在日常的规划应用中,无论是APS,VRP还是排班场景,有两个极其常见的需求,分别是批量规划和实时规划。下面我们对这两种情况作更深入探讨。
批量规划
顾名思义,该功能是指规划程序可批量地、且行地处理同一规划模型的多个数据集,从而提高规划效率,包括计算资源(CPU,内存等)和时间(将多个需要长时间运算的数据集安排在夜间进行)。此外,批量规划必然是异步运算,基于此特性,在一些计算频率不同的场景,可实现多个计划单位共用一个规划服务。例如同一集团内的多个工厂或车间,只需要部署同套规划服务,作为这些车间的共用基础设施,从而提升APS项目的ROI. 因为引擎是批量地异步地执行规划运算的,因此,各个工厂只需将自己的规划数据集提交到规划服务中,服务程序完成规划运算后,规划结果返回到对应的WebAPI,或写入相应的数据源即可,工厂与工厂之间的规划时间无需排队。关于批量规划的实现,在OptaPlanner刚推出SolverManager可实现批量规划时,本人曾写过一篇简介文章:OptaPlanner 7.32.0.Final版本彩蛋 - SolverManager之批量求解
而OptaPlanner在进入8.X版本后,对SolverManager的相关接口作了一些修改,改进了一些接口,以提高合理性与易用性。
通过SolverManager实现批量、并行规划
如下代码中,实现了一个更为简洁的通过SolverManager实现批量规划的步骤。该代码片段将一个待规划的数据集(problem)通过一个SolverManager对象的solve方法提交后,线程会马上返回,其返回值是一个SolverJob对象,SolverJob是一个泛型类,类型分别是Solution类和一个用于标识当前传入Problem的引用类型值,可以使用UUID或Long来标识不同的规划数据集。SolverJob事实上就是在SolverManager对多个数据集进行批量并行运算过程中的一个句柄,通过这个句柄就可以实现对相关的规划对象进行访问和控制,包括下一篇中用到的实时规划。
package org.acme.schooltimetabling.rest; import java.util.UUID; import java.util.concurrent.ExecutionException; import javax.inject.Inject; import javax.ws.rs.POST; import javax.ws.rs.Path; import org.acme.schooltimetabling.domain.TimeTable; import org.optaplanner.core.api.solver.SolverJob; import org.optaplanner.core.api.solver.SolverManager; @Path("/timeTable") public class TimeTableResource { // 定义一个SolverManager对象 @Inject SolverManager<TimeTable, UUID> solverManager; @POST @Path("/solve") public TimeTable solve(TimeTable problem) { // 创建一个UUID值作为规划数据集的ID,也可以替换成Long, Sting等,但所提交给SolverManger的各个problem,其ID不可重复。 UUID problemId = UUID.randomUUID(); // 将待规划数据集(problem)提交给SolverManger,并开始规划。 // 将数据集提交到SolverManager之后,是否被即时执行规划运算,要视当前设置的并行线程数,及当前规划空间中正在运行的数据集数量有关。 // SolverManger的solve方法返回一个SolverJob对象,它是一个规划进程的句柄,通这它可以对相应的数据集进行控制,其泛型与SolverManager一致。 SolverJob<TimeTable, UUID> solverJob = solverManager.solve(problemId, problem); TimeTable solution; try { // 通过solverJob获得对应数据集的最终解, // 注意:getFinalBestSolution方法需要在对应数据集的规划进程结束(可以是提前结束,也可以是达到Termination条件满足而结束)后才能获得最终解 solution = solverJob.getFinalBestSolution(); } catch (InterruptedException | ExecutionException e) { throw new IllegalStateException("Solving failed.", e); } return solution; } }
实现可批量、并行运算的规划服务
通过SolverManager的运行机制,我们利用OptaPlanner相关的特性实现一个可批量、并行运算的规划服务,服务对规划请求的响应过程如下。当然就是没有SolverManager,我们自己通过Java的并行计算功能,也可以实现批量处理,但需要我们自行处理好Java并行计算的相关问题。
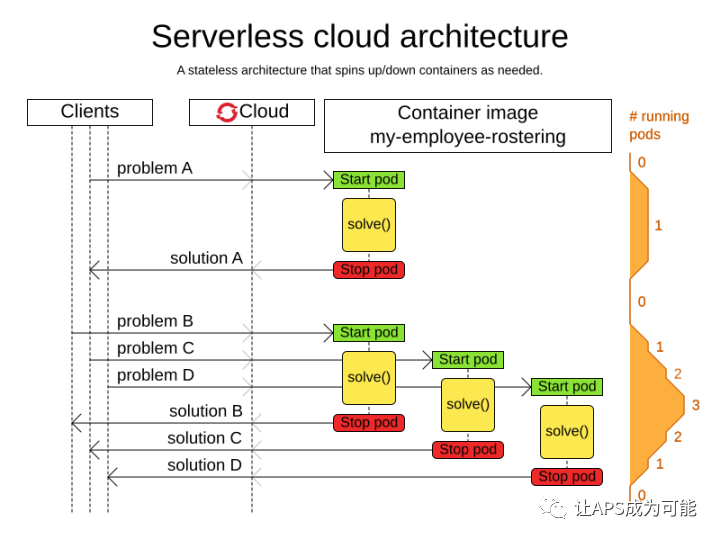
从上图可以看到,客户端的规划请求发送到规划服务后,规划服务会为每个请求的数据集开启一个solve线程,并在规划运算完成后将结果返回,当请求有重叠时,服务端会对这些数据集作并行运算,并在完成运算后各自返回。
我们只需在应用OptaPlanner的服务后台逻辑中,应用好SolverManager及其相关功能,即可实现内置的批量、并行规划运算。而将这些功能设计成后端服务,并以Web API方式呈现作为各种场景下的基础规划设施,其实就是J2EE的内容的,大家可以自行参考相关的材料。
批量规划目前的不足
通过批量、并行规划,可以实现同一个模型的多个数据集同时进行规划运算。但有同学应该会想到,不同工厂有可能规划数据集的数据量相差很大;或者不同时间(淡季旺季)因为生产任务量不同,规划数据集的数据量也会有所差异。不同的数据量展开后的问题规模差异可能是相当惊人的,从而导致所需的规划时间差异极大。那么,在批量规划的过程中,能否为不同的数据集设定不同的规划时间呢?很遗憾,OptaPlanner目前是不支持该功能的。这是一个相当实在的问题,希望OptaPlanner以后的版本可以支持。以下是OptaPlanner团队关于该问题的答复。
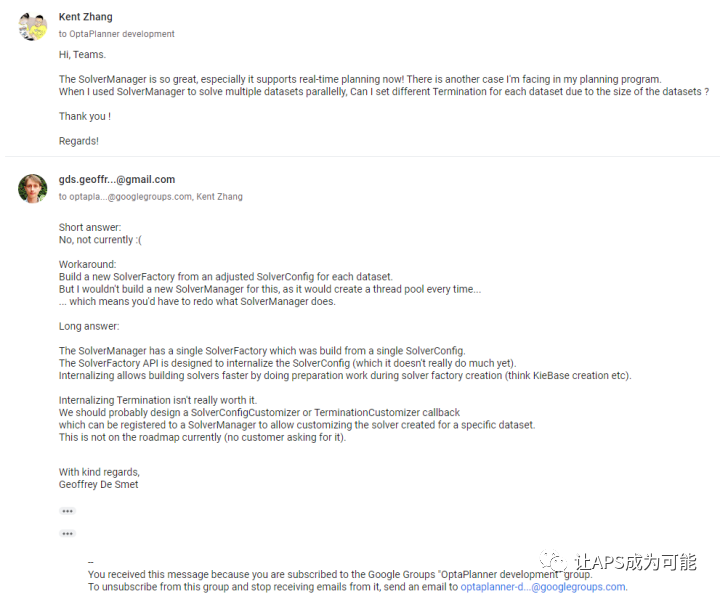
实时规划
实时规划则与具体的规划业务关系更强。根据业务具体要求来决定是否需要实时规划。在绝大多数的规划应用场景中,计划是一种持续性、连贯性的工作,即前后两个计划周期存在一定承接要求。通常上一个周期的执行结果,作为下一周期计划输入内容的其中一部分。因此,相邻两个计划之间的衔接存在一定的复杂度,并需要一定的设计才能切实反映实际的计划情况。之前本专栏有一篇关于两个相邻计划之间衔接的文章,提出了一些方案可参考:相邻两个生产计划之间的衔接问题
实时规划需求的来源
常言道 - “计划永远不如变化快”,要实现前后两个周期性计划的接续,除了使用上文中提到的一些技术手段(例如设置锁定区)外,还可以换一个角度思考。既然周期性计划存在连贯性问题难以处理,那么我们能否直接把这个周期取消,不区分计划的生成时间与执行时间,而是直接让引擎在整个计划过程中都处于待命运行状态?实现计划跟随变化?实时计划技术就是为实现此理论而提供。本文将介绍实时计划的相关适用场景、设计及实现方法。事实上从具体的业务出发,无论是周期性计划还是实时计划,都需要任务进行锁定的,原因何在?大家可以在评论区讨论。就是因为"计划 - 执行 - 反馈 - 再计划..."是一个持续的、连贯的过程,因此,若存在一种技术可无限接近这种需求,那就能很大程度上解决上述过程中前后计划之间因时效性差异导致的各种问题。
实时规划的定义
在规划运算进行过程中,当被规划的对象(包括规划实体对象和问题事实对象)发生变化,引擎可实时地将这种变化纳入规划范围,并在当前规划结果的基础上快速输出变化后的新的解决方案。OptaPlanner称之为实时规划。例如:在生产计划的场景中,规划程序在规划运算过程中,出现紧急插单需要即时处理,新插入的订单提交到规划服务后,规划程序会即时基于现有的规划结果,将新的订单纳入考虑后,输出一个新的结果。删除订单、机台突发停机等情况亦然。又如在VRP场景中,当一位司机根据规划好的运输计划执行运输任务时,中途遇到堵车等不可预见情况(引擎在进行规划运算时,会预设所有路线都处在一个理想路况),可通过手机APP将当前情况反映到服务器,VRP规划服务程序会即时变更当前路线的路况(例如将该路线修改为不可用,或延长途经时间),引擎将该变更纳入考虑后,输出一个新的行驶方案,并更新司机的手机上。这个过程需要具备实时性,且所产生新的运输计划影响程度降到最低,至少其它没有出现异常情况的司机尽可能不受影响。以下用一个VRP示例讨论各个不同阶段出现新的访问节点,通过OptaPlanner的实时规划进行应对的情况。
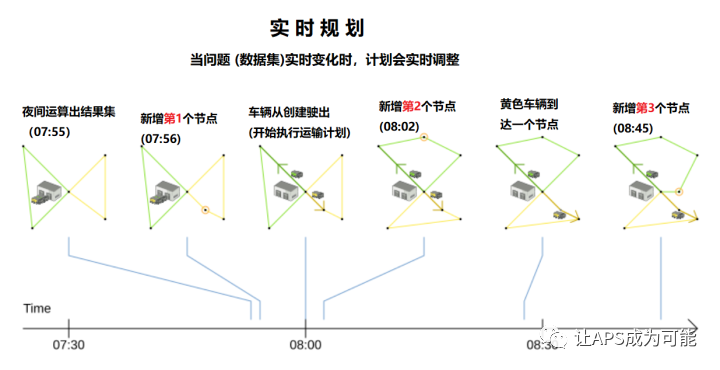
上图展示的示例中,原始的数据集规划于07:55生成计划后,又增加了3个新的客户(即3个节点),增加时间分别是07:56, 08:02 及 08:45, 且某些节点增加时,车辆已离开仓库,即计划已进入执行状态,例如新增的第2,3个节点。在VRP场景中,规划服务会在车辆上班开始执行运输作业之前,生成一个行驶路径方案。但订单会不定时新增进来,每增加一个订单,即表示运行图上需要添加一个访问点,当一个运输计划已经生成了,这个节点才添加进去,在传统的规划模式下,需要将新的节点纳入规划数据集中,将所有节点的车辆分配,及车辆的行驶路径重置,重新跑一次VRP规划,生成一个新的运输计划。但通过实时规划技术则不需要重新将所有节点重新运行,仅需对新增的节点,实时地进行增量规划即可。
实时规划的实现
在具体的工程实践中,实时规划是一种非常实用的技术,对于一个求解器,就算没有开箱即用的功能来支持该种工作方式,到了具体应用场景中,也需要通过系统设计的办法来实现该种场景。Cplex, Gorubi, OR-Tools等求解器是否支持实时规划,本人并未深入研究过,暂不好下定论。而OptaPlanner已提供了完整的内置功能,专门用于实时规划情况。在之前发布的一篇关于机械师调度的文章中,详细描述了实时规划的过程和应用场景:机械师实时调度示例(I) - 实时规划关于实时规划在OptaPlanner 8.x之后,有了更为合理、好用的API,由于篇幅所限,将在下篇介绍。本文先介绍一下实时规划如何应用在规划服务中。下图显示了实时规划服务的请求 - 处理 - 响应过程
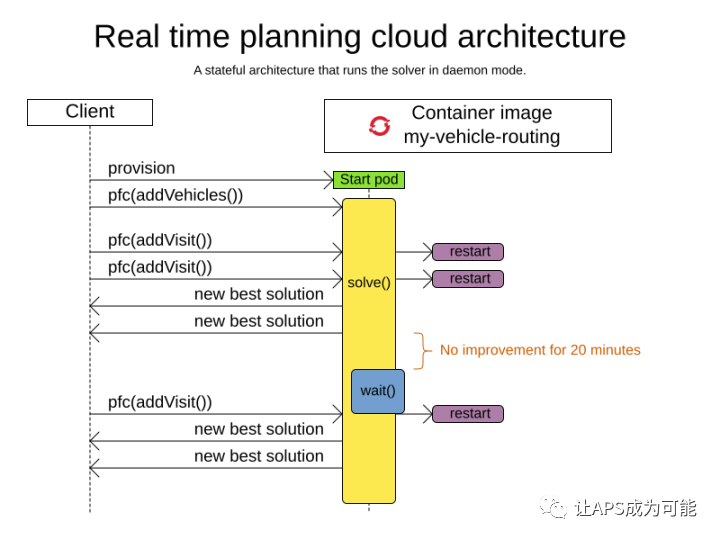
实时规划开始时,引擎会先启动一个规划进程,该进程属于留驻内存的守备进程,启动后处理待命状态。当有一个数据集传入时,进行对该数据集进行规划运算,在此过程中,通过对bestSolutionChanged事件的侦听来获取规划结果。当进程符合结束条件时,引擎将会停止运算,回到待命过程。无论是在运算过程还是待状态,当一个数据集有变更时,通过ProblemFactChanged接口(旧版本使用,新的版本将会整合到一个新的接口)接收变更,并触发引擎处理此变更。上图可清晰以反映上述过程。