1 ElasticSearch 介绍
Elasticsearch 是一个实时的分布式搜索分析引擎, 它能让你以一个之前从未有过的速度和规模,去探索你的数据。 它被用作全文检索、结构化搜索、分析以及这三个功能的组合
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理
解它是如何工作的
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch 使用 JavaScript Object Notation 或者 JSON 作为文档的序列化格式。 JSON 序列化被大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。 它简单、简洁、易于阅读。
考虑下面这个 JSON 文档,它代表了一个 user 对象:
{
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info":
{ "bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [ "dolphins", "whales" ]
},
"join_date": "2018/05/20"
}
2 ElasticSearch 安装
必须要有 java 环境
[root@ES-100 ~]# java -version openjdk version "1.8.0_65" OpenJDK Runtime Environment (build 1.8.0_65-b17) OpenJDK 64-Bit Server VM (build 25.65-b01, mixed mode)
1. 下载elasticsearch
下载地址: 下载的rpm包
https://www.elastic.co/cn/downloads/elasticsearch
我的版本是:
elasticsearch-6.5.1
安装:
[root@ES-100 software]# rpm -ivh elasticsearch-6.5.1.rpm
目录说明
配置文件目录在/etc/elasticsearch [root@ES-100 elasticsearch]# pwd /etc/elasticsearch [root@ES-100 elasticsearch]# tree . ├── elasticsearch.keystore ├── elasticsearch.yml #es 配置文件 ├── jvm.options # java 的配置文件 ├── log4j2.properties ├── role_mapping.yml ├── roles.yml ├── users └── users_roles 服务启动目录: [root@ES-100 init.d]# /etc/init.d/elasticsearch 插件所在目录 [root@ES-100 plugins]# pwd /usr/share/elasticsearch/plugins
- 启动es服务
开启自启 [root@ES-100 init.d]# systemctl enable elasticsearch.service 开启es [root@ES-100 init.d]# service elasticsearch start
- 测试是否安装成功
[root@ES-100 init.d]# curl 'http://localhost:9200/?pretty';
{
"name" : "VeXx8SO",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "RPk51B7bRUuVHHFAkns6Sw",
"version" : {
"number" : "6.5.1",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "8c58350",
"build_date" : "2018-11-16T02:22:42.182257Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
3 ElasticSearch 配置文件介绍
Elasticsearch 已经有了 很好 的默认值, 特别是涉及到性能相关的配置或者选项,其它数据库可能需要调优,但总得来说,Elasticsearch 不需要。 如果你遇到了性能问题,解决方法通常是更好的数据布局或者更多的节点。
3.1 elasticsearch.yml重要文件
Elasticsearch 默认启动的集群名字叫 elasticsearch
可以在你的/etc/elasticsearch/elasticsearch.yml 中修改
cluster.name: elasticsearch_production
给每个节点设置一个有意义的、清楚的、描述性的名字,同样你可以在elasticsearch.yml 中配置:
node.name: elasticsearch_005_data
默认情况下, Elasticsearch 会把插件、日志以及你最重要的数据放在安装目录下。这会带来不幸的事故,如果你重新安装 Elasticsearch的时候不小心把安装目录覆盖了。如果你不小心,你就可能把你的全部数据删掉了。
最好的选择就是把你的数据目录配置到安装目录以外的地方,同样你也可以选择转移你的插件和日志目录。
默认的插件目录在/usr/share/elasticsearch/plugins
可以自定义更改如下:
path.data: /path/to/data1,/path/to/data2 # Path to log files: path.logs: /path/to/logs # Path to where plugins are installed: path.plugins: /path/to/plugins
最小主节点数 minimum_master_nodes 设定对你的集群的稳定 极其 重要,当你的集群中有两个 masters(注:主节点)的时候,这个配置有助于防止 脑裂 ,一种两个主节点同时存在于一个集群的现象。
如果你的集群发生了脑裂,那么你的集群就会处在丢失数据的危险中,因为主节点被认为是这个集群的最高统治者,它决定了什么时候新的索引可以创建,分片是如何移动的等等。
如果你有 两个 masters 节点,你的数据的完整性将得不到保证,因为你有两个节点认为他们有集群的控制权
这个配置就是告诉 Elasticsearch 当没有足够 master 候选节点的时候,就不要进行 master 节点选举,等master 候选节点足够了才进行选举。
此设置应该始终被配置为 master 候选节点的法定个数(大多数个)。法定个数就是 ( master 候选节点个数 / 2) + 1 。
可以在你的 elasticsearch.yml 文件中这样配置:
discovery.zen.minimum_master_nodes: 2
Elasticsearch 默认被配置为使用单播发现
使用单播,你可以为 Elasticsearch 提供一些它应该去尝试连接的节点列表。 当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master 节点,并加入集群。
这个配置在 elasticsearch.yml 文件中
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
内存交换
到磁盘对服务器性能来说是 致命 的
需要打开配置文件中的 mlockall 开关。 它的作用就是允许 JVM 锁住内存,禁止操作系统交换出去。在你的 elasticsearch.yml 文件中,设置如下:
bootstrap.mlockall: true
绑定IP
默认elasticsearch 只能访问自己127.0.0.1 ,如果需要让其他的机器的访问则需要在加上
network.host: 192.168.0.1
3.2 jvm.options 配置文件
Elasticsearch 默认安装后设置的堆内存是 1 GB
你也可以通过命令行参数的形式,在程序启动的时候把内存小传递给它,如果你觉得这样更简单的话:
[root@ES-100 bin]# /usr/share/elasticsearch/bin/elasticsearch -Xmx10g -Xms10g
确保堆内存最小值( Xms )与最大值( Xmx )的大小是相同的,防止程序在运行时改变堆内存大小, 这是一个很耗系统资源的过程。
标准的建议是把 50% 的可用内存作为 Elasticsearch 的堆内存,保留剩下的 50%。当然它也不会被浪费,Lucene 会利用起余下的内存.
但堆内存大小设置不要超过 32 GB
3.3 做实验用的配置文件
这只是我做实验用的配置文件, 具体环境,根据生产而定
elasticsearch.yml
[root@ES-100 ~]# egrep -v "^#|^$" /etc/elasticsearch/elasticsearch.yml path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 127.0.0.1,10.0.0.100
4 ElsaticSearch交互
所有其他语言可以使用 RESTful API 通过端口 9200 和Elasticsearch 进行通信,你可以用你最喜爱的 web客户端访问 Elasticsearch 。 事实上,正如你所看到的,你甚至可以使用 curl 命令来和 Elasticsearch 交互。
一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
VERB 适当的 HTTP 方法 或 谓词 :GET、 POST、 PUT、 HEAD或者 DELETE。
PROTOCOL http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理)
HOST Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点
PORT 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。
PATH API 的终端路径(例如 _count 将返回集群中文档数量)。 Path 可能包含多个组件,
例如:_cluster/stats 和 _nodes/stats/jvm 。
QUERY_STRING 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读)
BODY 一个 JSON 格式的请求体 (如果请求需要的话)
- 插入索引数据
每个雇员索引一个文档,包含该雇员的所有信息。
每个文档都将是 employee 类型 。
该类型位于 索引 megacorp 内。
该索引保存在我们的 Elasticsearch 集群中。
#插入3条数据
curl -XPUT 'localhost:9200/megacorp/employee/1?pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'
curl -XPUT 'localhost:9200/megacorp/employee/2?pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}'
curl -XPUT 'localhost:9200/megacorp/employee/3?pretty' -H 'Content-Type: application/json' -d'
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}'
- 查询索引中一行数据:
[root@ES-100 ~]# curl -XGET 'localhost:9200/megacorp/employee/1?pretty'
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests" : [
"sports",
"music"
]
}
}
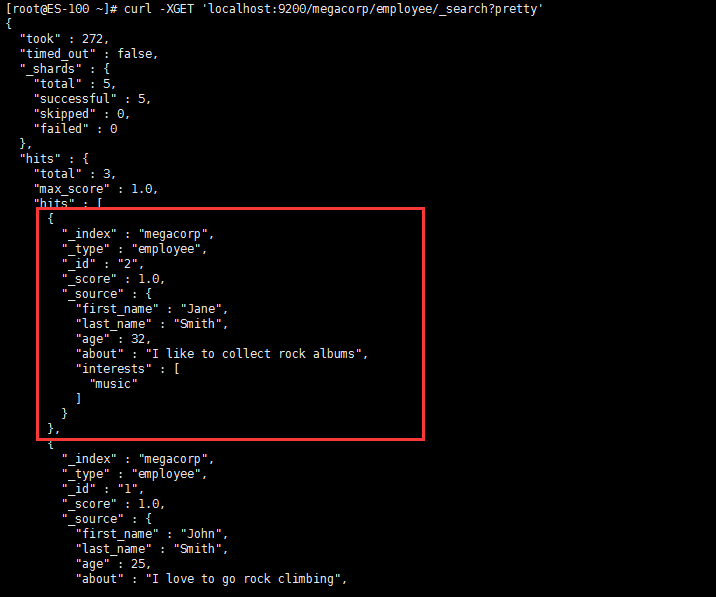
- 查询索引中的所有信息
[root@ES-100 ~]# curl -XGET 'localhost:9200/megacorp/employee/_search?pretty'
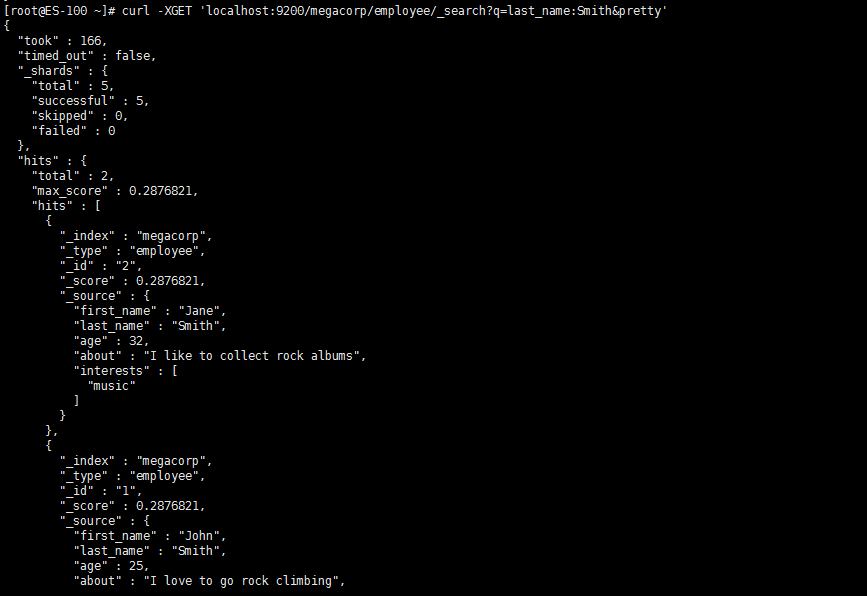
- 查询索引中符合条件的数据
搜索姓氏为Smith的雇员
[root@ES-100 ~]# curl -XGET 'localhost:9200/megacorp/employee/_search?q=last_name:Smith&pretty'
- 使用查询表达式查询想要的数据
Query-string 搜索通过命令非常方便地进行临时性的即席搜索 ,但它有自身的局限性
Elasticsearch 提供一个丰富灵活的查询语言叫做 查询表达式 ,它支持构建更加复杂和健壮的查询。
领域特定语言 (DSL), 指定了使用一个 JSON 请求。我们可以像这样重写之前的查询所有 Smith 的搜索 :
curl -XGET 'localhost:9200/megacorp/employee/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
} '

返回结果与之前的查询一样,但还是可以看到有一些变化。其中之一是,不再使用 query-string 参数,而是一个请求体替代。这个请求使用 JSON 构造,并使用了一个 match 查询
搜索姓氏为 Smith 的雇员,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter ,它支持高效地执行一个结构化查询
curl -XGET 'localhost:9200/megacorp/employee/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
} '

range 过滤器 , 它能找到年龄大于 30 的文档,其中 gt 表示_大于(_great than)
- 全文检索
搜索下所有喜欢攀岩(rock climbing)的雇员:
curl -XGET 'localhost:9200/megacorp/employee/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}'

5 ElasticSearch集群
Elasticsearch 可以横向扩展至数百(甚至数千)的服务器节点,同时可以处理PB级数据
Elasticsearch 天生就是分布式的,并且在设计时屏蔽了分布式的复杂性。
Elasticsearch 尽可能地屏蔽了分布式系统的复杂性。这里列举了一些在后台自动执行的操作:
分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
将集群中任一节点的请求路由到存有相关数据的节点
集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
一个运行中的 Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主 节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。
而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red
[root@ES-100 ~]# curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
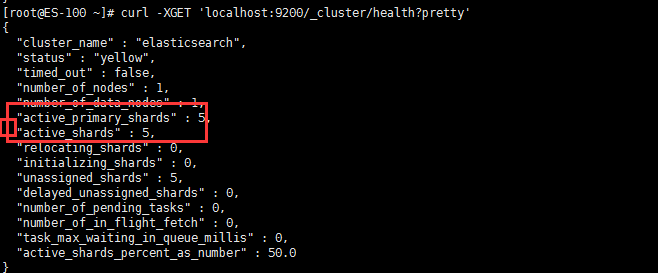
status 字段是要关注的
status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green:
所有的主分片和副本分片都正常运行
yellow:
所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red:
有主分片没能正常运行。
往 Elasticsearch 添加数据时需要用到 索引 —— 保存相关数据的地方。 索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间 一个 分片 是一个底层的 工作单元 ,它仅保存了 全部数据中的一部分
文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是 主 分片或者 副本 分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量
一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。 索引在默认情况下会被分配5个主分片, 但可以在创建索引时指定分配3个主分片和一份副本(每个主分片拥有一个副本分片)
例如下面建立了一个索引名叫: blogs ,设置了3个主分片,1个副本分片
curl -XPUT 'localhost:9200/blogs?pretty' -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
} '
[root@ES-100 ~]# curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 8,
"active_shards" : 8,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 8,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
megacorp 有 5个 主分片, blogs 有3个主分片 ,
现在集群有8个主分片 , 8个副本分片,现在集群只有一个节点。
所有集群中8个副本分片都是 unassigned —— 它们都没有被分配到任何节点。 在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。 当前我们的集群是正常运行的,但是在硬件故障时有丢失数据的风险
当第二个节点加入到集群后,3个 副本分片 将会分配到这个节点上——每个主分片对应一个副本分片。 这意味着当集群内任何一个节点出现问题时,我们的数据都完好无损。
所有新近被索引的文档都将会保存在主分片上,然后被并行的复制到对应的副本分片上。这就保证了我们既可以从主分片又可以从副本分片上获得文档。
5.1 搭建ES集群
| host | IP | linux version | es version |
| ES-100 | 10.0.0.100 | centos-7.2 | es-6.5.1 |
| ES-101 | 10.0.0.101 | centos-7.2 | es-6.5.1 |
在两台机器分别安装好elasticsearch
在两个节点的elasticsearch.yml上设置相同的cluster_name,但不同的node_name
在两个节点上设置相互发现的配置:discovery.zen.ping.unicast.hosts
ES-100的机器配置: [root@ES-100 ~]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml cluster.name: es-test node.name: es-test01 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 127.0.0.1,10.0.0.100 discovery.zen.ping.unicast.hosts: ["10.0.0.100", "10.0.0.101"] discovery.zen.minimum_master_nodes: 2 ES-101的机器配置: [root@ES-101 ~]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml cluster.name: es-test node.name: es-test02 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 127.0.0.1,10.0.0.101 discovery.zen.ping.unicast.hosts: ["10.0.0.100", "10.0.0.101"] discovery.zen.minimum_master_nodes: 2 两台机器重启ES: service elasticsearch restart
重启之后查看集群整体节点数量:

5.2 查看集群的状态信息
1. 查看集群状态
[root@ES-100 ~]# curl 'localhost:9200/_cat/health?v' 或者 [root@ES-101 ~]# curl 'localhost:9200/_cluster/health?pretty'

重要参数解释:
cluster_name: 表示集群名称,所有节点的集群名称必须一致
status:表示集群状态
green:
所有的主分片和副本分片都正常运行
yellow:
所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red:
有主分片没能正常运行。
number_of_nodes: 表示es集群有几个节点
active_primary_shards: 8 表示有8个主分片
active_shards: 16 表示一共有16个分片
unassigned_shards: 0 表示未分配分片
- 查看节点列表
[root@ES-100 ~]# curl 'localhost:9200/_cat/nodes?v' ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 10.0.0.101 13 97 0 0.00 0.01 0.05 mdi * es-test02 10.0.0.100 12 95 0 0.00 0.01 0.05 mdi - es-test01

master 下面的*号表示管理节点
- 查看所有索引信息
[root@ES-100 ~]# curl 'localhost:9200/_cat/indices?v'

index :表示es 集群有哪些索引, 例如megacorp 这个索引, 一共在5个主分片(pri),一个副本 ,索引里的文档一共是24.9KB大小
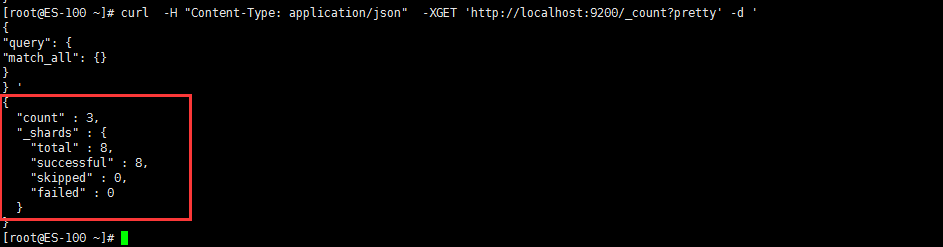
- 计算集群中文档的数量
curl -H "Content-Type: application/json" -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
} '
6 ElasticSearch 插件
ElasticSearch的图形化界面插件很多,
现在最常用的elasticsearch-head, 早期版本用marvel-agent。
上面全是用的curl 方式查看es 相应的一些信息, 命令太多很繁琐。 这个时候就可以用elasticsearch-head插件 ,使用web界面的来查看es集群的状态,节点信息, 创建索引, 设置分片等等功能。
6.1 安装elasticsearch-head插件
有若干种安装方式,比如压缩包安装,docker安装,但最简单的方式还是直接使用浏览器插件确保服务器上的es运行,使用chrome浏览器,安装专门的浏览器插件。
https://github.com/mobz/elasticsearch-head
安装方法如下:
git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head npm install #这时候可能会报错需要升级openssl,如果没报错则不用安装 yum update openssl -y #再安装 npm install npm run start
出现以下界面
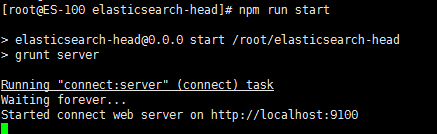
有点问题,不能连接到es
配置一下允许跨域请求设置:
在es集群的所有es节点给加上/etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true http.cors.allow-origin: "*"
重启ES服务,查看web界面
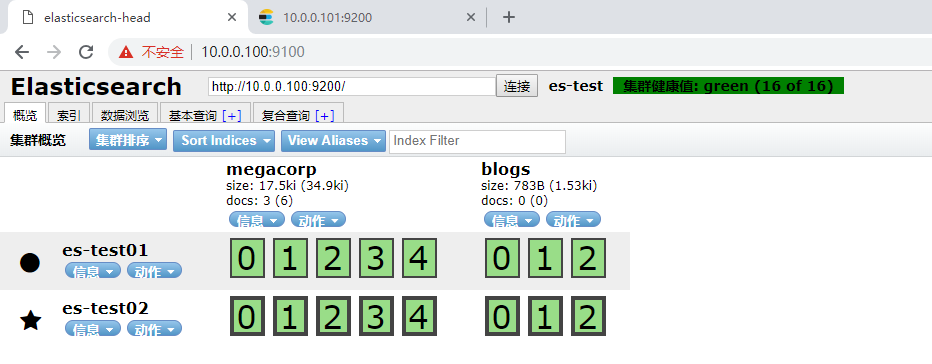
ok,这个时候就可以同web界面来操作es
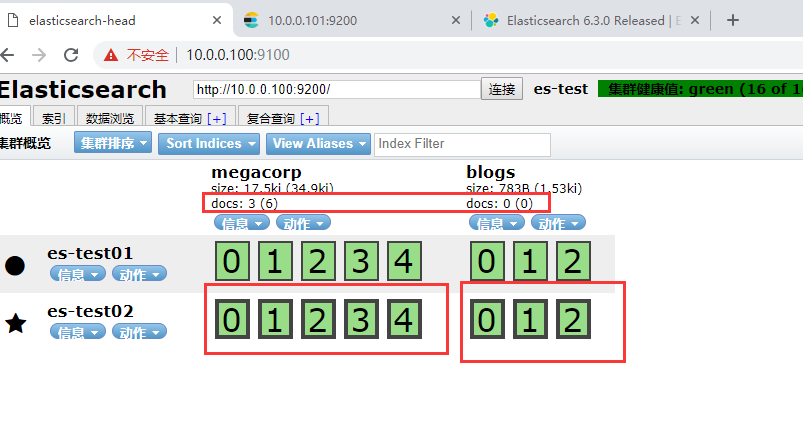
粗黑线框是 主分片
docs: 表示这个索引有多少数据
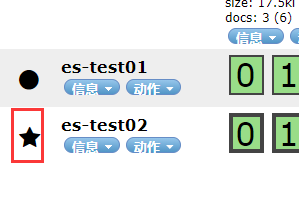
星号表示管理节点,
1 查看集群状态
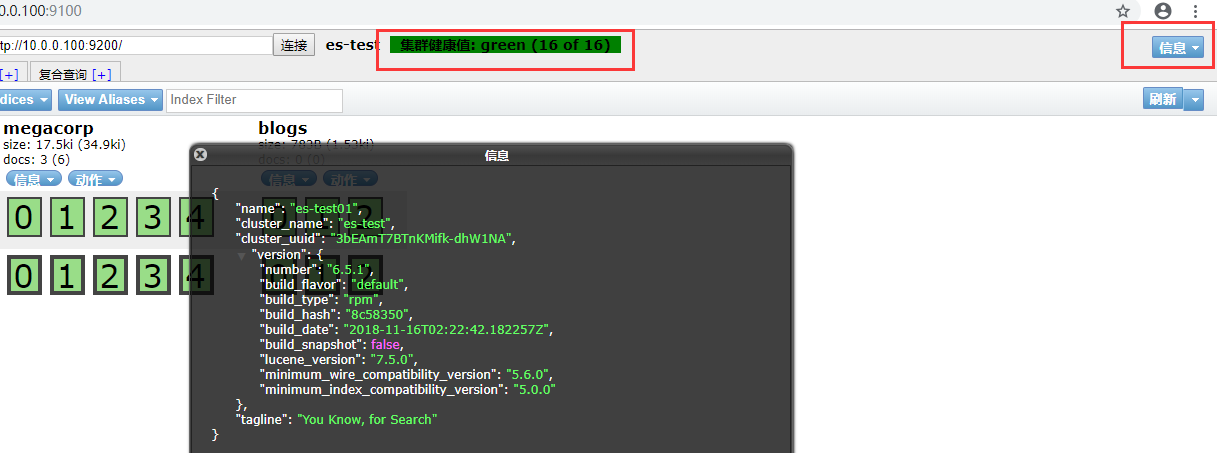
2 查看索引数据

7 ES集群分片一些常见问题
准备3个es 节点 , 上面已近有两个es 节点, 把新的es 节点 ,加入es集群,好看看问题。
| host | IP |
| ES-100 | 10.0.0.100 |
| ES-101 | 10.0.0.101 |
| ES-102 | 10.0.0.102 |
各机器配置文件如下
ES-100:的机器配置 [root@ES-100 ~]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml cluster.name: es-test node.name: es-test01 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 127.0.0.1,10.0.0.100 discovery.zen.ping.unicast.hosts: ["10.0.0.100", "10.0.0.101","10.0.0.102"] discovery.zen.minimum_master_nodes: 2 http.cors.enabled: true http.cors.allow-origin: "*" ES-101:的机器配置 [root@ES-101 ~]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml cluster.name: es-test node.name: es-test02 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 127.0.0.1,10.0.0.101 discovery.zen.ping.unicast.hosts: ["10.0.0.100", "10.0.0.101","10.0.0.102"] http.cors.enabled: true http.cors.allow-origin: "*" [root@ES-102 ~]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml cluster.name: es-test node.name: es-test03 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 127.0.0.1,10.0.0.102 discovery.zen.ping.unicast.hosts: ["10.0.0.0.100", "10.0.0.101","10.0.0.102"] discovery.zen.minimum_master_nodes: 2 http.cors.enabled: true http.cors.allow-origin: "*" 记得都重启es
当启动了第三个节点,我们的集群将会看起来如下

以blogs索引为例:
es-test01节点和 es-test02 的节点 上各有一个分片被迁移到了新的es-test03节点,现在每个节点上都拥有2个分片,而不是之前的3个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片的性能将会得到提升。分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有6个分片(3个主分片和3个副本分片)的索引可以最大扩容到6个节点,每个节点上存在一个分片,并且每个分片拥有所在节点的全部资源。主分片的数目在索引创建时 就已经确定了下来。读操作——搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量。
在运行中的集群上是可以动态调整副本分片数目的 ,我们可以按需伸缩集群。让我们把blogs副本数从默认的 1 增加到 2 :
[root@ES-100 ~]# curl -XPUT 'localhost:9200/blogs/_settings?pretty' -H 'Content-Type: application/json' -d'
{
"number_of_replicas" : 2
}'
{
"acknowledged" : true
}
看一下效果
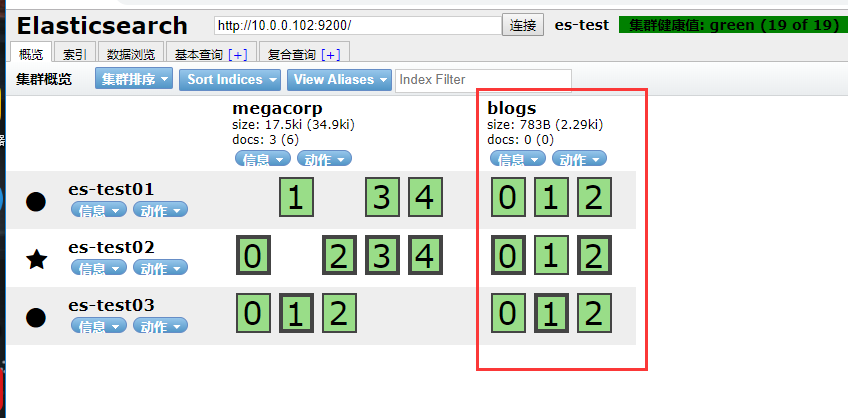
7.1 模拟ES节点故障
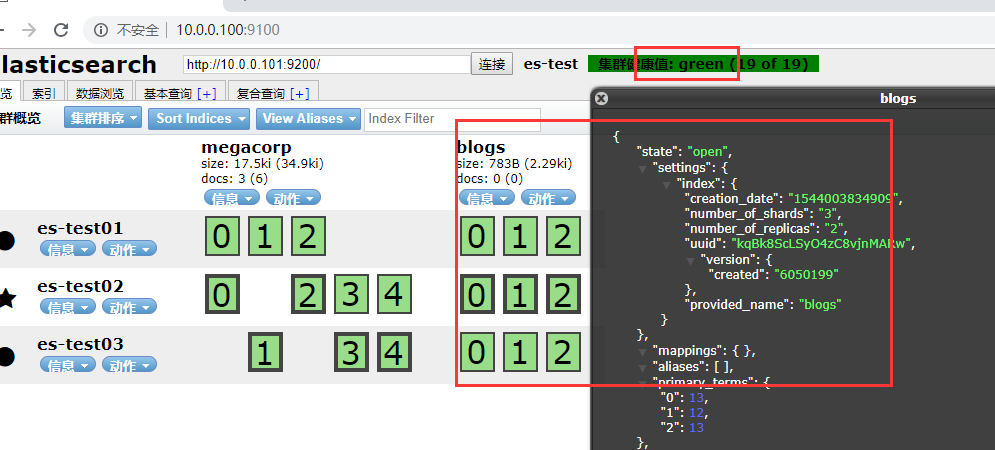
如果我们关闭第一个节点,这时集群的状态为
[root@ES-100 ~]# service elasticsearch stop

集群状态变为yellow了,这个提示主分片的过程是瞬间发生的,如同按下一个开关一般。
为什么集群状态是yellow 了,而不是green 了, 这里我设置了3个主分片,2个副本分片, 我在上面设置了blogs每个主分片需要对应2分副本分片, 正常这样设置的情况下, 应该有3个主分片6个副本分片, 但是现在有3个主分片, 3个副本分片,现在缺失副本分片了,所以此时的集群的状态会为yellow。
在重新启动es-test01 ,集群可以将缺失的副本分片再次进行分配。
8 文档元数据
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index 文档在哪存放
_type 文档表示的对象类别
_id 文档唯一标识
_index
_index 一个 索引 应该是因共同的特性被分组到一起的文档集合。 例如,你可能存储所有的产品在索引 products中,而存储所有销售的交易到索引 sales 中
_type
数据可能在索引中只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。 例如,所有的产品都放在一个索引中,但是你有许多不同的产品类别,比如 “electronics” 、”kitchen” 和 “lawncare”。
这些文档共享一种相同的(或非常相似)的模式:他们有一个标题、描述、产品代码和价格。他们只是正好属于“产品”下的一些子类
Elasticsearch 公开了一个称为 types (类型)的特性,它允许您在索引中对数据进行逻辑分区。不同types 的文档可能有不同的字段,但最好能够非常相似。
_id
ID 是一个字符串, 当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成。
9 文档
1. 查询文档
例如
[root@ES-100 ~]# curl -XGET http://10.0.0.100:9200/megacorp/employee/1?pretty
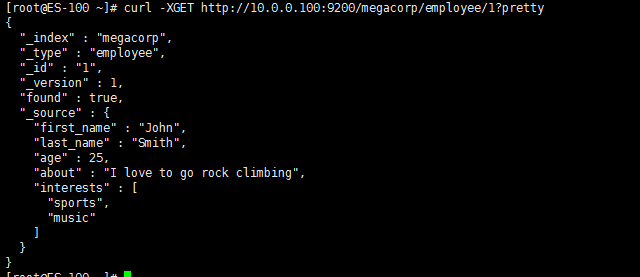
2. 返回文档一部分
默认情况下, GET 请求 会返回整个文档,这个文档正如存储在 _source 字段中的一样。但是也许你只对其中的 title 字段感兴趣。单个字段能用 _source 参数请求得到,多个字段也能使用逗号分隔的列表来指定
[root@ES-100 ~]# curl -XGET 'http://10.0.0.100:9200/megacorp/employee/1?_source=title,text&pretty'
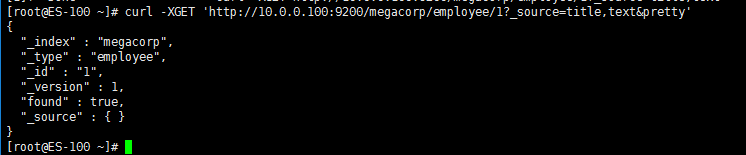
3. 检查文档是否存在
如果只想检查一个文档是否存在 –根本不想关心内容–那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
[root@ES-100 ~]# curl -i -XHEAD http://localhost:9200/website/blog/123 [root@ES-100 ~]# curl -i -XHEAD http://localhost:9200/megacorp/employee/1
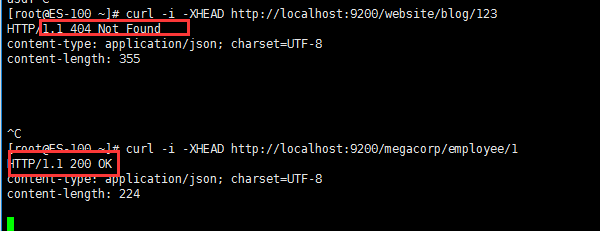
如果文档存在, Elasticsearch 将返回一个 200 ok 的状态码
若文档不存在, Elasticsearch 将返回一个 404 Not Found 的状态码:
4. 删除文档
删除文档 的语法和我们所知道的规则相同,只是 使用 DELETE 方法:
[root@ES-100 ~]# curl -i -XDELETE 'http://localhost:9200/megacorp/employee/1?pretty'
与上面与elasticsearch 交互那一块 可以看看
10 索引的CRUD
1 . 删除一个索引编辑
也是用curl 方式
用以下的请求来 删除索引:
DELETE /my_index
也可以这样删除多个索引
DELETE /index_one,index_two DELETE /index_*
甚至可以这样删除 全部 索引:
DELETE /_all DELETE /*
对一些人来说,能够用单个命令来删除所有数据可能会导致可怕的后果。如果你想要避免意外的大量删除, 你可以在你的elasticsearch.yml 做如下配置:
action.destructive_requires_name: true
这个设置使删除只限于特定名称指向的数据, 而不允许通过指定 _all 或通配符来删除指定索引库。
2. 索引设置编辑
你可以通过修改配置来自定义索引行为
下面是两个 最重要的设置: number_of_shards 每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。 number_of_replicas 每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
例如刚刚blogs 索引,设置的是每个主分片有两个副本分片
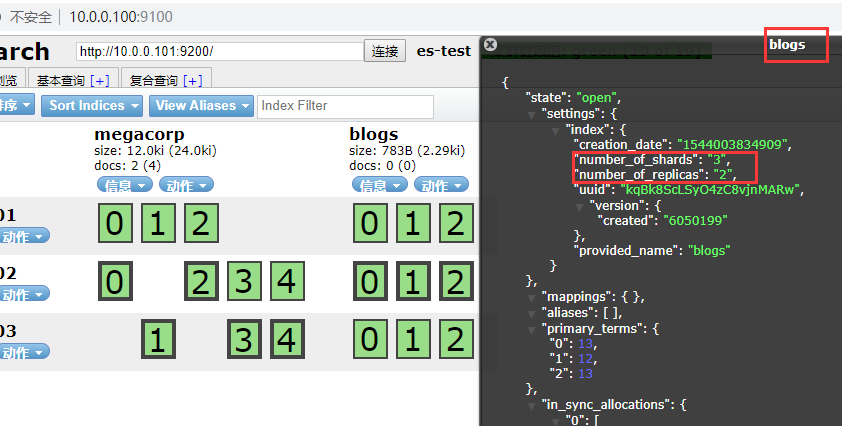
现在修改:
curl -XPUT 'localhost:9200/blogs/_settings?pretty' -H 'Content-Type: application/json' -d'
{
"number_of_replicas": 1
}'

表示修改成功了,web验证
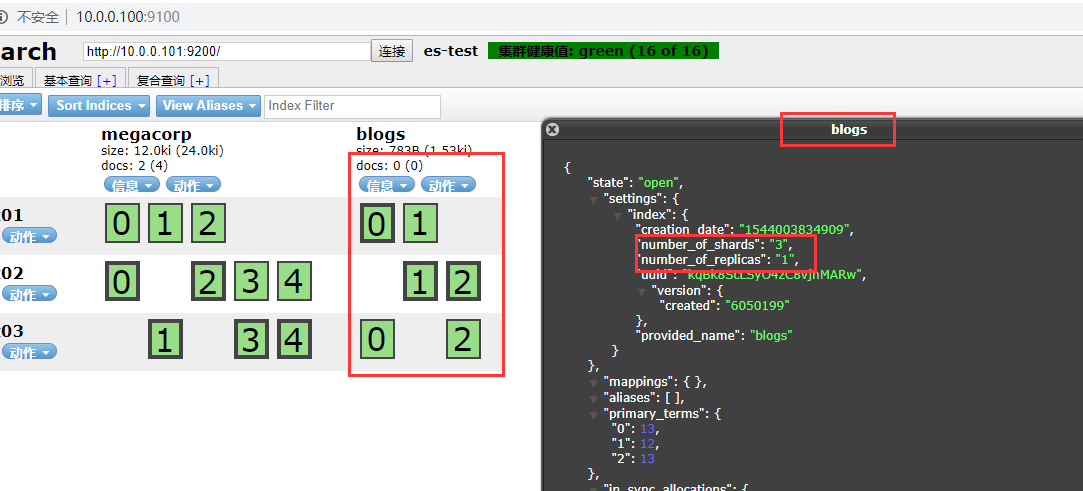
11 规定shards的个数设置
现在有索引了, 怎么规定索引的shard ,怎么样才能达到最优。
默认建立的索引是有5个主分片一个副本分片
例如blogs的shards
"number_of_shards": "3", "number_of_replicas": "1",
是每个主分片都有一个副本分片
具体怎么设置是看每个shard的数据量:
每个shad的数据量最好不要超过50G,一般20G-30G 之间比较合理的大小。
例如
整个索引大小是100G,shard 分成是5是合理的
整个索引大小是500G,用默认的shard 5 是不合理的
参考手册:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html