section s1
offset dw str1,str2,num
section s2 align=16 vstart=0x7c00
str1 db 'hello'
str2 db 'world'
section s3 align=16
num dw 0xbad
问题:在标号 offset 处定义了三个字,请写出他们的具体数值。
答案:
| 标号 | 对应的汇编地址 |
|---|---|
| str1 | 0x7c00 |
| str2 | 0x7c05 |
| num | 0x0020 |
编译结果:

解析
在NASM中,声明一个段:
section a align=b vstart=c
- a 表示段名
- b 表示对齐的字节数
- c 表示段内汇编地址的起始地址
vstart 段内汇编地址
vstart指明段内汇编地址起始位置 该段内的汇编的地址都是从vstart开始算的。
因此,str1的具体数值等于 section s2 的 vstart,结果为 0x7c00;'hello' 共计 5 个字节,所以 str2 的具体数值为 0x7c00 + 0x5 = 0x7c05
align
首先看第一段程序:
SECTION data1
db 0x11
SECTION data2
db 0x22
SECTION data3
db 0x33
SECTION data4
db 0x44
使用NASM编译后的结果是
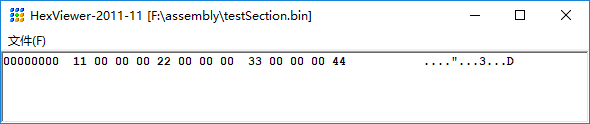
section 默认情况下是 4字节对齐 的, align 用于修改默认值
接着,修改 s3 的 align 默认值为 16
SECTION data1
db 0x11
SECTION data2
db 0x22
SECTION data3 align=16
db 0x33
SECTION data4
db 0x44
使用NASM编译后的结果变为
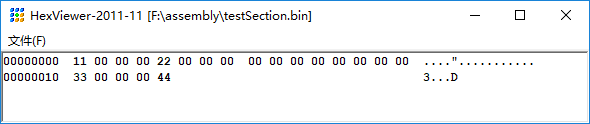
如图,因为 section data1 前面没有内容,所以加不加 align 都是一样的。
由于 section data2 没有 align,默认是 4 字节对齐,所以编译后的 bin 文件中可以看到 section data2 的起始汇编地址大于 1 (等于section data1 的起始汇编地址0x0 + section data1 的段长度0x1)且是 4 的倍数,所以汇编地址为 0x04,没有字节的地方用 0 填充对齐;
由于 section data3 是 16字节对齐,section data3 的起始汇编地址应该大于 5 (等于section data2 的起始汇编地址0x4 + section data2 的段长度0x1)且是 16 的倍数,所以汇编地址为 0x10
由于 section data4 没有 align,默认是 4 字节对齐,section data4 的起始汇编地址大于 17(等于section data2 的起始汇编地址0x10 + section data2 的段长度0x1),且是 4 的倍数,所以汇编地址为 0x14
以上均是我个人按照测试结果分析的过程,如果有错漏,欢迎指正。