《Flink执行计划第一层——StreamTransformation》 构造了列表+链表的结构;
《Flink执行计划第二层——StreamGraph》 转化第一层为图结构;
接下来,就该转化 StreamGraph 为 JobGraph 了。StreamGraph 继承了抽象类 StreamingPlan 并实现了 getJobGraph 方法:
/**
* Gets the assembled {@link JobGraph} with a given job id.
*/
@SuppressWarnings("deprecation")
@Override
public JobGraph getJobGraph(@Nullable JobID jobID) {
// temporarily forbid checkpointing for iterative jobs
if (isIterative() && checkpointConfig.isCheckpointingEnabled() && !checkpointConfig.isForceCheckpointing()) {
throw new UnsupportedOperationException(
"Checkpointing is currently not supported by default for iterative jobs, as we cannot guarantee exactly once semantics. "
+ "State checkpoints happen normally, but records in-transit during the snapshot will be lost upon failure. "
+ "\nThe user can force enable state checkpoints with the reduced guarantees by calling: env.enableCheckpointing(interval,true)");
}
return StreamingJobGraphGenerator.createJobGraph(this, jobID);
}
一、StreamingJobGraphGenerator
跟踪 createJobGraph 的代码:
private JobGraph createJobGraph() {
// make sure that all vertices start immediately
jobGraph.setScheduleMode(ScheduleMode.EAGER);
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
// defaultStreamGraphHasher 目前的实例对象是 StreamGraphHasherV2
// 会为 StreamGraph 中的每个节点生成一个Hash值
// 每个节点计算Hash时,都会拿输入节点的节点的 hash 一同参与计算
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
// 目前的遗留版本 Hash 算法实现类是 StreamGraphUserHashHasher
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes = new HashMap<>();
setChaining(hashes, legacyHashes, chainedOperatorHashes);
setPhysicalEdges();
setSlotSharingAndCoLocation();
configureCheckpointing();
JobGraphGenerator.addUserArtifactEntries(streamGraph.getEnvironment().getCachedFiles(), jobGraph);
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException("Could not serialize the ExecutionConfig." +
"This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}
遍历StreamGraph并为每个节点生成哈希值,作用主要是完整性校验,本文不做详细讨论。接下来看其他重要的方法。
2.1 setChaining
跟踪 setChaining 的源码
/**
* Sets up task chains from the source {@link StreamNode} instances.
*
* <p>This will recursively create all {@link JobVertex} instances.
*/
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes, Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes) {
// getSourceIDs() 将获取由 StreamGraph.addSource 方法添加到 StreamGraph 中的“数据源”节点ID集合
for (Integer sourceNodeId : streamGraph.getSourceIDs()) {
// 接下来将递归调用 createChain 来创建 JobVertex 实例
// 目前,hashes 中有值,legacyHashes 为空,chainedOperatorHashes 暂时也是空的,但是递归过程中会填充
createChain(sourceNodeId, sourceNodeId, hashes, legacyHashes, 0, chainedOperatorHashes);
}
}
继续跟踪 createChain 的代码:
private List<StreamEdge> createChain(
Integer startNodeId,
Integer currentNodeId,
Map<Integer, byte[]> hashes,
List<Map<Integer, byte[]>> legacyHashes,
int chainIndex,
Map<Integer, List<Tuple2<byte[], byte[]>>> chainedOperatorHashes) {
// 这个判断是为了避免重复创建 JobVertex
if (!builtVertices.contains(startNodeId)) {
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
// 把当前 StreamNode 的 outEdges 又分成了“可链接的”以及“不可链接的”,这个后面再分析
// 假如没有 outEdges,比如是“最终”节点,就不会递归调用 createChain
for (StreamEdge outEdge : streamGraph.getStreamNode(currentNodeId).getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
for (StreamEdge chainable : chainableOutputs) {
// 递归调用 createChain
transitiveOutEdges.addAll(
createChain(startNodeId, chainable.getTargetId(), hashes, legacyHashes, chainIndex + 1, chainedOperatorHashes));
}
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
// 递归调用 createChain
createChain(nonChainable.getTargetId(), nonChainable.getTargetId(), hashes, legacyHashes, 0, chainedOperatorHashes);
}
List<Tuple2<byte[], byte[]>> operatorHashes =
chainedOperatorHashes.computeIfAbsent(startNodeId, k -> new ArrayList<>());
byte[] primaryHashBytes = hashes.get(currentNodeId);
for (Map<Integer, byte[]> legacyHash : legacyHashes) {
operatorHashes.add(new Tuple2<>(primaryHashBytes, legacyHash.get(currentNodeId)));
}
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));
chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs));
// 如果 startNodeId 等于 currentNodeId,创建 JobVertex 并添加到 JobGraph,再返回 StreamConfig 对象;否则返回一个空的 StreamConfig 对象
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes)
: new StreamConfig(new Configuration());
// 在执行 setVertexConfig 之前,config 都是一个刚创建未设置的对象。
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs);
if (currentNodeId.equals(startNodeId)) {
config.setChainStart();
config.setChainIndex(0);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
config.setOutEdgesInOrder(transitiveOutEdges);
config.setOutEdges(streamGraph.getStreamNode(currentNodeId).getOutEdges());
for (StreamEdge edge : transitiveOutEdges) {
// 创建 JobEdge
connect(startNodeId, edge);
}
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
Map<Integer, StreamConfig> chainedConfs = chainedConfigs.get(startNodeId);
if (chainedConfs == null) {
chainedConfigs.put(startNodeId, new HashMap<Integer, StreamConfig>());
}
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(new OperatorID(primaryHashBytes));
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}
我们还是先来看看 isChainable(StreamEdge, StreamGraph) 的源码:
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
// 边的上游节点
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
// 边的下游结点
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
// 获取上游节点的 StreamOperator
StreamOperator<?> headOperator = upStreamVertex.getOperator();
// 获取下游节点的 StreamOperator
StreamOperator<?> outOperator = downStreamVertex.getOperator();
return downStreamVertex.getInEdges().size() == 1
&& outOperator != null
&& headOperator != null
// 检查上游节点和下游节点在同一个 SlotSharingGroup
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
// 下游节点的 StreamOperator 允许链接前置节点的 StreamOperator
&& outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
// 上游节点的 StreamOperator 允许链接后置节点的 StreamOperator
&& (headOperator.getChainingStrategy() == ChainingStrategy.HEAD ||
headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS)
// 直传
&& (edge.getPartitioner() instanceof ForwardPartitioner)
// 上游节点和下游节点的并行度相等
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
// StreamGraph 允许图中的节点的 StreamOperator 链接
&& streamGraph.isChainingEnabled();
}
其中,我最不理解的就是这个 ChainingStrategy 有什么用?所以看一下源码:
/**
* Defines the chaining scheme for the operator. When an operator is chained to the
* predecessor, it means that they run in the same thread. They become one operator
* consisting of multiple steps.
* 定义StreamOperator的链接方案。
* 当operator链接到前驱operator时,这意味着它们在同一线程中运行。
* 它们成为由多个步骤组成的一个operator。
*
* <p>The default value used by the {@link StreamOperator} is {@link #HEAD}, which means that
* the operator is not chained to its predecessor. Most operators override this with
* {@link #ALWAYS}, meaning they will be chained to predecessors whenever possible.
*/
@PublicEvolving
public enum ChainingStrategy {
/**
* Operators will be eagerly chained whenever possible.
* 立即链接
*
* <p>To optimize performance, it is generally a good practice to allow maximal
* chaining and increase operator parallelism.
*/
ALWAYS,
/**
* The operator will not be chained to the preceding or succeeding operators.
* 不和前置或者后置 operator 链接
*/
NEVER,
/**
* The operator will not be chained to the predecessor, but successors may chain to this
* operator.
* 不和前置 operator 链接,但是可以和后置 operator 链接
*/
HEAD
}
2.1.1 创建JobGraph的流程
- 经过多次递归调用,一直到“最终”节点(id=5)
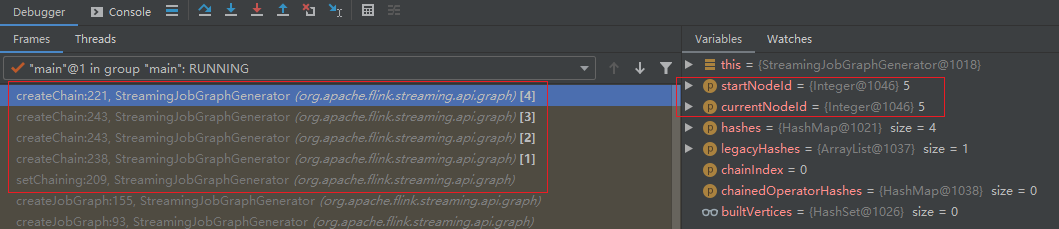
- 调用 createVertex,创建 JobVertex 并添加到 JobGraph:

- 方法栈弹出上一次的 createChain,再次执行 createVertex:

- 调用 connect 创建 JobEdge:
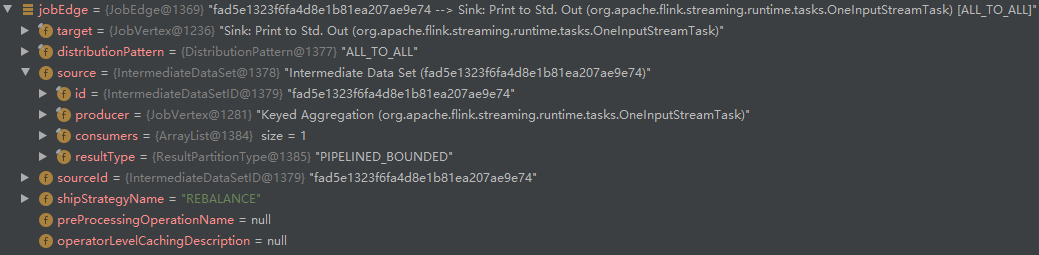
- 再次执行 createVertex,“Source:Socket Stream” 和 “Flat Map” 合并了:

- 再次调用 connect 创建 JobEdge:
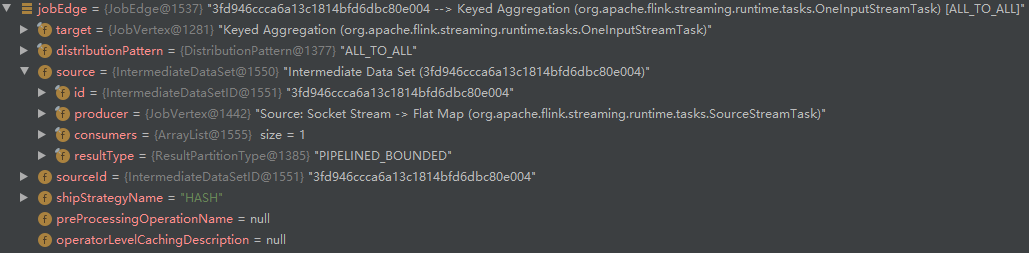
我们可以发现,JobGraph 的节点比 StreamGraph 少了一个,原因是“可链接的”的 StreamOperator 并合并了。
2.1.2 其他提问
问题一:StreamNode(id=1)和 StreamNode(id=2)合并后的名称 Source:Socket Stream->Flat Map 怎么得来的?
答:设置名称的地方是 createChain 方法内的这一句代码:
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs));
跟踪 createChainedName 的源码:
private String createChainedName(Integer vertexID, List<StreamEdge> chainedOutputs) {
String operatorName = streamGraph.getStreamNode(vertexID).getOperatorName();
if (chainedOutputs.size() > 1) {
List<String> outputChainedNames = new ArrayList<>();
for (StreamEdge chainable : chainedOutputs) {
outputChainedNames.add(chainedNames.get(chainable.getTargetId()));
}
return operatorName + " -> (" + StringUtils.join(outputChainedNames, ", ") + ")";
} else if (chainedOutputs.size() == 1) {
return operatorName + " -> " + chainedNames.get(chainedOutputs.get(0).getTargetId());
} else {
return operatorName;
}
}
调试发现,chainedNames 的映射如下:
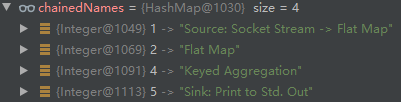
然后,在 createJobVertex 的源码中,创建 JobVertex 的代码如下:
jobVertex = new JobVertex(
// 根据 StreamNode 的 id 查询 chainedNames 映射,确定赋值名称
chainedNames.get(streamNodeId),
jobVertexId,
legacyJobVertexIds,
chainedOperatorVertexIds,
userDefinedChainedOperatorVertexIds);
问题二:JobVertex 中的属性 OperatorIDs 的来源?
首先,跟踪 JobVertex 的构造函数:
public JobVertex(String name, JobVertexID primaryId, List<JobVertexID> alternativeIds, List<OperatorID> operatorIds, List<OperatorID> alternativeOperatorIds) {
(省略... )
this.operatorIDs = new ArrayList();
(省略... )
his.operatorIDs.addAll(operatorIds);
(省略... )
}
接着跟踪调用构造函数的地方:
jobVertex = new JobVertex(
chainedNames.get(streamNodeId),
jobVertexId,
legacyJobVertexIds,
// 对应构造函数中 operatorIds 参数
chainedOperatorVertexIds,
userDefinedChainedOperatorVertexIds);
跟踪到 createJobVertex 中:
List<Tuple2<byte[], byte[]>> chainedOperators = chainedOperatorHashes.get(streamNodeId);
List<OperatorID> chainedOperatorVertexIds = new ArrayList<>(); // Flink自动生成的OperatorID
List<OperatorID> userDefinedChainedOperatorVertexIds = new ArrayList<>(); // 用户设定的OperatorID
if (chainedOperators != null) {
for (Tuple2<byte[], byte[]> chainedOperator : chainedOperators) {
chainedOperatorVertexIds.add(new OperatorID(chainedOperator.f0));
userDefinedChainedOperatorVertexIds.add(chainedOperator.f1 != null ? new OperatorID(chainedOperator.f1) : null);
}
}
chainedOperatorHashes 是 createJobVertex 的第四个参数:
List<Tuple2<byte[], byte[]>> operatorHashes =
chainedOperatorHashes.computeIfAbsent(startNodeId, k -> new ArrayList<>());
// 来源 hashes
byte[] primaryHashBytes = hashes.get(currentNodeId);
for (Map<Integer, byte[]> legacyHash : legacyHashes) {
operatorHashes.add(new Tuple2<>(primaryHashBytes, legacyHash.get(currentNodeId)));
}
(省略...)
StreamConfig config = currentNodeId.equals(startNodeId)
// 对应 chainedOperatorHashes
? createJobVertex(startNodeId, hashes, legacyHashes, chainedOperatorHashes)
: new StreamConfig(new Configuration());
operatorIDs 的数据来源是 hashes,而 hashes 的创建则要追踪到 StreamingJobGraphGenerator#createJobGraph 中的以下代码:
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
问题三:IntermediateDataSet 是什么时候创建的?
我们把断点设置在 IntermediateDataSet 的构造函数第一行:
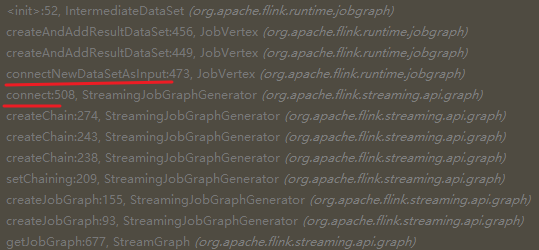
这个地方是之前被我忽略的地方,在 connect 方法创建 JobEdge 时候,会创建 IntermediateDataSet 对象。
2.2 physicalEdgesInOrder
我们目光回到 StreamingJobGraphGenerator#createJobGraph 方法,来看 setChaining 之后执行的 setPhysicalEdges
private void setPhysicalEdges() {
Map<Integer, List<StreamEdge>> physicalInEdgesInOrder = new HashMap<Integer, List<StreamEdge>>();
for (StreamEdge edge : physicalEdgesInOrder) {
int target = edge.getTargetId();
List<StreamEdge> inEdges = physicalInEdgesInOrder.get(target);
// create if not set
if (inEdges == null) {
inEdges = new ArrayList<>();
physicalInEdgesInOrder.put(target, inEdges);
}
inEdges.add(edge);
}
for (Map.Entry<Integer, List<StreamEdge>> inEdges : physicalInEdgesInOrder.entrySet()) {
int vertex = inEdges.getKey();
List<StreamEdge> edgeList = inEdges.getValue();
vertexConfigs.get(vertex).setInPhysicalEdges(edgeList);
}
}
physicalEdgesInOrder 数据来源是来自 connect 方法:
private void connect(Integer headOfChain, StreamEdge edge) {
physicalEdgesInOrder.add(edge);
(省略...)
}
JobEdge 对应的 StreamEdge 也被保存在 StreamConfig 中。
2.3 setSlotSharingAndCoLocation
代码继续运行,到了 createJobGraph 中调用 setSlotSharingAndCoLocation,这个命令就很好理解,接下来要设置 JobVertex 的 SlotSharingGroup 和 CoLocationGroup。
SlotSharingGroup: 插槽共享单元定义了可以在插槽中一起部署哪些不同的任务(来自不同的作业顶点)。这是一个软权限,与Co-Location提示定义的硬约束相反。
CoLocationGroup:Co-location group 是一组 JobVertex,其中一个顶点的第i个子任务必须与同一组中所有其他作业顶点的第i个子任务在同一TaskManager上执行。例如,使用 Co-Location Group来确保迭代头和迭代尾的第i个子任务调度到同一个TaskManager。
参考自《Flink – SlotSharingGroup》[https://www.cnblogs.com/fxjwind/p/6703312.html]
2.4 configureCheckpointing
继续跟踪 createJobGraph 的方法 configureCheckpointing:
private void configureCheckpointing() {
CheckpointConfig cfg = streamGraph.getCheckpointConfig();
long interval = cfg.getCheckpointInterval();
if (interval > 0) {
ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
// propagate the expected behaviour for checkpoint errors to task.
executionConfig.setFailTaskOnCheckpointError(cfg.isFailOnCheckpointingErrors());
} else {
// interval of max value means disable periodic checkpoint
interval = Long.MAX_VALUE;
}
// --- configure the participating vertices ---
// collect the vertices that receive "trigger checkpoint" messages.
// currently, these are all the sources
List<JobVertexID> triggerVertices = new ArrayList<>();
// collect the vertices that need to acknowledge the checkpoint
// currently, these are all vertices
List<JobVertexID> ackVertices = new ArrayList<>(jobVertices.size());
// collect the vertices that receive "commit checkpoint" messages
// currently, these are all vertices
List<JobVertexID> commitVertices = new ArrayList<>(jobVertices.size());
for (JobVertex vertex : jobVertices.values()) {
if (vertex.isInputVertex()) {
triggerVertices.add(vertex.getID());
}
commitVertices.add(vertex.getID());
ackVertices.add(vertex.getID());
}
// --- configure options ---
CheckpointRetentionPolicy retentionAfterTermination;
if (cfg.isExternalizedCheckpointsEnabled()) {
CheckpointConfig.ExternalizedCheckpointCleanup cleanup = cfg.getExternalizedCheckpointCleanup();
// Sanity check
if (cleanup == null) {
throw new IllegalStateException("Externalized checkpoints enabled, but no cleanup mode configured.");
}
retentionAfterTermination = cleanup.deleteOnCancellation() ?
CheckpointRetentionPolicy.RETAIN_ON_FAILURE :
CheckpointRetentionPolicy.RETAIN_ON_CANCELLATION;
} else {
retentionAfterTermination = CheckpointRetentionPolicy.NEVER_RETAIN_AFTER_TERMINATION;
}
CheckpointingMode mode = cfg.getCheckpointingMode();
boolean isExactlyOnce;
if (mode == CheckpointingMode.EXACTLY_ONCE) {
isExactlyOnce = true;
} else if (mode == CheckpointingMode.AT_LEAST_ONCE) {
isExactlyOnce = false;
} else {
throw new IllegalStateException("Unexpected checkpointing mode. " +
"Did not expect there to be another checkpointing mode besides " +
"exactly-once or at-least-once.");
}
// --- configure the master-side checkpoint hooks ---
final ArrayList<MasterTriggerRestoreHook.Factory> hooks = new ArrayList<>();
for (StreamNode node : streamGraph.getStreamNodes()) {
StreamOperator<?> op = node.getOperator();
if (op instanceof AbstractUdfStreamOperator) {
Function f = ((AbstractUdfStreamOperator<?, ?>) op).getUserFunction();
if (f instanceof WithMasterCheckpointHook) {
hooks.add(new FunctionMasterCheckpointHookFactory((WithMasterCheckpointHook<?>) f));
}
}
}
// because the hooks can have user-defined code, they need to be stored as
// eagerly serialized values
final SerializedValue<MasterTriggerRestoreHook.Factory[]> serializedHooks;
if (hooks.isEmpty()) {
serializedHooks = null;
} else {
try {
MasterTriggerRestoreHook.Factory[] asArray =
hooks.toArray(new MasterTriggerRestoreHook.Factory[hooks.size()]);
serializedHooks = new SerializedValue<>(asArray);
}
catch (IOException e) {
throw new FlinkRuntimeException("Trigger/restore hook is not serializable", e);
}
}
// because the state backend can have user-defined code, it needs to be stored as
// eagerly serialized value
final SerializedValue<StateBackend> serializedStateBackend;
if (streamGraph.getStateBackend() == null) {
serializedStateBackend = null;
} else {
try {
serializedStateBackend =
new SerializedValue<StateBackend>(streamGraph.getStateBackend());
}
catch (IOException e) {
throw new FlinkRuntimeException("State backend is not serializable", e);
}
}
// --- done, put it all together ---
JobCheckpointingSettings settings = new JobCheckpointingSettings(
triggerVertices,
ackVertices,
commitVertices,
new CheckpointCoordinatorConfiguration(
interval,
cfg.getCheckpointTimeout(),
cfg.getMinPauseBetweenCheckpoints(),
cfg.getMaxConcurrentCheckpoints(),
retentionAfterTermination,
isExactlyOnce),
serializedStateBackend,
serializedHooks);
jobGraph.setSnapshotSettings(settings);
}
最终组装得到了 JobCheckpointingSettings 对象,并设置到了 JobGraph 中。