概念
1. Big-Endian(大端模式)
Big-Endian 就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
2. Little-Endian(小端模式)
Little-Endian 就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
笔记:
大端模式又被称作大端字节序,高端字节序;小端模式又被称作小端字节序,低端字节序。(PS:“低端字节序”,我是在学习李忠老师的《x86实模式和保护模式》一书时了解到该词的)
阮一峰大神的这篇《理解字节序》 对字节序的定义如下:

因为这样的定义没有限定场景,因此在不同场景下套用该定义常常会使我混淆,尤其在理解机器指令的时候,这个“谁前谁后”的解释会让我无法自洽。
从阅读习惯看待字节序
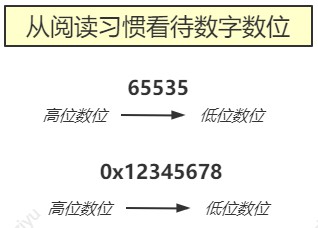
我们从小就知道,数字是从左往右读的,这符合人类的普遍阅读习惯。
比如十进制数 65535,数位从高到低依次是万,千,百,十,个。对十进制数而言,最左边是高位数位,最右边是低位数位。
我们类比到16进制数 0x12345678,也从左往右来阅读这个数。那么,对十六进制数而言,最左边就是高位字节,最右边是低位字节。
从内存地址的角度看字节序
首先,你可能需要对内存有一些基本的认识:
- 一个内存单元可以存储一个字节的内容,因此内存单元也常常被称为字节单元。
- 一个内存单元可以存储8个比特,即8个二进制数。但是,如果换算成16进制,一个内存单元仅能容纳2个16进制数。
如图所示,我们在画内存示意图的时候,我们用一个绿色矩形表示一个内存单元,每一个内存单元都有一个内存地址,方便计算机的处理器找到这块内存单元。
另外,我们也习惯于内存地址将低地址端放在下面,高地址端放在上面。
这个习惯,我猜测可能与古人建房子的习惯类似,所谓“万丈高楼平地起”,最先建的总是低层,然后再建高层。高层究竟建多高,这个总是不断发展和变化的,但是最底层总是从零开始,这个是相对稳定的。
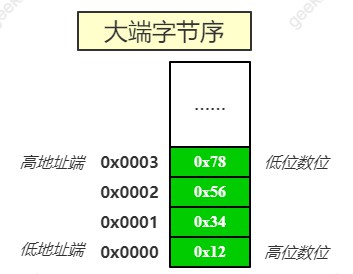
还是以十六进制数 0x12345678 为例,当它以大端字节序存储在内存中时,低地址端 0x0000 存储该数的高位字节 0x12;高地址端 0x0003 存储的是该数的低位字节 0x78。

当 0x12345678 以小端字节序存储在内存中时,低地址端 0x0000 存储该数的低位字节 0x78;高地址端 0x0003 存储的是该数的高位字节 0x12。
你看,如果我用内存示意图的这种上下分布的结构来表示字节序,“谁在前谁在后”这个理论就失效了~
从处理器看字节序
在学习李忠老师的《x86实模式和保护模式》时,我了解到 Intel 8086 处理器(经典的16位处理器)是采用小端字节序。Intel 公司后续的32位x86处理器和64位x64处理器采用的也依然是小端字节序。
比如下面有一条简单的传送指令代码:
mov ax, 0x2000
这条 mov 指令的意思是将立即数 0x2000 传送到 CPU 内的通用寄存器 ax 中。
这条指令在我配备 Intel x64 处理器的 Windows 系统电脑上,编译出来的机器码是 B80020。
汇编程序编译出来的文件是二进制文件,它的内容是0或者1,当使用 HexView.exe 用十六进制的方式来查看文件时,就有了如下图所示:

B8是机器指令的操作码,0x2000 的低位字节存储在二进制文件的低地址端,高位字节存储在二进制文件的高地址端。

这条指令所在的程序,如果从磁盘中被加载到内存中:
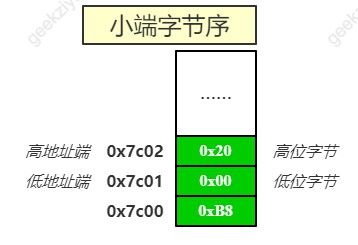
此时,指令在内存中仍然保持着小端字节序存储。接下来,如果指令执行,就要将内存中的内容放入到通用寄存器 ax 中了。

通常,寄存器的阅读顺序一般是从左到右。左边是高位字节,右边是低位字节。
也就是说指令执行之后,最终在寄存器 ax 中显示的结果和我们源程序中的值是一样的,都是 0x2000。
从网络传输的角度看字节序
在网络上传输数据时,由于数据传输的两端对应不同的硬件平台,采用的存储字节顺序可能不一致。所以在TCP/IP协议规定了在网络上必须采用网络字节顺序,也就是大端模式。
- 对于char型数据只占一个字节,无所谓大端和小端。
- 而对于非char类型数据,必须在数据发送到网络上之前将其转换成大端模式。
接收网络数据时按符合接受主机的环境接收。
简而言之,网络字节序是大端字节序。
我们常用 Wireshark 这款软件抓取 TCP 报文,以下是我抓取到的三次握手中的 SYN 报文的抓包情况:
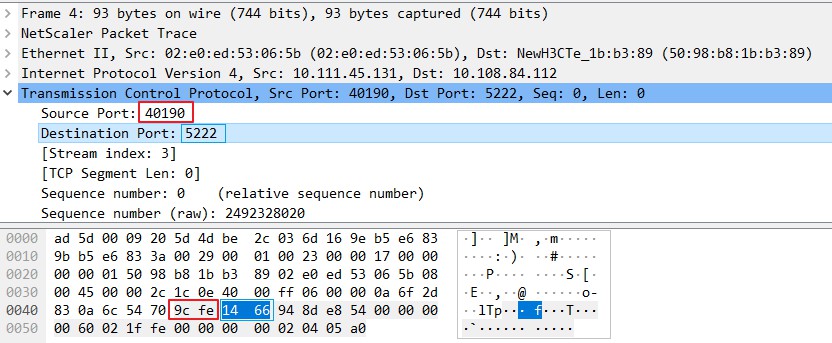
图中的 0000, 0010, 0020, 0030, 0040 表示的是16进制数。
我们通常编写和阅读的电脑文件中,总是习惯于从上到下,从左到右。此时低地址在左边或者在上边,高地址在右边或者下边。

十进制数 40190 等于十六进制数 0x9cfe,十进制数 5222 等于十六进制数 0x1466。
我们聚焦抓包的内容的第 4 行,即起始地址为 0x0040,最后一个地址为 0x004f。
0x9cfe的高位字节0x9c保存在低地址端0x0045,低位字节是0xfe保存在高地址端0x0046。0x1466的高位字节0x14保存在低地址端0x0047,低位字节是0x66保存在高地址端0x0048。
总结
可能你不了解内存,不清楚寄存器,不明白编译,但是你可以记住
“低低低,低高高”
-
低位字节排放在内存的低地址端,就是低端字节序。
-
低位字节排放在内存的高地址端,就是高端字节序。
-
高端字节序就是大端字节序;低端字节序就是小端字节序。