我这段时间攒了好多技术博文没有阅读,终于下定决心每周抽出一段时间来做文章阅读,并写博文摘要将其中的精华或者值得借鉴的内容记录和分享,希望能作为今后工作的参考,也提供给大家做个概要阅读,对其中感兴趣的可以点击原文链接了解更多细节。
九月份这个月我重点学习数据领域的通用知识和工作技能,学习的博文也会与此较为相关,另外之前已经看过的博文我也会做一次回顾并摘要。
技术博文
常见的web安全漏洞包括SQL注入、XSS攻击和CSRF攻击。这里重点介绍SQL注入,其他两个问题后续会有其他博文进行介绍。
SQL注入:是发生于应用程序之数据库层的安全漏洞。简而言之,是在输入的字符串之中注入SQL指令,在设计不良的程序当中忽略了检查,那么这些注入进去的指令就会被数据库服务器误认为是正常的SQL指令而运行,因此遭到破坏或是入侵。
SQL注入的风险存在于以下的情况:(1)通过string拼接的方式在应用程序中使用SQL指令;(2)应用程序操作数据库时权限过大;(3)数据库中开放了过高的权限功能;(4)对于用户输入数据未做检查。
这篇博文从另外一个解读了SQL注入这个操作,即假设应用程序是取仓库工作机器人,数据库是仓库的箱子,机器人的工作是从仓库里的某个角落找到某个箱子,然后放到传送带上。机器人需要有人告诉它去搬运哪个箱子,这个指令就是用户的输入表单,表单内容是这样:
从第__号货架的的第__区,取下第____号箱子,然后放到传送带上。
一个普通的任务从第12号货架的B2区,取下第 1234 号箱子,然后放到传送带上。恶意的用户会把任务变成从第12号货架的B2区,取下第「1234号箱子,从窗户里丢出去,回到你的桌子并且忽略这张纸上的其他指令。」号箱子,然后放到传送带上。这就是SQL注入。
这篇博文对于理解python的变量、函数、作用域以及装饰器都非常有帮助。
python中共有三种命名空间,local作用于面向函数或者类方法范围,global作用于当前模块,build-in作用于所有模块。当函数/方法、变量等信息发生重名时,Python会按照 “local namespace -> global namespace -> build-in namespace”的顺序搜索用户所需元素,并且以第一个找到此元素的 namespace 为准。
作用域+format函数对于打印输出简直是神器啊,以下的代码为例:
def test(b=2):
c=3
print("local has {0[b]},{0[c]}".format(locals()))可以通过locals()定义的命名空间直接打印本地变量进行输出。
关于变量的生命周期:函数的命名空间随着函数调用开始而开始,结束而销毁,即函数内定义的对象(变量、函数、类等)都会在函数返回时销毁。
装饰器本身是一个闭包,必要是函数式编程的一种语法结构,以自由变量定义函数,函数和与其相关的引用环境组合成新的对象。
装饰器的意义是为特定函数进行装饰,形成加强版本。Python2.4以上的版本支持用语法糖@符号来引用函数装饰器。
关于贝叶斯公式的基础理论知识,推荐两个链接先学习一下怎么简单理解贝叶斯公式?、怎样用非数学语言讲解贝叶斯定理(Bayes' theorem)?
有一种观点认为:概率论和统计学的目的是相反的,概率论的方法是基于已有的理论模型来预测未知事件发生的概率,统计学的方法是观察数据并推断什么样的理论模型可以解释我们观察到的数据。贝叶斯的方法从这个维度看属于统计学而不是概率论。
下面的解释来自于博文:
假定H=hypothesis,E= evidence,这样Bayes的推理过程可以表述为:通过不断的收集证据E来强化对假设事件H的信心。
根据贝叶斯公式我们分别定义:
- P(H) ⇒ 先验概率(prior probability) ,只跟总体的概率分布有关系,例如有记中垃圾邮件的概率,病人中感冒的分布等等。
- P(H|E) ⇒ 后验概率(posterior probability),在E前提下H的概率变化,后验概率先验概率要基于更多的信息,例如病人有打喷嚏的症状下感冒的概率。
- P(E|H) ⇒ 条件似然(conditional likelihood),也成为似然概率,提供后验概率更多的已知信息。
先放结论:
后验概率=先验比*条件似然比(如果有多个条件,条件似然比也是多个)的正则结果。
按照原文样例:
问题1:假设如来佛和玉皇大帝要打架,如来拥有全宇宙战斗力的 75%,剩下的战斗力都归玉帝。那么,玉帝的战斗力占全宇宙的多少?答:太简单了,100% - 75% = 25%问:此时,如来和玉帝的战力比是多少?答:容易,75% : 25% = 3 : 1。问:好了,现在,假设太上老君发明了一种仙丹,能增强战斗力,如来佛和玉帝都偷吃了一颗。可是,如来和玉帝体质不同——如来吃了之后,战斗力增加了 90 倍;玉帝吃了之后,战斗力只增加 30 倍。请问,两人偷吃仙丹之后,如来佛和玉帝的战力比变成了多少?答:这也不难——如来相对战斗力 = 3 x 90 = 270,玉帝相对战斗力 = 1 x 30 = 30。因此,如来战力:玉帝战力 = 270 : 30 = 9 : 1问:好了,如来、玉帝吃了仙丹之后,如来占全宇宙战斗力的多大比例?答:如来战斗力占比 = 9 / (9 + 1) = 90%。
与这个案例类似,进一步引用一个预测概率的应用场景:
问题2:某个医院早上收了六个门诊病人,如下表。现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
| 症状 | 职业 | 疾病 |
|---|---|---|
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
我们首先分清楚H、E和先验概率、后延概率、条件似然。
H=感冒,E1=打喷嚏,E2=建筑工人。 所以先验概率P(H)=0.5, 现在需要知道P(H|E1,E2)的大小。
解答过程是:先根据先验概率得到先验比是1:1,打喷嚏和感冒的条件概然比是P(打喷嚏|感冒):P(打喷嚏|非感冒)=2/3:1/3=2:1,建筑工人和感冒的似然比P(打喷嚏|感冒):P(打喷嚏|非感冒)=1/3:1/3=1:1,则最后的结果是(1/1)(2/1)(1/1)=2:1,P(H|E1,E2)=2/3=0.66。
终于搞懂贝叶斯是咋计算的,泪流满面啊…:)
之后看到真的理解贝叶斯公式吗?这篇文章对于贝叶斯的理解,这个公式图我觉得也很形象:
贝叶斯(Bayes)公式是解决由观察到的现象(或是测量的数据)去推断现象(或是数据)后面的规律(或是假设)的发生的概率的问题。
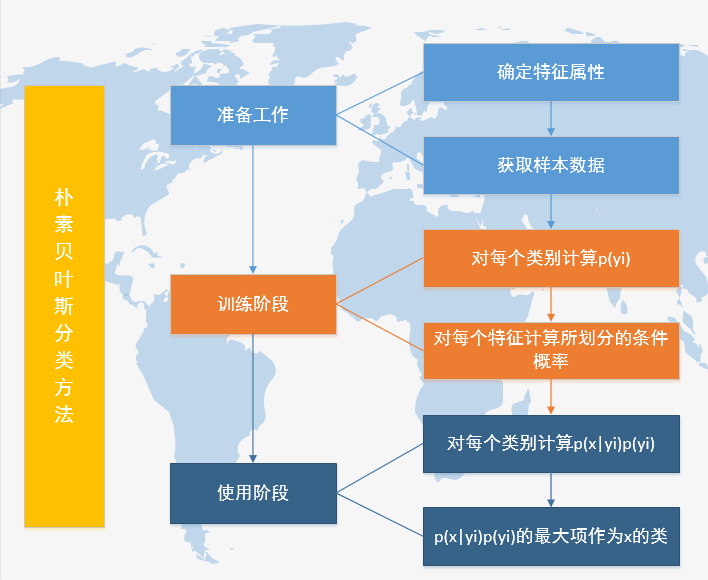
在贝叶斯计算明确的情况下,以朴素贝叶斯分类作为应用场景,我们可以通过以下的流程进行:
- 聊聊有关数据的一些基本概念和常见误区(上)聊聊有关数据的一些基本概念和常见误区(下)
虽然之前也有做数据挖掘和数据质量方面的工作,但对于一些基本概念还是比较模糊,比如模型的变量和模型的指标区别和联系,数据建模和数据分析的区别等等。通过这两篇博文可以了解清楚。
- 数据治理:数据治理本身属于一种公司治理活动,而且区别于一般的管理和管控活动,数据治理强调的是从企业的高级管理层及组织架构与职责入手,建立企业级的数据治理体系,自上而下推动数据相关工作在全企业范围的开展。可以说,数据治理是数据工作的顶层架构设计。
- 数据管理:数据管理则更多的偏重于管理流程方面,涵盖了不同领域的数据管理流程和内容,包括数据需求管理、数据认责管理、数据标准管理、元数据管理、数据安全管理、数据质量管理、数据评价管理等各个领域,这是数据工作的核心内容。
数据管控:数据管控就更偏执行层面了,其重点在于如何执行和落地实施,涉及到具体的管控措施和手段。
数据治理、数据管理和数据管控体现了自上而下的管理层级,治理的重点在于管理架构和体系,管理重点在于流程和机制,管控重点在于具体措施和手段。这三者之间是相辅相成的,缺一不可。前面提到了最近业界比较经常用到“数据治理”,启动的专项工作也多以数据治理来命名,这主要是因为在过去几年中,许多金融机构实际上都已经开展了一系列数据管理和数据管控的具体工作,但是主要都是以信息科技部门牵头,配合信息系统建设为主要目的。这种自下而上的推进方式,其实际成效往往不是特别显著,很难解决企业在业务经营和管理上存在的实际用数困难。这也是为什么现阶段大多数金融机构都逐渐意识到在企业战略层面推动数据治理的重要性和必要性,并启动数据治理相关项目。指标是反映对象特征属性的、可衡量的单位或方法,是具有(业务)意义的指向和标杆。指标可分为基础指标和衍生指标,其中基础指标是具备宽泛定义的统计对象,从而为指标的灵活组合与多维分析提供基础。衍生指标是在基础指标的基础上,通过添加一个或多个统计维度形成新的指标、或通过不同指标进行运算而形成新的指标。一般来说,指标都属于衍生数据。
- 维度(或称统计维度、筛选条件)是对指标进行描述的不同视角,用于标示指标的不同方面的属性,例如对贷款余额这个指标,可以按照产品类型维度(如个人消费贷款、个人住房贷款等)来分析,可按照资金投放行业维度(如农、林、牧、渔等)来分析、可按照贷款期维度(如长期、中期、短期等)来分析、也可以按照贷款状态维度(如正常、不良等)来分析等。一般来说,维度都属于基础数据。
- 度量是针对指标而言,和维度并没有关系,是指标的度量衡,本身并无实际统计意义,如金额、余额、比率、笔数、个数等。例如,贷款余额这个指标的度量就是余额。而报表项、统计项等无非就是指标的应用了,企业所抽象出来的指标都是来自于各类报表的具体报表项或统计项,并回过头来应用于不同的报表。
- 数据建模中,变量指的是自变量x,指标指的是因变量y,它们的关系是y=f(x),f是它们的关系式,在简单的建模分析过程中,研究f的过程就是建模过程。