一、
1.增加,更改,删除 列属性
alter table SC add test1 varchar(10) --增加列
alter table SC alter column test1 int --更改列
alter table SC drop column test1 --删除列
sp_rename 旧名,新名
2.创建唯一索引
create unique index stusno on student(SNO)
3.删除索引
drop index student.stusno
4.创建视图
create view cs_student
as
select * from student
5.in可以用select查询出来的结果做为取值范围
update SC set GRADE=GRADE+2 where CNO in (select CNO from course where CNAME='数据结构' and TNO in (select TNO from teacher where TNAME='张星'))
sco_degree > any[all] (select sco_degree from Score where cou_id='3-245')
6.去掉重复值的关键词
distinct
7.sql查询语句去除重复列(行)
参考资料:https://blog.csdn.net/danuo2011/article/details/79939385
8.sql server的case判断语句
case when 判断语句 then 结果 end


select ct.cid,ct.Cname, SUM(case when sc.score<=100 and sc.score>85 then 1 else 0 end) as [100-85], SUM(case when sc.score<=85 and sc.score>70 then 1 else 0 end) as [85-70], SUM(case when sc.score<=70 and sc.score>60 then 1 else 0 end) as [70-60], SUM(case when sc.score<=60 and sc.score>0 then 1 else 0 end) as [60-0] from SC inner join course as ct on sc.Cid=ct.Cid group by ct.cid,ct.Cname order by ct.Cid
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
.........
WHEN 条件N THEN 结果N
ELSE 结果X
END
select GRSDS=( case when zggz.YFGZ<=1200 then 0 when zggz.YFGZ>1200 and zggz.YFGZ<=2400 then (zggz.YFGZ-1200)*0.02 else (zggz.YFGZ-1200)*0.05 end ) from ZGGZ
SELECT s.s_id, s.s_name, s.s_sex, CASE s.s_sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '其他' END as sex, s.s_age, s.class_id FROM t_b_student s WHERE 1 = 1
9.rank函数,算排名名次
RANK() over(order by 列名 desc) as 重命名
10.查询 1990 年出生的学生名单
select * from student where YEAR(student.Sage)='1990'
11.sql语句的备注说明关键词 ‘ - - ’,两个横杠
12.时间的加减
参考资料:https://www.cnblogs.com/kaxbk/p/3807641.html
13.获得当前时间
getdate()
create table test1( id int, name char(10), createTime datetime default getdate() ) select * from test1 insert into test1(id,name) values(1,'ken') insert into test1 values(1,'ken2','2000-8-9') insert into test1 values(1,'ken3',null) insert into test1 values(1,'ken4',GETDATE())

14.year和month函数返回值是int
select year(GETDATE())
select month(GETDATE())
15.为每行记录依次标记一个返回值(从1开始),此函数必须跟上某列的排序语句
ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)
其中PARTITION是以COLUMN1为分组
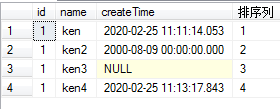
例子1:select *,ROW_NUMBER()over(order by name) as 排序列 from test1
16.数据库的备份和还原,定时备份,SQLService代理(定时作业)
参考资料:https://www.cnblogs.com/zfylzl/p/9869409.html
定时作业详细介绍参考资料:https://blog.csdn.net/qq_34590413/article/details/79127419
17.语法分析器SQL Service Profiler
参考资料:https://blog.csdn.net/qq_22698657/article/details/81671360
18.触发器
参考资料1:https://blog.csdn.net/suntao1995/article/details/88864575
参考资料2:https://blog.csdn.net/legendaryhaha/article/details/80368114
语法:
CREATE TRIGGER trigger_name
ON table|view
FOR|AFTER|INSTEADOF [DELETE][,INSERT][,UPDATE]
AS
Sql_statement[…n]
实例资料:https://www.cnblogs.com/julinhuitianxia/p/6823011.html
19.存储过程
参考资料:https://jingyan.baidu.com/article/a65957f44a4c7064e77f9b61.html
参考资料2:https://www.cnblogs.com/lihuiqi/p/10471740.html
实例资料:https://www.jianshu.com/p/abab22348e55
19.1 无参存储过程的创建及调用
create procedure getallmsg
as
select * from presonMSG3
exec getallmsg --调用存储过程
19.2 更改及删掉
alter procedure getallmsg
as
select 姓名,电话,身份证号 from presonMSG3
exec getallmsg
drop procedure getallmsg
19.3 单个参数的存储过程
create procedure searchName(@Name nvarchar(255))
as
select * from presonMSG where 姓名=@Name
exec searchName '牛坤'
19.4 多个参数的存储过程
create procedure insMSG(@stu_id varchar(3),@stu_name varchar(20),@stu_sex varchar(2), @stu_birthday datetime,@stu_class varchar(5)) as insert into student values(@stu_id,@stu_name,@stu_sex,@stu_birthday,@stu_class) exec insMSG '109','ken','男','2087-08-09','2098'
20.事务(sql语句的操作,开始,提交,回滚)
参考资料:https://blog.csdn.net/legendaryhaha/article/details/80550180
set XACT_ABORT off --如果产生错误自动回滚 GO begin tran insert into student values('102','ken','女','2087-08-09','90022') insert into student values('102','ken',男,'2087-08-09','90022') commit tran
21.删除重复记录,只保留一条
参考资料:https://www.cnblogs.com/monogem/p/11149578.html
select * from presonMSG2 where 身份证号 in( select 身份证号 from presonMSG2 group by 身份证号 having COUNT(身份证号)>1) delete t from ( select *,ROW_NUMBER()over(partition by 身份证号 order by 身份证号) as No from presonMSG2 ) as t --为presonMSG2增加一列按身份证号排序的列,重命名为t, where No>1
22.跨数据库的多表链接
参考资料:http://www.itfarmer.com.cn/743.html
23.算周的函数
select datepart(参数,datetime)
示例: select datepart(week,getdate()) 判断今天为本年第几周
参数部分如下:
year 将返回日期的年份
quarter 将返回日期在年内的第几季
month 将返回日期的月份
dayofyear 将返回日期在年内的第几天
day 将返回日期在该月的第几天
week 将返回日期在年内的第几周
weekday 将返回日期在周内的第几日
Hour 将返回日期的小时部分
minute 将返回日期的分钟部分
second 将返回日期的秒钟部分
参考网址:https://www.w3school.com.cn/sql/func_datepart.asp
24.with as 语句
参考网址:https://blog.csdn.net/qq_41080850/article/details/94557852
参考网址2:https://www.cnblogs.com/wohenxinwei/p/9649900.html
参考网址3:https://blog.csdn.net/liufeifeinanfeng/article/details/83006713
25.将数据库兼容模式设置为90
ALTER DATABASE 数据库名字
SET COMPATIBILITY_LEVEL = 90
26.convert函数: 转换数据类型
CONVERT(VARCHAR(19),GETDATE())
参考资料:https://www.w3school.com.cn/sql/func_convert.asp
27.Sql Server 查询今天,昨天,近七天....数据
参考地址:https://www.cnblogs.com/Aotum/p/10155403.html
28.CONVERT() 函数是把日期转换为新数据类型的通用函数。
CONVERT(data_type(length),data_to_be_converted,style)
参数网址:https://www.w3school.com.cn/sql/func_convert.asp
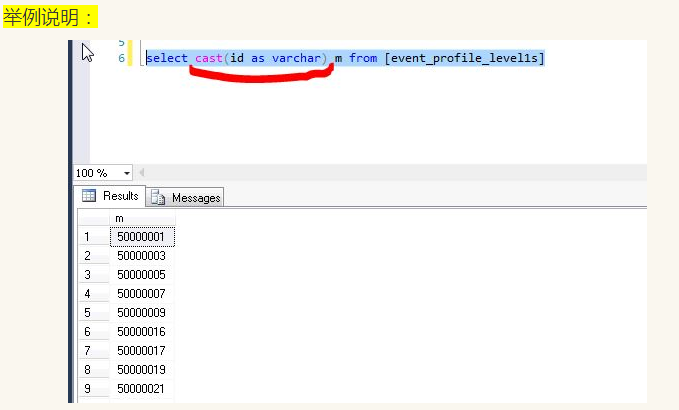
29.CAST (expression AS data_type)
参数说明:
expression:任何有效的SQLServer表达式。
AS:用于分隔两个参数,在AS之前的是要处理的数据,在AS之后是要转换的数据类型。
data_type:目标系统所提供的数据类型,包括bigint和sql_variant,不能使用用户定义的数据类型。
30.decimal
decimal(m,n)的意思是m位数中,有n位是小数,即m-n位整数。
上述实例decimal(5,2)的意思是三位整数和两位小数
31.isnull
isnull(参数1,参数2),判断参数1是否为NULL,如果是,返回参数2,否则返回参数1
32.DATEDIFF()
DATEDIFF()函数返回两个日期之间的时间差值()
语法:DATEDIFF(datepart,startdate,enddate)
例子:DATEDIFF(day,'2008-12-30','2008-12-29') 相差一天
33.通过列名找到所在的表
参考资料:https://www.cnblogs.com/zhangchenliang/archive/2010/02/02/1662142.html
select a.name 表名,b.name 列名 from sysobjects a,syscolumns b where a.id=b.id and b.name='字段名' and a.type='U'
34.服务器A访问服务器B的数据库
参考链接:https://blog.csdn.net/archer119/article/details/79552609 调用表
参考链接:https://www.cnblogs.com/freeliver54/p/3517159.html 存储过程中调用
35.索引
① 基础知识:https://www.cnblogs.com/zhaoshujie/p/10262119.html
以下是索引创建的规则:
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
以上是一些普遍的建立索引时的判断依据。一言以蔽之,索引的建立必须慎重,对每个索引的必要性都应该经过仔细分析,要有建立的依据。因为太多的索引与不充分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
② 周浩提供的课件资料学习
5.3 图书管理数据库查询的优化(73页)
L5.2 图书管理数据库视图(96页)
L5.3 图书管理数据库查询的优化(98页)
L7.1 存储过程、触发器的基本说明(129页,141页,142页)
11 数据库操作自动化应用实践(221-231页)
附录B 全局变量和常用函数(299)
36.查看数据库的空间使用情况
USE 你的库名; GO -- 数据库空间使用情况 EXEC sp_spaceused; -- 查下文件空间使用情况 SELECT file_id, name, [文件大小(MB)] = size / 128., [未使用空间(MB)] = (size - FILEPROPERTY(name, N'SpaceUsed')) / 128. FROM sys.database_files -- 表空间使用情况 DECLARE @tb_size TABLE( name sysname, rows int, size varchar(100), data_size varchar(100), INDEX_size varchar(100), unused_size varchar(100) ); INSERT @tb_size EXEC sp_msforeachtable ' sp_spaceused ''?'' ' SELECT * FROM @tb_size 用上面的语句检查一下你的数据库中的空间使用情况 其中,文件空间情况中的未使用空间表示你的文件可以通过 DBCC SHRINKFILE 来释放的磁盘空间 如果可以释放的空间很小, 那么你可以通过后面的查表空间的语句来查到是那些表占用了大的空间, 对于 unused_size 列的值很大的表, 你可以通过 REBUILD 聚焦索引(一般是主键) 的方式, 重组表的数据存储, 以便能够释放空间占用