目录
学习资料
《Java并发编程艺术》第11章
1.生产者消费者模式
生产者和消费者模式是通过一个容器(阻塞队列)来解决生产者和消费者的强耦合问题。通过阻塞队列来进行通信。(生产者—>阻塞队列—>消费者)
大多数设计模式,都会找一个第三者出来进行解耦,如工厂模式的第三者是工厂类,模板模式的第三者是模板类。
示例代码:(处理邮件)
...
public void extract() {
logger.debug("开始" + getExtractorName());
long start = System.currentTimeMillis();
// 抽取所有邮件放到队列里 (生产者线程+阻塞队列,单个线程)
new ExtractEmailTask().start();
// 把队列里的文章插入到Wiki (消费者线程+阻塞队列,线程池创建多个线程)
insertToWiki();
long end = System.currentTimeMillis();
double cost = (end - start) / 1000;
logger.debug("完成" + getExtractorName() + ",花费时间:" + cost + "秒");
}
...
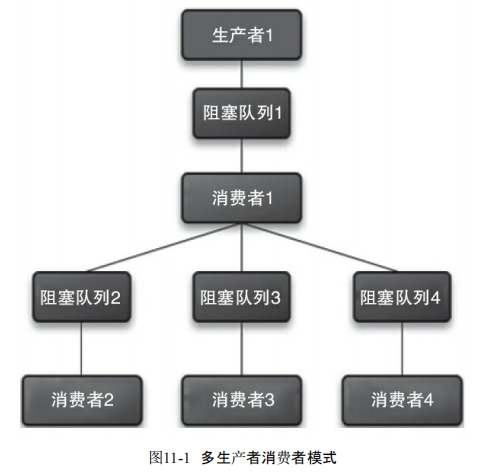
多生产者多消费者模式
可以使用多个线程来生产数据,同样可以使用多个消费线程来消费数据
更复杂的情况:(可以一个线程创建并管理子队列,由消费者1多个线程将数据存入子队列)
2.线上问题定位
线上问题定位一般流程:
-
在Linux命令行下使用TOP命令查看每个进程的情况
-
再使用top的交互命令数字1查看每个CPU的性能数据
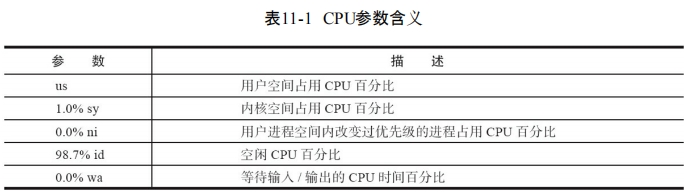
CPU参数的含义:
-
使用top的交互命令H查看每个线程的性能信息,可能出现三种情况:
- 某个线程CPU利用率一直100%,可能有死循环,也有可能是GC造成
- 某个线程一直在TOP 10的位置,这说明这个线程可能有性能问题
- CPU利用率高的几个线程在不停变化,说明并不是由某一个线程导致CPU偏高
基本处理流程:
-
第一种情况有可能是GC造成,使用jstat命令查看GC情况,是否产生Full GC:
jstat -gcutil pid 1000 5 -
可以把线程dump下来,看看究竟是哪个线程、执行什么代码造成的CPU利用率高
jstack pid > path -
dump出来的线程ID是十六进制的,而我们用TOP命令看到的线程ID是十进制的,需要转换:
printf "%x " pid然后通过得到的十六进制数找到对应的线程
3.性能测试
必须先要知道该接口在单机上能支持多少QPS,如果单机能支持1千QPS,我们需要20台机器才能支持2万的QPS,要支持的QPS必须是峰值,而不能是平均值
使用netstat命令查询有多少台机器连接到这个端口上:
$ netstat -nat | grep pid –c
查看已经使用了多少个数据库连接:
$ netstat -nat | grep 3306 –c
CPU利用率太高,可以选择升级CPU,将2核升级成4核
通过ps命令查看线程数是否增长:
$ ps -eLf | grep java -c
性能测试中使用的其他命令
-
查看网络流量:
$ cat /proc/net/dev -
查看系统平均负载:
$ cat /proc/loadavg -
查看系统内存情况:
$ cat /proc/meminfo -
查看CPU的利用率:
$ cat /proc/stat
4.异步任务池
某些场景下需要对线程池进行扩展才能更好地服务于系统:
- 程序重启了,那么线程池里的任务就会丢失
- 线程池只能处理本机的任务,在集群环境下不能有效地调度所有机器的任务
异步任务池设计图:
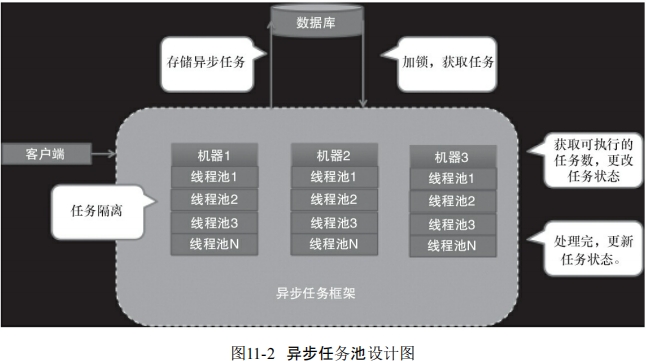
任务池的主要处理流程是,每台机器会启动一个任务池,每个任务池里有多个线程池,当某台机器将一个任务交给任务池后,任务池会先将这个任务保存到数据库中,然后某台机器上的任务池会从数据库中获取待执行的任务,再执行这个任务。
线程池任务的状态:创建(NEW)、执行中(EXECUTING)、重试(RETRY)、挂起
(SUSPEND)、中止(TEMINER)和执行完成(FINISH)
- 重试:当执行任务时出现错误,指定下一次执行时间
- 挂起:当一个任务的执行依赖于其他任务完成时,可以将这个任务挂起,当收到消息后,再开始执行
任务池
任务池的任务隔离
如果任务类型非常少,建议用任务类型来隔离,如果任务类型非常多,比如几十个,建议采用优先级的方式来隔离
任务池的重试策略
根据不同的任务类型设置不同的重试策略,主要根据实时性来判断
使用任务池的注意事项
任务必须无状态:任务不能在执行任务的机器中保存数据(如图片,数据等)
异步任务的属性
包括任务名称、下次执行时间、已执行次数、任务类型、任务优先级和执行时的报错信息(用于快速定位问题)