邮件讨论
------ 1.
在C2中实现PEA的潜在挑战, from V.I
- 移动分配位置是最大的挑战,目前C2没有可靠的方式重新计算JVM state。唯一可行的办法就是在IR build的时候就在重要的地方捕获这些jvm state,然后保留到PEA阶段。
- 移动 vs split。也不一定说非要移动分配,还可以split单个分配到多个地方。比如下面代码
MyPair p = new MyPair(1, 2);
if (cond1) {
...
if (cond2) {
... = p; // escapes
}
...
if (cond3) {
... = p; // escapes
}
...
}
既可以移动分配,
if (cond1) {
MyPair p = new MyPair(1, 2);
if (cond2) {
... = p; // escapes
}
...
if (cond3) {
... = p; // escapes
}
...
}
也可以split分配
if (cond1) {
...
if (cond2) {
... = new MyPair(1, 2); // escapes
}
...
if (cond3) {
... = new MyPair(1, 2); // escapes
}
...
}
这可能插入非常多的分配,所以如果要split,需要在哪下地方插分配也是需要抉择的。
4. 逃逸位置将ir分成两个部分:对象逃逸前,对象逃逸后。为了保留对象的identity invariant。PEA不能只是在每个逃逸位置放一个分配,它应该尊重逃逸事件的顺序,并且保证党有多个逃逸事件时同样的对象被观察到。
MyPair p = new MyPair(1, 2);
if (cond1) {
a.f = p; // escapes here
}
if (cond2) {
b.f = p; // escapes here
}
...
if (a.f == b.f) { // true when (cond1 && cond2)
比如,如果每个逃逸点插分配,那么最后if结果是错误的。
5. 要正确处理CFG合并是非常重要的,是这个优化可行的前提。
MyPair p = new MyPair(1, 2);
...
if (cond1) {
... = p; // escapes
}
// merge point
// no escape points beyound it
即使这里只有一个逃逸点,也不能假设merge point之后对象不会逃逸。不变的是,在每个cfg merge point,要么所有pred blocks的对象都materalized,要么没有一个pred block的对象materialized。一些可能的分配放置是:
MyPair p = NULL;
... // may benefit from scalarization
p = new MyPair(1, 2);
if (cond1) {
... = p; // escapes
}
// merge point
MyPair p = NULL;
... // may benefit from scalarization of p
if (cond1) {
... // may benefit from scalarization of p
p = new MyPair(1, 2);
... = p; // escapes
} else {
... // may benefit from scalarization of p
p = new MyPair(1, 2);
}
// merge point: no p materialization allowed beyond this point
// p = phi(p_cond1, p_cond2)
总的来说,不太可能专门创建一个pea phase,扩展目前ea看起来是最有希望的方向
- ea构造cg
2)对于全局逃逸对象:基于逃逸位置信息,pea选择可能可以的分配位置。
3)基于pea结果,全局逃逸分配或者被移动,或者被split。
4)再次在修改后的ir上运行ea。
重复上述流程,直到ir稳定,或者timeout。
--- 2.
Tobias也提到,最关键的问题也最困难的问题是目前EA不能很好的处理甚至一些很简单的控制流merge,即对象及时没有在任何路径上逃逸,但是i因为对于EA来说cfg太复杂,以至于ea不能证明这个对象没有逃逸。相关的例子可以参见https://cr.openjdk.java.net/~thartmann/EA_examples
Graal PEA论文细节
1. 数据结构
核心是在该逃逸的地方逃逸,不该逃逸的地方标量化。核心数据结构:

当遍历控制流的时候,pea会遇到一些对分配状态有影响的node,他们需要特殊对待。总体分三类:
- allocate node会创建virtualobject
- 如果一个node的任意input在alias中,那么当前node需要重新求值
- merge和countedloop需要合并多个状态
2. pattern
具体来说,由下面一些pattern:
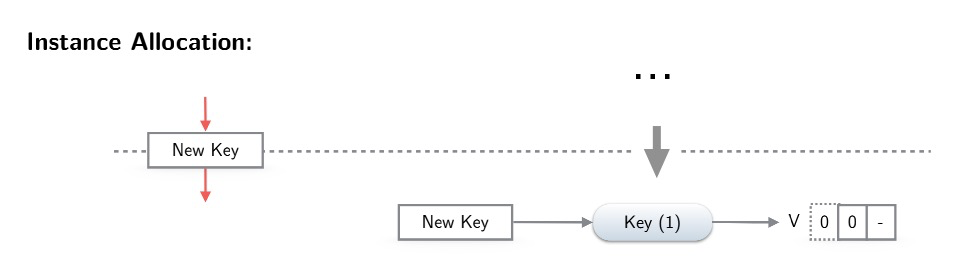
对于instance allocation,会创建VirtualObject和VirtualState,然后VirtualState里面的entries会初始化为默认值。同时向alias、state插入新entry,前者插入当前allocation node到VirtualObject的映射,后者插VirutalObject到VirtualState的映射。
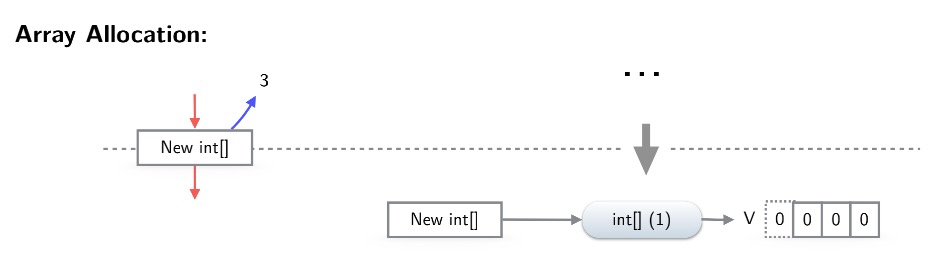
只有长度statically known的数组分配才能被pea处理。类似对象分配,数组分配会创建VirtualObject和VirtualState,然后alias,state插入映射。VirtualState的entries对应数组大小,为了让overhead不太大,目前graal pea要求这个statically known的size必须<=32。否则pea不处理。
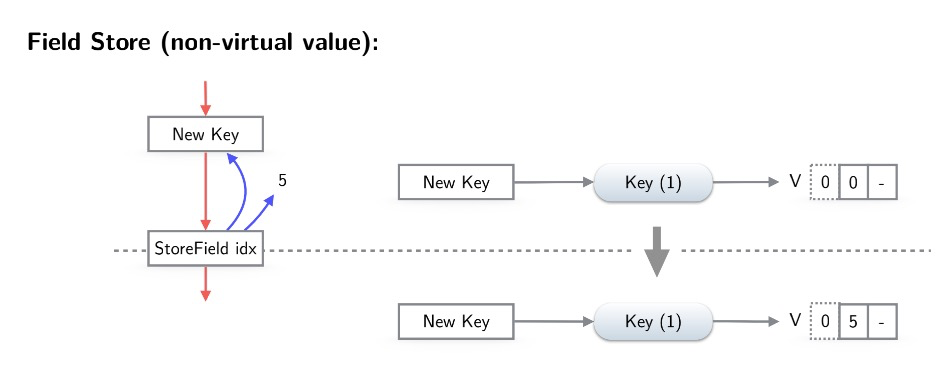
将非virtual对象的field赋值到virtual对象,会更新field的VirtualState。比如图片将常量5赋值给key,直接更新key对应的entries。
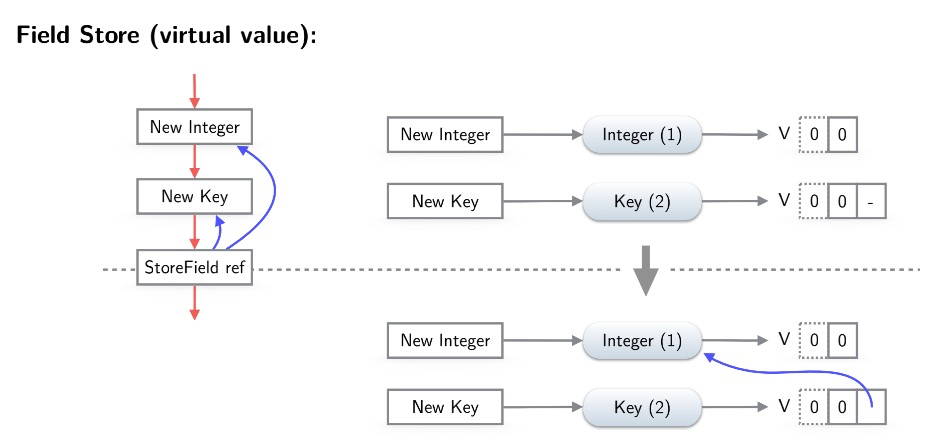
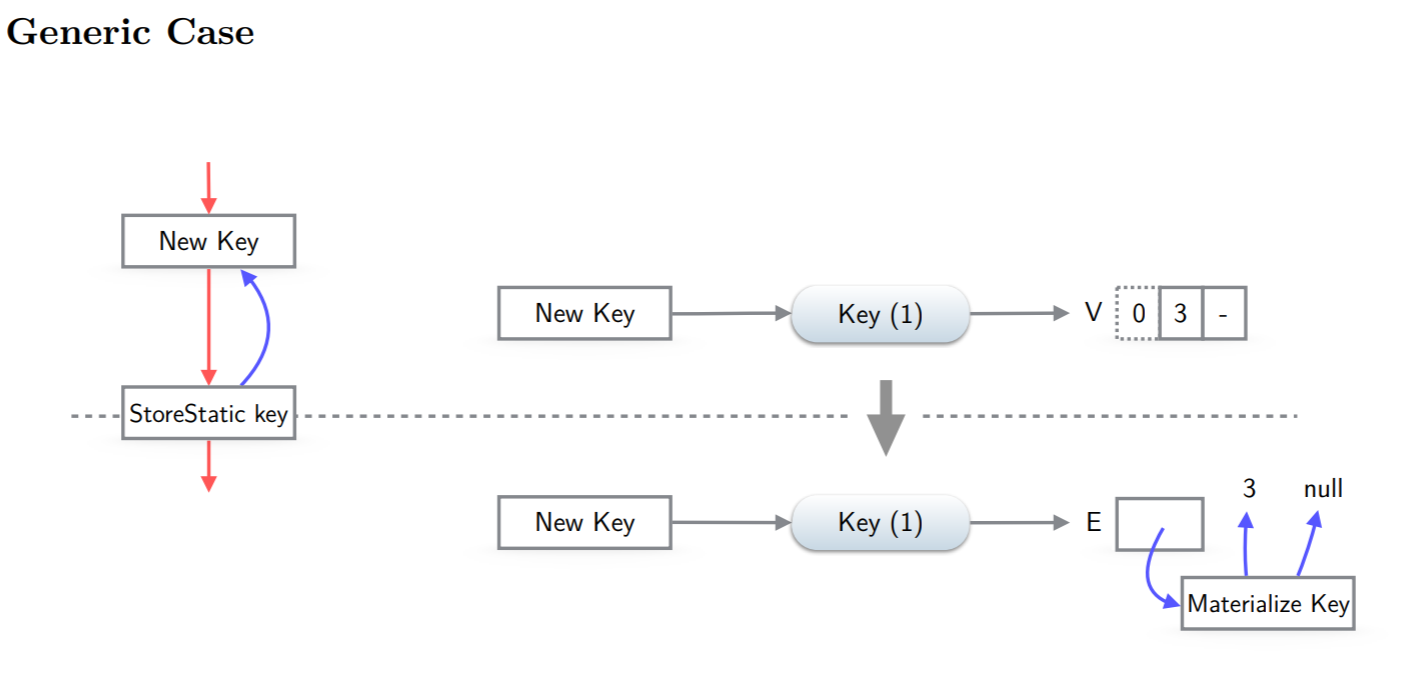
如果操作不是上面提到的可以virtualize的,比如从LoadIndexed一个非常量索引,或者其他情况,就需要materialize,引用当前对象的节点也需要替换为引用materalized后的值,比如
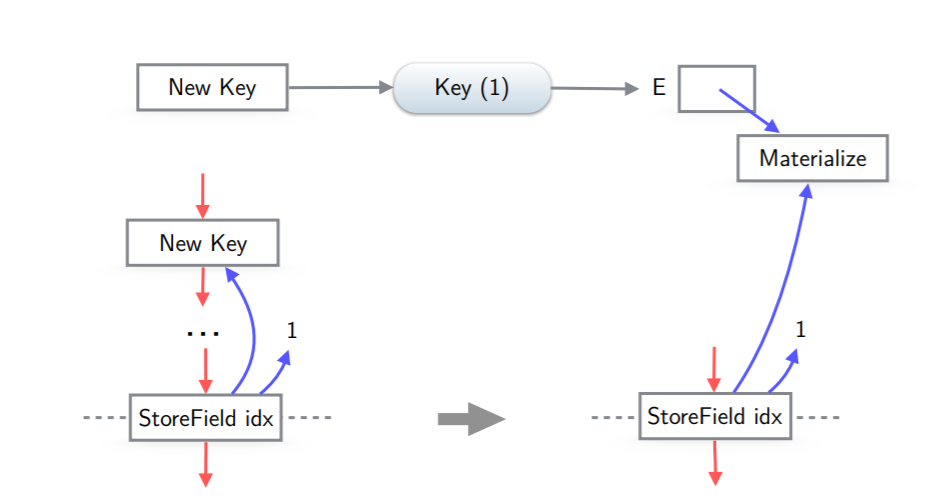
storefield引用了一个escaped的对象,pea处理时候需要引用materliazed的值
3.控制流合并,分割
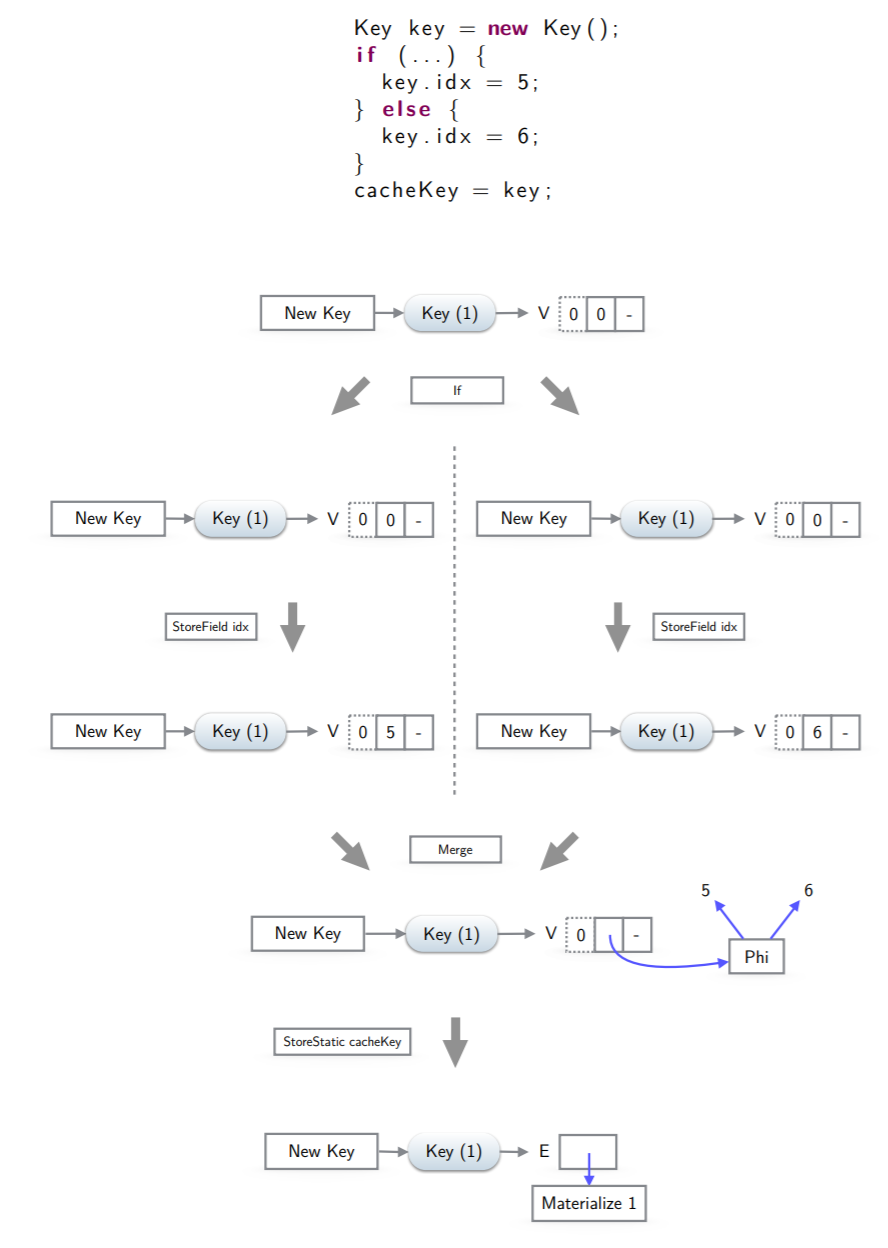
在cfg split的位置,比如if出的key,需要为每个successor拷贝一份状态(VirtualState),然后每个分支独立修改各种状态,分别赋值5和6,最后cfg merge,需要创建一个Phi来合并两个VirtualObject的field,由于将key赋值给cacheKey,对象发生逃逸,需要materialize,对象状态也要修改为EscapedState。合并VirtualObject的状态有详细的规则:
- 如果VirtualObject在所有predecessor逃逸了,那么合并后的状态是EscapedState,materializedValue指向一个新创建的phi,它会合并所有predecessor状态。
- 如果VirtualObject在一些predecessor逃逸了,一些没有,那么所有virtual状态都需要materialize(??那这岂不是pea没用了)
- 如果VirtualObject在所有predecessor都是virtual,那么合并后的状态也是virtual,所有VirtualState里面的field都需要合并。对于每个field,MergeProcess会查找这个field在所有predecessor VirtualObject:
- 如果所有field都是一样的,那么那么这个值就是信状态的值
- 果有些field不一样,MergeProcessor会对这些field创建Phi,
一些想法
ea实现大概是,遍历所有节点,找到感兴趣的节点,构造出PointsToNode(FieldNod,JavaObjectNode,LocalVarNode)。pea它沿着控制流遍历,用不同的概念来构造cg,所以看起来V.I提到的潜在可行的方法并不是最优的选择,甚至是不可行的,照着graal pea做一个可能是比较好的方式。
大致流程:先算出cfg,然后遍历每个基本块里面的每个节点,按照论文提到的方式,对于一些特殊的节点(CastII,AllocateXX)做处理,遇到控制流split/merge还要特殊处理状态。
- 在逃逸分析前构造CFG
- 实现Graal PEA算法
a. 处理控制流split/merge
b. 处理循环
c. 处理各种操作的effect
d. 精心挑选节点,针对这些节点实现虚拟机过程 - 基于PEA结果,实现各种优化
a. 标量替换优化
b. 指针比较优化
c. memory alias narrowing
d. tba
潜在难点
- 目前c2构造cfg是在codegen做的,而ea是优化的早期做的,不能直接复用PhaseCFG,因为它用了一些matcher的能力。要在优化早期将ideal graph转成cfg是很大的工作(1.识别bblock 2. schedule nodes to bblocks 3. 识别loop)
- 正如V.I提到,c2没有可靠的方式重新算状态,node需要materialize或者cfg split/merge这些需要状态的地方,都要求在IR构造阶段提前准备好,不一定能准备好,可能是最大的风险点
- 在实现pea后,还需要把当前c2 ea的一些特性也加到pea上,比如指针比较优化,memory alias narrowing很复杂。
- tba
参考
MS SUMMARY: https://gist.github.com/JohnTortugo/c2607821202634a6509ec3c321ebf370
AWS MAIL: https://mail.openjdk.java.net/pipermail/hotspot-compiler-dev/2021-May/047486.html
MS MAIL: https://mail.openjdk.java.net/pipermail/hotspot-dev/2021-October/055049.html
PEA具体实现:https://ssw.jku.at/Teaching/PhDTheses/Stadler/Thesis_Stadler_14.pdf(grraal pea)
PEA概述:https://www.ssw.uni-linz.ac.at/Research/Papers/Stadler14/Stadler2014-CGO-PEA.pdf
EA论文:https://www.researchgate.net/publication/2804836_Escape_Analysis_for_Java(c2 ea原始论文)
过程间分析的ea论文:https://www.usenix.org/legacy/events/vee05/full_papers/p111-kotzmann.pdf(c2 ea分析callee用到的字节码层面做ea的论文)