首先,dict包含四个结构体。关系如图所示:
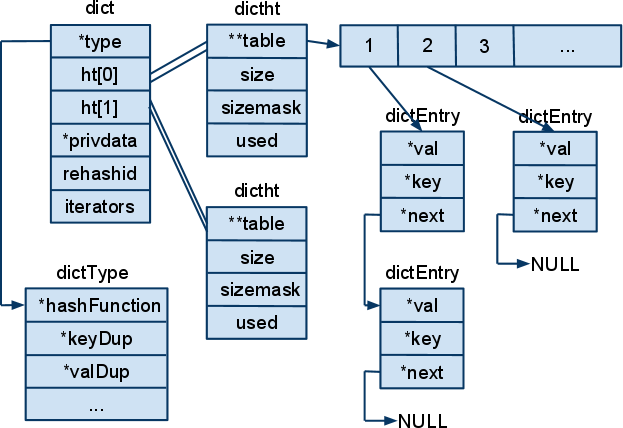
结构体dict表示一个字典。每个字典中含有两个哈希表,ht[0]和ht[1]。哈希表用结构体dictht表示。哈希表采用链表法来处理冲突。结构体dictht的成员变量size表示table的长度,通常是2的幂次。sizemask等于size减1,用于计算哈希值对应的桶。used表示table的所有桶中的dictEntry实例的个数,也就是table对应的所有链表的总长度。键值对用结构体dictEnty封装,键值对会组成一个链表。结构体dictType包含有一些函数指针,这些函数指针保存的函数用于对字典中的数据进行处理,比如dup键或值,比较键,折构键值等。最重要的是hashFunction函数,很明显,这时对键值求hash值的函数。
dict提供对字符串和整数的哈希函数。字符串哈希函数使用的是Bernstein方法,整数是Thomas Wang的方法。两个方法都简单,没什么可讲的。至于这两种方法的优劣,读者可自行google。Bernstein方法笔者在不同的程序见过很多次,想必应该是很好的方法。
下面介绍一下dict的rehash。通常情况下,所有的数据都是存在放dict的ht[0]中,ht[1]只在rehash的时候使用。dict进行rehash的时候,将ht[0]中的所有数据rehash到ht[1]中。然后将ht[1]赋值给ht[0],并清空ht[1]。dict的rehash并不是一次性完成的,而是分成多步。在调用dict的一些操作函数时,如add,find等,都会判断是否需要执行一步rehash并视情况而执行。每一步的大小分为两种,一种是在一步中将ht[0]的table中的一个元素,也就是一个哈希桶,如table[2],所对应的链表中的所有元素进行rehash,另一种是在一步中执行一段固定的时间,当时间到达后,暂停rehash。这两种方法对应的函数分别是_dictRehashStep和dictRehashMilliseconds。这两个函数调用dictRehash进行实际的rehash。dictRehash的代码如下:
1 /* Performs N steps of incremental rehashing. Returns 1 if there are still
2 * keys to move from the old to the new hash table, otherwise 0 is returned.
3 * Note that a rehashing step consists in moving a bucket (that may have more
4 * thank one key as we use chaining) from the old to the new hash table.
5 进行N步增量重哈希。
6 如果没有完成旧哈希表中所有值的重哈希,返回1,否则返回0。
7 每一步重哈希移动一整个哈希桶。
8 */
9 int dictRehash(dict *d, int n) {
10 if (!dictIsRehashing(d)) return 0;
11 while(n--) {
12 dictEntry *de, *nextde;
13
14 /* Check if we already rehashed the whole table... */
15 if (d->ht[0].used == 0) {
16 zfree(d->ht[0].table);
17 d->ht[0] = d->ht[1];
18 _dictReset(&d->ht[1]);
19 d->rehashidx = -1;
20 return 0;
21 }
22 /* Note that rehashidx can't overflow as we are sure there are more
23 * elements because ht[0].used != 0 */
24 while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
25 de = d->ht[0].table[d->rehashidx];
26 /* Move all the keys in this bucket from the old to the new hash HT */
27 while(de) {
28 unsigned int h;
29 nextde = de->next;
30 /* Get the index in the new hash table */
31 h = dictHashKey(d, de->key) & d->ht[1].sizemask;
32 de->next = d->ht[1].table[h];
33 d->ht[1].table[h] = de;
34 d->ht[0].used--;
35 d->ht[1].used++;
36 de = nextde;
37 }
38 d->ht[0].table[d->rehashidx] = NULL;
39 d->rehashidx++;
40 }
41 return 1;
42 }
结构体dict中的rehashidx变量表示当前需要rehash的桶的下标,也就是table的下标。如果rehashidx为-1,表示当前没有进行rehash。宏dictIsRehashing通过rehashidx判断是否在进行rehash。
dictRehash函数执行n步rehash。每步中,首先判断是否已经完成了rehash,判断的标准就是ht[0]的used为0。ht[0]的used为0说明table中所有的链表都是空的,那么所有的元素都已经移动到ht[1]中。此时,将ht[1]赋值给ht[0],清空ht[1]。将rehashidx赋值为-1表明rehash结束。如果rehash没有结束,那么,查找ht[0]中下一个非空的桶。将这个桶中的所有数据rehash到ht[1]中。
那么,什么时候开始rehash?首先说明一下rehash是干吗的。从前面的代码中可以看出,所谓的rehash,不管你分不分步,无非就是把数据从ht[0]中取出,重新计算hash值,然后放到ht[1]对应的桶中,然后把ht[1]变成ht[0]。读者们可以看看dictAdd代码,rehash的步骤和把数据放入ht[0]的过程没什么区别。这就比较蛋疼了,搞毛啊,穷折腾么?显然不是!在rehash的时候,ht[0]和ht[1]的table的长度是不一样的!ht[1]的table长度是ht[0]的table长度的2倍。数据对应与ht[1]的桶的下标和在ht[0]的桶的下标是不一样的。前面介绍的那两种哈希方法计算出来的哈希值通常会很大,要远大于table的长度。因此,这个哈希值与table长度进行与运算的时候,得到的值就不一样。说白了,在ht[0]中,桶下表是哈希值的低m位,在ht[1]中就是低m+1位,两个值自然极有可能不一样了。所以,rehash之后,ht[1]中链表的长度大大减少。随着数据的增加,ht[0]中的链表会越来越长,这会造成查找效率降低。为了降低链表的长度,要加大桶的长度。在dictAdd函数中,调用_dictKeyIndex函数。_dictKeyIndex函数查找新的key所对应的桶的下标。_dictKeyIndex函数调用_dictExpandIfNeeded函数判断是否需要扩充ht[0]的table。_dictExpandIfNeeded函数调用dictExpand函数进行实际的扩充。dictExpand函数的代码如下:
1 /* Expand or create the hashtable */
2 int dictExpand(dict *d, unsigned long size)
3 {
4 dictht n; /* the new hashtable */
5 unsigned long realsize = _dictNextPower(size);
6
7 /* the size is invalid if it is smaller than the number of
8 * elements already inside the hashtable */
9 if (dictIsRehashing(d) || d->ht[0].used > size)
10 return DICT_ERR;
11
12 /* Allocate the new hashtable and initialize all pointers to NULL */
13 n.size = realsize;
14 n.sizemask = realsize-1;
15 n.table = zcalloc(realsize*sizeof(dictEntry*));
16 n.used = 0;
17
18 /* Is this the first initialization? If so it's not really a rehashing
19 * we just set the first hash table so that it can accept keys. */
20 if (d->ht[0].table == NULL) {
21 d->ht[0] = n;
22 return DICT_OK;
23 }
24
25 /* Prepare a second hash table for incremental rehashing */
26 d->ht[1] = n;
27 d->rehashidx = 0;
28 return DICT_OK;
29 }
dictExpand首先调用_dictNextPower函数来计算比size大的下一个2的次幂。然后,分配一个新的哈希表。如果此时ht[0]的table是NULL,那么说明这是第一次调用dictExpand函数,也就是第一次向dict插入数据,直接将新的哈希表赋值给ht[0]。如果不是,那么新的哈希表赋值给ht[1]。注意,此时rehashidx被赋值为0,这就表明下面要开始rehash了。在dictAdd,dictFind和dictGenericDelete中分别在开始的时候调用了_dictRehashStep 。这三个函数也是被频繁调用的函数。
由于rehash不是一次完成的,因此,在对dict进行操作的时候,数据会分布在ht[0]和ht[1]中。对于dictFind,dictDelete等函数,遍历两个表即可。但是,对于dictAdd函数,需要一些特殊的操作。如果此时在进行rehash,那么数据应该被插到ht[1]中,而不是ht[0]中。如果插到ht[0]中,倘若此时还没有对数据所在的桶rehash,那么随后的rehash中也会把数据移动到ht[1]中。如果此时已经对其所在的桶rehash过了,那么在dictExpand的第一个while语句中会出现数组越界的情况,很有可能造成程序崩溃。dictAdd调用_dictKeyIndex来计算key对应的桶的下。如果处在rehash中,得到的是在ht[1]中的下标,否则是在ht[0]中的下标。
redis的dict提供了一个迭代器。由于rehash的存在,如果不加保护,某写数据可能会被返回两次。比如,一个数据e在ht[0]中,此时还没有对e所在的桶进行rehash,迭代器访问完e之后,恰好对e所在的桶进行了rehash。那么,当迭代器遍历ht[1]中的时候,e会被再次返回。为了防止这种现象,redis限制一旦有迭代器对dict进行访问,那么rehash就会暂停,直到不再有迭代器访问字典。结构体dict中的iterators用于记录当前正在访问字典的迭代器。可以有多个迭代器同时访问字典。迭代器返回的数据可以被删除。迭代器通过记录数据的指针和其在链表中的后继数据的指针实现对删除的支持。
redis限制有迭代器访问的时候禁止rehash,但是,在rehash的过程中迭代器可以随时对字典进行遍历。一旦有迭代器遍历字典,rehash就会暂停直到遍历结束。迭代器也会根据当前是否在进行rehahs来判断是否需要访问ht[1]。