类层次图
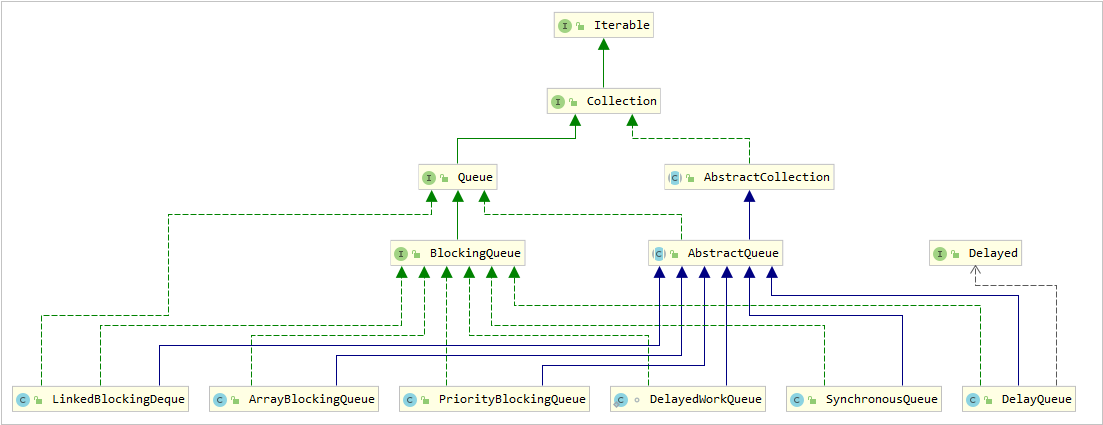
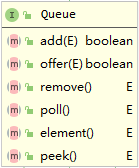
Queue
AbstractQueue

| 已实现方法 | 调用 Queue 接口方法 | 说明 | 异常类型 |
|---|---|---|---|
| add | offer | 元素入队; 但是队列有容量上限约束,队列满抛出异常 | IllegalStateException |
| remove | poll | 检索并移除队头元素; 队头为空/队列空抛出异常 | NoSuchElementException |
| element | peek | 检索队头元素; 队头为空/队列空抛出异常 | NoSuchElementException |
| clear | poll | 移除队列中的所有元素 | 无 |
| addAll | add | 把参数集合中的所有元素入队 | 无 |
小节一下:
- 所有队列都有三种操作:入队操作,出队操作,检索队首元素(但不移除该元素)。
- 队列常见的两种限制:队列容量限制,队列为空限制。
Delayed
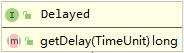
- getDelayed 方法返回对象相关的剩余延迟(本文的对象是队列)
PriorityQueue
- 容量无上限:队列支持自动扩容。队列内部包含一个容量,这个容量会随着元素的增加而增大。
- 有优先级顺序:根据成员变量 comparator 决定优先级顺序。该成员变量是在调用构造函数时赋值的。如果该成员变量为 null,则入队的元素必须实现 Comparable 接口,并按顺序进行排序。
- 入队元素有限制:入队元素不允许为 null;如果没有指定非空的 comparator,则入队元素必须实现 Comparable 接口,否则抛出 ClassCastException
- 非线程安全的:不支持多线程并发修改队列
- 数据结构与算法:使用“小根堆”,效率更高。
grow 扩容
// minCapacity 表示本次扩容后,队列内部容量至少要达到 minCapacity 这个水平
private void grow(int minCapacity) {
// 保存队列当前的容量
// 新的容量需要在老的容量 oldCapacity 基础上进行扩容
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
// 条件1:oldCapacity < 64
// 条件成立,则 oldCapacity < 64,在此情况下,容量 newCapacity = 2 * n + 2
// 条件不成立,则 oldCapacity >= 64,此时,newCapacity = 1.5 * n
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
// 如果新容量 newCapacity 超过了数组的最大值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// “拷贝-转移”的方式实现数组的扩容
queue = Arrays.copyOf(queue, newCapacity);
}
hugeCapacity
private static int hugeCapacity(int minCapacity) {
// minCapacity 转化为二进制数之后,最高位为 1,则表示负数
// 抛出内存溢出异常
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
// 条件:minCapacity > MAX_ARRAY_SIZE
// 条件成立:minCapacity > 0x7fff fff7,返回大容量 Integer.MAX_VALUE(0x7fff ffff)
// 条件不成立:minCapacity <= 0x7fff ffff 返回大容量 MAX_ARRAY_SIZE(0x7fff fff7)
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
offer 元素入队
在 PriorityQueue 中,仅有 offer 方法调用 grow。
public boolean offer(E e) {
// PriorityQueue 不允许 null 入队
if (e == null)
throw new NullPointerException();
// 每次有新的元素入队,修改版本号递增
modCount++;
// size 记录的是队列中元素的真实数量
// queue.length 则是目前的内部最大容量,即数组容量
int i = size;
// 条件:i == queue.length
// 条件成立:目前数组内已经无法容纳新加入的元素,因此必须先进行扩容
// 条件不成立:此时数组中,还有尚未赋值元素引用的空余位置,因此不扩容
if (i >= queue.length)
// 发生扩容时,希望新的容量最小为 i + 1,即 queue.length + 1,即最起码扩充一个空闲位置
grow(i + 1);
// 队列的元素真实数量新增1个
size = i + 1;
// 条件:i == 0
// 条件成立:元素入队前,元素个数为 0。也就是说,当前队列是空的,此时新入队的元素成为队头
// 条件不成立:将新入队的元素插入到数组中的空闲位置 i 处
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
siftUp
// 在位置k处插入项x
// 通过将x提升到树的上方
// 直到它大于或等于其父级或者是根级
// 从而保持堆不变。
// k 表示插入的位置,x 表示欲插入的元素
private void siftUp(int k, E x) {
// 条件:comparator != null
// 条件成立:如果构造函数中传入的是非空的 Comparator,此时根据比较器进行优先级排序
// 条件不成立:此时要求对象 x 实现 Comparable 接口。根据该接口进行优先级排序
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
siftUpUsingComparator
private void siftUpUsingComparator(int k, E x) {
// 当想要插入的位置不是根结点位置,即 k == 0
// 那么 k > 0 条件成立,进入循环体。
while (k > 0) {
// 首先,(k - 1) >>> 1 等同于 (k - 1) / 2,这样写的原因是计算机使用位移运算效率更高
// 根据小根堆堆的存储规则,从逻辑结构上看,按层次遍历的第 k 个结点,他的父结点按层次遍历是第 (k - 1)/ 2 个结点。
// 实际存储时,数组的下标也与之对应,存储在数组下标 k 位置的结点,他的逻辑父结点存储在数组下标为 (k - 1) / 2 的位置。
int parent = (k - 1) >>> 1;
// e 表示父结点元素
Object e = queue[parent];
// 条件 comparator.compare(x, (E) e) >= 0 表示拿父结点与待插入结点做比较
// 条件成立:表示欲插入的元素>=当前父结点元素
// 此时跳出循环,插入并作为当前父结点的子结点。
// 子结点,即作为父结点的左子结点或者右子结点
// 条件不成立:新插入的元素结点的值小于当前根结点
if (comparator.compare(x, (E) e) >= 0)
break;
// 父结点“下移”
queue[k] = e;
// 现在欲插入新元素的位置 k 就等于本轮中的父结点位置了
k = parent;
}
queue[k] = x;
}
siftUpComparable
private void siftUpComparable(int k, E x) {
// 将欲插入的对象 x 强转为 Comparable 接口
// 如果 x 不是 Comparable 的实现,那么会发生 ClassCastException
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
// 和上述 siftUpUsingComparator 最大的不同对比的调用方式不同
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
补习小根堆
首先,PriorityQueue 底层的数据结构是小根堆。
小根堆(Min-heap): 父结点的值小于或等于子结点的值。
注意,以下不是小根堆具有的性质:左子树上所有结点的值均小于它的根结点的值,右子树上所有结点的值均大于它的根结点的值,那是二叉排序树(Binary Search Tree)的性质,不要搞混了
大根堆(Max-heap): 父结点的值大于或等于子结点的值。

为什么 PriorityQueue 选择使用小根堆,而不是大根堆?
因为在优先队列中,priority 值越低的对象,优先级越高,需要越早出队。因此这样的对象要存放在越接近二叉树根结点的地方。
堆的存储
一般都用数组来表示堆,i结点的父结点下标就为(i–1)/2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。

由于堆存储在下标从0开始计数的数组中,因此,在堆中给定下标为i的结点时:
(1)如果i=0,结点i是根结点,无父结点;否则结点i的父结点为结点(i-1)/2;
(2)如果2i+1>n-1,则结点i无左子女;否则结点i的左子女为结点2i+1;
(3)如果2i+2>n-1,则结点i无右子女;否则结点i的右子女为结点2i+2。
数组中的数据存储顺序和逻辑完全二叉树的层次遍历的顺序一致
完全二叉树&满二叉树
小根堆和大根堆都属于完全二叉树。什么是完全二叉树呢?
先来看一下满二叉树,又称完美二叉树,英文为 Perfect Binary Tree
如果二叉树中除了叶子结点,每个结点的度都为 2。且所有叶子结点的深度相等
A Perfect Binary Tree(PBT) is a tree with all leaf nodes at the same depth.
All internal nodes have degree 2
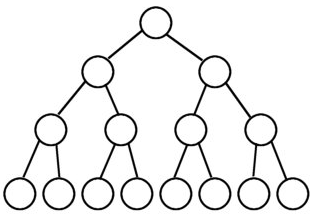
如果二叉树中除去最后一层结点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树。满二叉树也属于完全二叉树。
remove 移除元素
remove(o) 从队列中移除指定元素。
// 返回值:
// false:表示没有找到要移除的元素
// true:表示成功移除该元素
public boolean remove(Object o) {
// 查询元素o存储在数组中的下标
int i = indexOf(o);
if (i == -1)
return false;
else {
// 移除位于坐标 i 的元素
removeAt(i);
return true;
}
}
indexOf
private int indexOf(Object o) {
if (o != null) {
// 可以理解为按照顺序遍历顺序,遍历数组中的所有元素(空闲空间不会被遍历),寻找指定元素在数组中的下标
// 也可以理解为按照层次遍历顺序,访问逻辑结构——小根堆中,指定元素在小根堆中的下标
for (int i = 0; i < size; i++)
if (o.equals(queue[i]))
return i;
}
return -1;
}
removeAt
// 从队列中删除第i个元素。
private E removeAt(int i) {
// assert i >= 0 && i < size;
// 修改版本号+1,防止使用迭代器迭代时,此处的修改,导致与迭代器不一致
modCount++;
// 队列中的元素数量先减一
int s = --size;
// 移除小根堆层次遍历顺序下的最后一个元素,
// 同时也是数组中的(size - 1)位置的元素
// 此时不涉及小根堆的调整,直接移除即可
if (s == i) // removed last element
queue[i] = null;
else {
// 此时 i < s
// s 表示 (size - 1)位置的元素,即小根堆上的最后一个元素
// 用 moved 暂存小根堆上的最后一个元素
E moved = (E) queue[s];
// 移除队列中最后一个位置上的元素
queue[s] = null;
// 把暂存的最后一个元素,替代要移除的位于小根堆 i 位置上的元素
// 为了保持小根堆,moved 代表的元素可能并不能刚好保存到位置 i 上
// 有可能会被“下移”到 i 位置的子结点上面,而 i 位置的子结点中最小的元素会被“提升”到 i 位置
siftDown(i, moved);
// 条件:queue[i] == moved
// 条件不成立:(size - 1)位置的元素不能直接覆盖i位置的值,需要向下调整,发生调整后,i 位置的子树作为“小根堆”也是符合条件的
// 而 i 位置的子树原本作为整个树中的“小根堆”的一部分,也是稳定的。因此跳过 if 部分
// 条件成立:(size-1)位置的元素可以直接覆盖i位置的值,此时,i 位置的子树,作为独立的“小根堆”是符合条件的
// 但是因为 i 位置的值发生变化,整个“小根堆”有可能需要调整
if (queue[i] == moved) {
// 把 moved 元素放入到位置 i,如果出现无法保持“小根堆”的情况
// 则把 moved 元素向上提升,实际插入到比 i 要小的位置。
siftUp(i, moved);
// 条件:queue[i] != moved
// 条件成立: i-1(包括i-1)以内元素的位置没有发生改变,此时,该函数返回 null
// 条件不成立:为了保持堆不变,队列末尾的元素在放入i之后,继续与 i 之前的元素发生交换。
if (queue[i] != moved)
// 在这种情况下,此方法返回以前位于队列末尾的元素,现在位于i之前的某个位置。
return moved;
}
}
return null;
}
siftDown
// 这里采用了和 siftUp 类似的代码
// 在位置k处插入元素x
// 通过将x从树中反复降级
// 直到它小于或等于其子项或是一片叶子,从而保持堆不变。
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
siftDownComparable
private void siftDownComparable(int k, E x) {
// 强制转换对象 x 为 Comparable 接口,如果 x 无法强转,抛出 ClassCastException 异常
Comparable<? super E> key = (Comparable<? super E>)x;
// 在调用 siftDown 之前,都会先调用 --size
// 所以此时 size 表示的正是小根堆上删除的最后一个元素的位置
// 这个最后一个元素的父结点下标为 size / 2。
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
// k * 2 + 1 表示欲插入位置 k 的左结点
int child = (k << 1) + 1; // assume left child is least
// c 表示左孩子结点元素的值
Object c = queue[child];
// right 表示右孩子结点元素的值
int right = child + 1;
// 条件一:right < size
// 条件不成立:表示右结点不存在,此时左结点就是比位置 k 中孩子结点中值较小的那个。
// 条件成立:表示右结点存在,同时也说明位置 k 有左右两个孩子结点
// 条件二:((Comparable<? super E>) c).compareTo((E) queue[right]) > 0
// 条件不成立:之前的假设正确, 左结点的确是位置 k 的孩子结点中最小的一个
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
// 条件二成立:此时说明左结点的值比右结点的值大
// 右结点才是位置 k 的两个孩子结点中值最小的一个
c = queue[child = right];
// 判断条件 key.compareTo((E) c) <= 0
// key 表示要插入的元素关键字
// 条件成立:表示该关键字插入 k 位置,符合小根堆规则!跳出循环
if (key.compareTo((E) c) <= 0)
break;
// 条件不成立:关键字 key 比 k 位置的孩子结点中的最小数还要大,不符合小根堆规则,需要调整小根堆
// 此时,插入的位置要把传入参数 k 要降低。
// 传入参数 k 的较小的孩子结点被提升为父亲结点
queue[k] = c;
// 期望插入的位置 k 下降到被提升的孩子结点的位置
k = child;
}
// 把欲插入的元素 x 插入到期望位置 k
queue[k] = key;
}
poll 队首元素出队
public E poll() {
// 队列中没有元素,出队为 null
if (size == 0)
return null;
// 队列中数量减一
int s = --size;
// 防止此处调用 poll 方法,导致 iterator.remove 丢失元素
modCount++;
// 返回结果为队首元素,即下标为0的元素
E result = (E) queue[0];
// x 表示的是队列中的最后一个元素,暂存到引用 x 中
E x = (E) queue[s];
// 把小根堆最后一个元素置为空
queue[s] = null;
if (s != 0)
// 把队列中的最后一个元素,放到队首位置
// 为了保持该树仍然符合小根堆的规则,x 可能需要从树根结点降级
siftDown(0, x);
return result;
}
heapify 小根堆化
在用 Collection 作为 PriorityQueue 的构造器参数或者从反序列化方法readObject初始化 PriorityQueue 时,会调用“小根堆化”
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--)
siftDown(i, (E) queue[i]);
}
总结
优先级队列的底层数据结构为“小根堆”。为了保持小根堆,常见的调整操作包括 siftUp 和 siftDown。
- siftUp 保证的是将元素 x 存放到位置 k 时,位置 k 之前的所有元素符合小根堆的性质。
- siftDown 是为了保证将元素 x 存放到位置 k 时,以 k 为“根节点”的子树符合小根堆的性质。