查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 select * from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
select * from peoplewhere peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
例如:
产品参数表rule_product_info 同一个申请单是否有多条记录
用select app_no,count(1) from rule_product_info group by app_no having count(1)>1
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)3、查找表中多余的重复记录(多个字段) select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录delete from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录select * from vitae awhere (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
(二)比方说在A表中存在一个字段“name”,而且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项;Select Name,Count(*) From A Group By Name Having Count(*) > 1如果还查性别也相同大则如下:Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1
COUNT(*) 函数返回在给定的选择中被选的行数。
语法:SELECT COUNT(*) FROM table
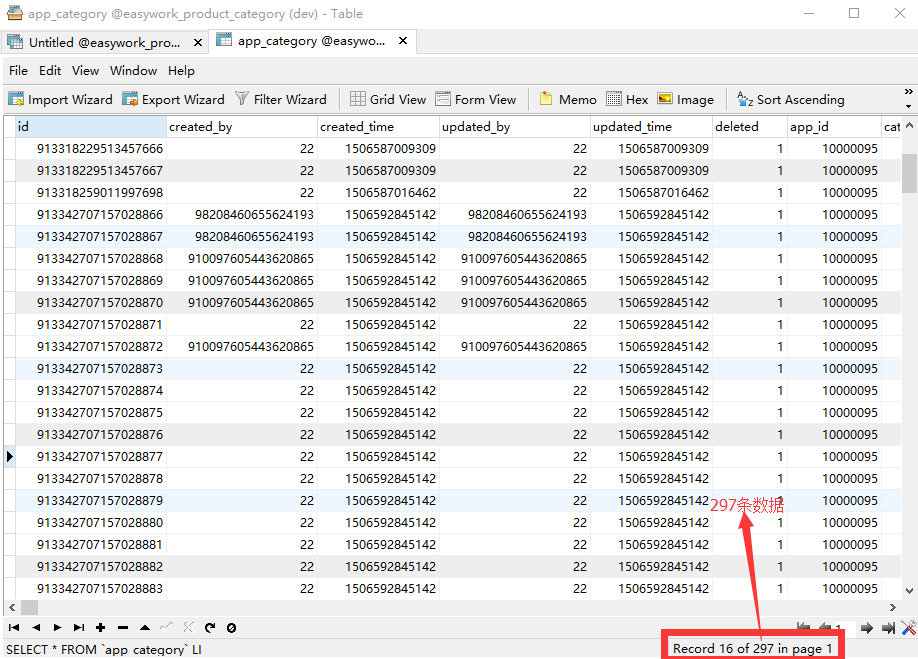
使用:现在有一个表,名叫app_category,从Navicat中可以看到表中所有数据,如图所示,可见表中有297条数据
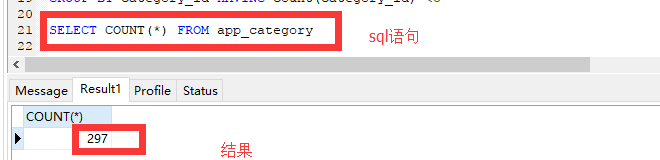
使用count函数的时候可以看到:
当然仅仅是这个样子,是木有意义的,我用个可视化工具一眼看穿,要这个函数就显得鸡肋了,那么我们继续往下看。
场景是这样的:表app_category与表category关联。且表间关系是一对多,即同一个app_category_id 对应多个category-id,现在我需要统计出每一个category_id在app_category表中出现的次数那么该如何实现呢,请看接下来的操作:

这样依然有点不够酷炫,那么我们还可以在后面继续追加sql语句呀
例如这条语句:
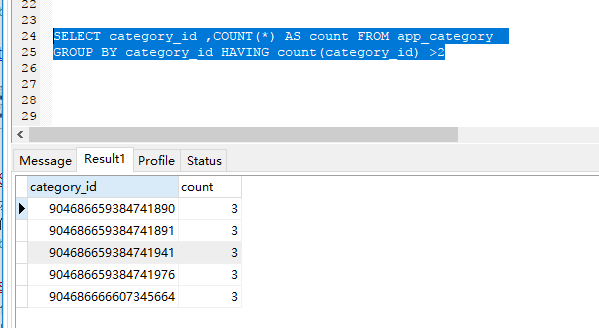
SELECT category_id ,COUNT(*) AS count FROM app_category
GROUP BY category_id HAVING count(category_id) >2
其查询的结果是只有count的值大于2 的时候,才是需要的结果
是不是有点小先进了,当然不要激动,我们还可以把这个查询的结果作为子查询,进行嵌套查询,两个表关联查询然后再嵌套查询等等。这里我就不过多截图,上一个开发商城项目中用到的查询语句:
SELECT ps.name FROM property_set ps , category_property_set cps WHERE ps.id=cps.property_set_id AND category_id=(
SELECT category_id AS count FROM category_property_set
GROUP BY category_id HAVING count(category_id) <5
)
大眼一看,可能比较懵逼,听我分析一下:
首先是子查询:SELECT category_id AS count FROM category_property_set
GROUP BY category_id HAVING count(category_id) <5
查出category_property_set 表中category_id出现次数小于5的那个category_id的具体的值,刚好得到的结果是只有一条,那么满足嵌套查询的条件,用到<,>=等符号时,子查询结果必须唯一,所有给其添加到外部查询,其实等价于这样一条语句:
SELECT ps.name FROM property_set ps , category_property_set cps WHERE ps.id=cps.property_set_id AND category_id=925640926728343552
不用怀疑,这个category_id就是查询出来的ID,然后这又是一个最最基本的两表联合查询,连个外联内联都没用,然后结果就是这个样子
