率和后向概率要暴露出来了!
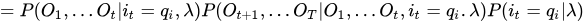
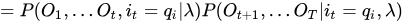 这一步我当时也没看懂是什么骚操作,我解释一下子
这一步我当时也没看懂是什么骚操作,我解释一下子
三式连乘,把第一个和第三个结合成联合概率,就得到下面的第一式,第二式利用的是观测独立性假设!
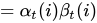
结果真是太让人意外了,竟然是前向后向概率的相乘! 别着急,还有更意外的:
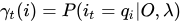

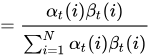
这个公式一列出来,我整个人都吓尿了,怎么数学界千丝万缕的联系的事情就这么多吗?还是数学家故意安排的邂逅?
2 给定模型λ和观测O,在时刻t处于状态qi且在时刻t+1处于qj的概率,记作: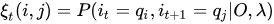
这个定义比上面那个多考虑了一个时刻,有趣
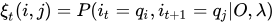
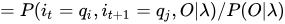
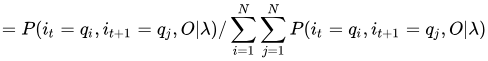
发现整个式子里就剩下这个东西了。。。。
其实给定参数和观测考虑两个时刻,就是用前向概率和后向概率巧妙的将两个时刻结合起来,如下图所示(同样来自真皮先生的博客):
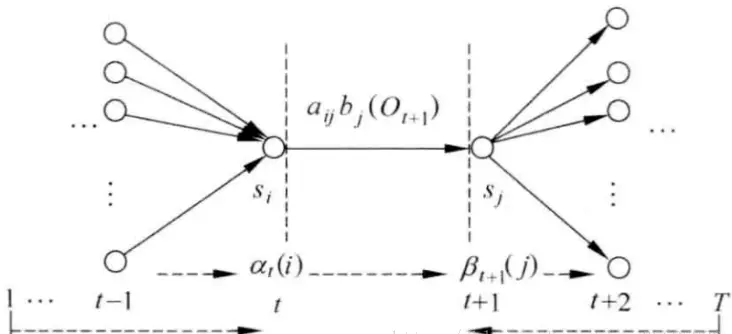
这里直接给出结论:
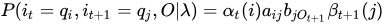
最后的结果就显而易见了!
写到这里,仅仅写完了HMM的第一部分,概率计算问题,后面还有参数模型的估计问题以及预测算法问题,简单说一下思路
参数模型的估计和我前面一篇博客 什么是EM算法?关系密切,其实仔细考虑一下,观测序列已知,直接进行参数模型的估计,其实就是我们前面讲的EM算法,写出Q函数,然后带进去,利用暴力求解的方法
得出的结论,然后继续往里带,再就是利用拉格朗日乘子法根据已知的限制条件,将拉格朗日乘子根据求导的方法求出来,回带进去,基本上就可以将三个最大化的参数毫无保留的求出。
至于预测算法的问题,其实就是根据概率最大化原则选择最优的最可能的路径,将概率最大的筛选出来,然后反向寻找路径经过的结点,这就是所谓的维特比算法,维特比算法好像在信息论与编码当中讲过
不过当时的维特比算法是用来译码,这里的维特比算法是用来求解最优路径,本质思路都是一样的,我不是很了解维特比算法,就不展开描述了,如果有时间我可以再写一篇HMM模型参数估计的博客给大家
参考,十分感谢简书真皮先生的博客,看了收获很多,也是这篇博客的灵感来源!文末附上链接,就写到这里啦,能看到这里我还是十分感谢您的,这么冗长的一篇博文,想必浪费您不少时间吧!哈哈
参考博客:https://www.jianshu.com/u/cbacf40d927f