hadoop的架构
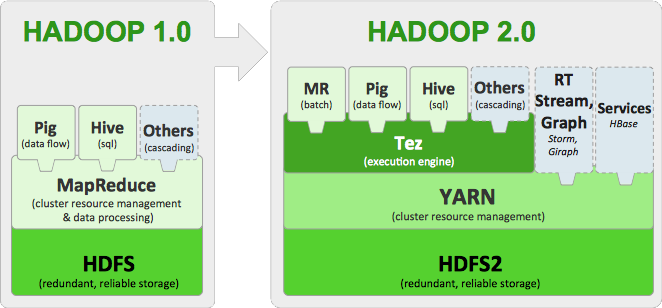
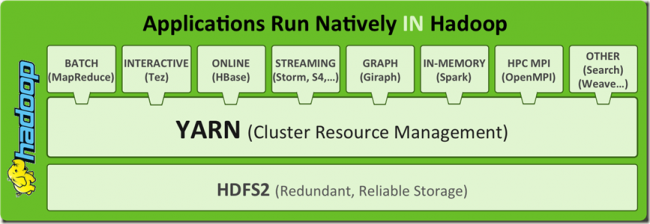
HDFS + MapReduce = Hadoop
MapReduce = Mapper + Reducer
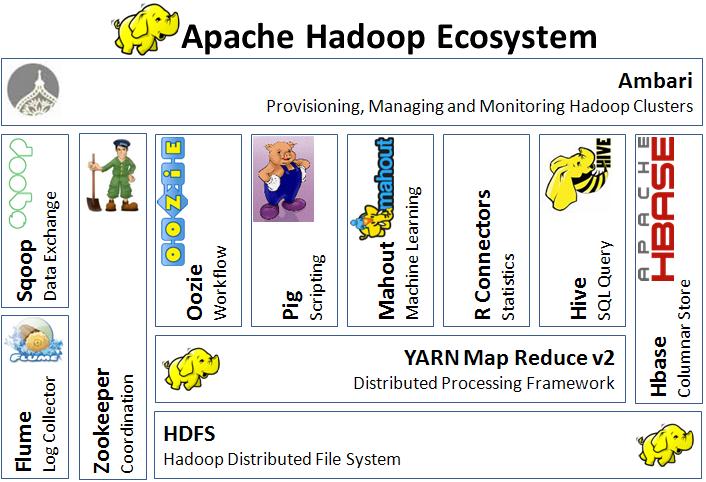
hadoop的生态系统
准备四个节点,系统版本为CentOS7.3
192.168.135.170 NameNode,SecondaryNameNode,ResourceManager
192.168.135.171 DataNode,NodeManager
192.168.135.169 DataNode,NodeManager
192.168.135.172 DataNode,NodeManager
1、修改各节点hosts
# vim /etc/hosts
192.168.135.170 node1 master
192.168.135.171 node2
192.168.135.169 node3
192.168.135.172 node4
2、校对时间
# yum install -y ntp ntpdate && ntpdate pool.ntp.org
3、安装java环境
# yum install -y java java-1.8.0-openjdk-devel
# vim /etc/profile.d/java.sh
export JAVA_HOME=/usr
# source /etc/profile.d/java.sh
4、修改各节点环境变量
# vim /etc/profile.d/hadoop.sh
export HADOOP_PREFIX=/bdapps/hadoop
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
# source /etc/profile.d/hadoop.sh
# scp /etc/profile.d/hadoop.sh node2:/etc/profile.d/hadoop.sh
# scp /etc/profile.d/hadoop.sh node3:/etc/profile.d/hadoop.sh
# scp /etc/profile.d/hadoop.sh node4:/etc/profile.d/hadoop.sh
5、创建用户
# useradd hadoop
# echo 'hadoop' | passwd --stdin hadoop
6、设置ssh互信
# su - hadoop
$ ssh-keygen
$ ssh-copy-id node1
$ ssh-copy-id node2
$ ssh-copy-id node3
$ ssh-copy-id node4
7、配置master节点,即node1
a、创建目录
# mkdir -pv /bdapps
# mkdir -pv /data/hadoop/hdfs/{nn,snn,dn}
# chown hadoop.hadoop -R /data/hadoop/hdfs
b、下载程序包
# wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
# tar xvf hadoop-2.6.5.tar.gz -C /bdapps/
# cd /bdapps/
# ln -sv hadoop-2.6.5/ hadoop
# cd hadoop
# mkdir logs
# chmod g+w logs
# chown -R hadoop.hadoop /bdapps/hadoop
c、配置NameNode
# cd etc/hadoop/
# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.135.170:8020</value>
<final>true</final>
</property>
</configuration>
d、配置yarn
# vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.135.170:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.135.170:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.135.170:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.135.170:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.135.170:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>
e、配置HDFS
# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
</configuration>
f、配置MapReduce framework
# cp mapred-site.xml.template mapred-site.xml
# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
g、定义slaves
# vim slaves
192.168.135.171
192.168.135.169
192.168.135.172
8、配置node2,node3,node4
a、创建目录
# mkdir -pv /bdapps
# mkdir -pv /data/hadoop/hdfs/{nn,snn,dn}
# chown hadoop.hadoop -R /data/hadoop/hdfs
b、下载程序包
# wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
# tar xvf hadoop-2.6.5.tar.gz -C /bdapps/
# cd /bdapps/
# ln -sv hadoop-2.6.5/ hadoop
# cd hadoop
# mkdir logs
# chmod g+w logs
# chown -R hadoop.hadoop /bdapps/hadoop/logs
c、从node1上复制配置文件
# su - hadoop
$ scp /bdapps/hadoop/etc/hadoop/* node2:/bdapps/hadoop/etc/hadoop/
$ scp /bdapps/hadoop/etc/hadoop/* node3:/bdapps/hadoop/etc/hadoop/
$ scp /bdapps/hadoop/etc/hadoop/* node4:/bdapps/hadoop/etc/hadoop/
9、格式化HDFS,需要以hadoop用户身份在master节点上执行
# su - hadoop
$ hdfs --help
http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
$ hdfs namenode -format
common.Storage: Storage directory /data/hadoop/hdfs/nn has been successfully formatted.
$ ll /data/hadoop/hdfs/nn/current/
10、启动hadoop,有两种方式
a、在各节点上分别启动各服务
master节点需要启动HDFS的NameNode服务和yarn的ResourceManager服务。
$ hadoop-daemon.sh start namenode
$ hadoop-daemon.sh start secondarynamenode
$ yarn-daemon.sh start resourcemanager
各slave节点需要启动HDFS的DataNode服务和yarn的NodeManager服务。
$ hadoop-daemon.sh start datanode
$ yarn-daemon.sh start nodemanager
b、在master节点上用脚本控制集群中的各节点启动
$ start-dfs.sh
Starting namenodes on [node1]
node1: starting namenode, logging to /bdapps/hadoop/logs/hadoop-hadoop-namenode-node1.out
192.168.135.172: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node4.out
192.168.135.171: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node2.out
192.168.135.169: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node3.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is 38:28:13:e9:f0:e7:06:37:b9:3e:96:b5:ce:b9:06:fb.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /bdapps/hadoop/logs/hadoop-hadoop-secondarynamenode-node1.out
尝试上传一个文件
$ hdfs dfs -ls /
$ hdfs dfs -mkdir /test
$ hdfs dfs -put /etc/fstab /test/
$ hdfs dfs -lsr /
drwxr-xr-x - hadoop supergroup 0 2017-04-06 02:19 /test
-rw-r--r-- 2 hadoop supergroup 541 2017-04-06 02:19 /test/fstab
$ hdfs dfs -cat /test/fstab
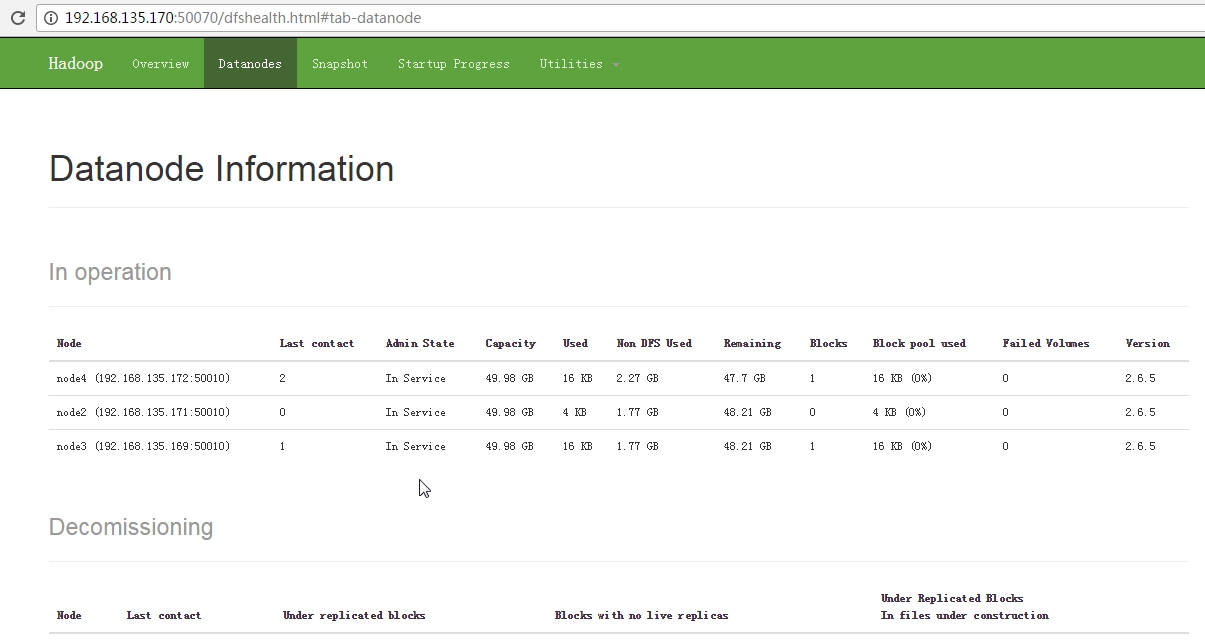
查看hdfs信息
http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html#dfsadmin
-report [-live] [-dead] [-decommissioning]:Reports basic filesystem information and statistics. Optional flags may be used to filter the list of displayed DataNodes.
$ hdfs dfsadmin -report
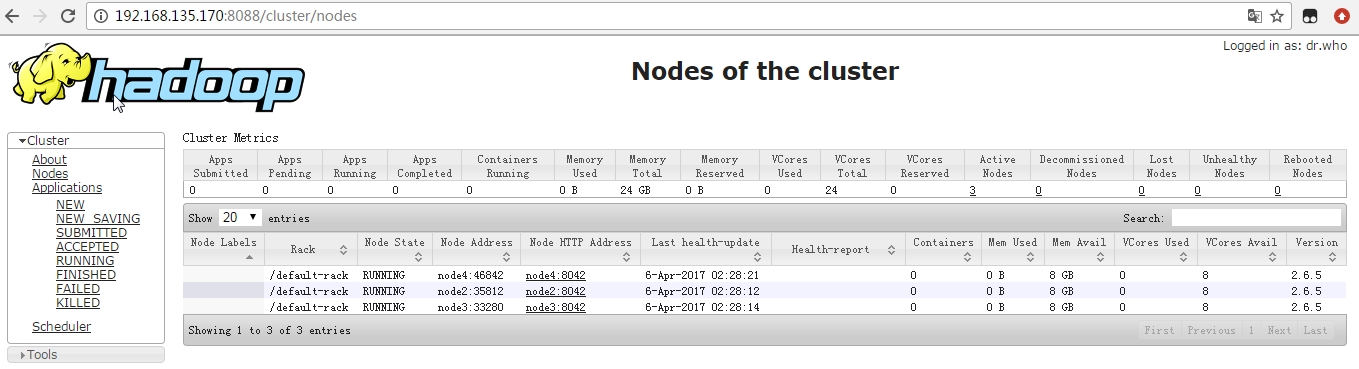
查看yarn信息
hadoop2引入了yarn框架,对每个slave节点可以通过NodeManager进行管理,启动NodeManager进程后,即可加入集群。
$ yarn node -list
17/04/07 03:33:33 INFO client.RMProxy: Connecting to ResourceManager at /192.168.135.170:8032
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
node4:46842 RUNNING node4:8042 0
node2:35812 RUNNING node2:8042 0
node3:33280 RUNNING node3:8042 0
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-resourcemanager-node1.out
192.168.135.172: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node4.out
192.168.135.171: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node2.out
192.168.135.169: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node3.out
在master节点上的进程
$ jps
2272 NameNode
2849 ResourceManager
2454 SecondaryNameNode
3112 Jps
在slave节点上的进程
$ jps
12192 Jps
12086 NodeManager
11935 DataNode
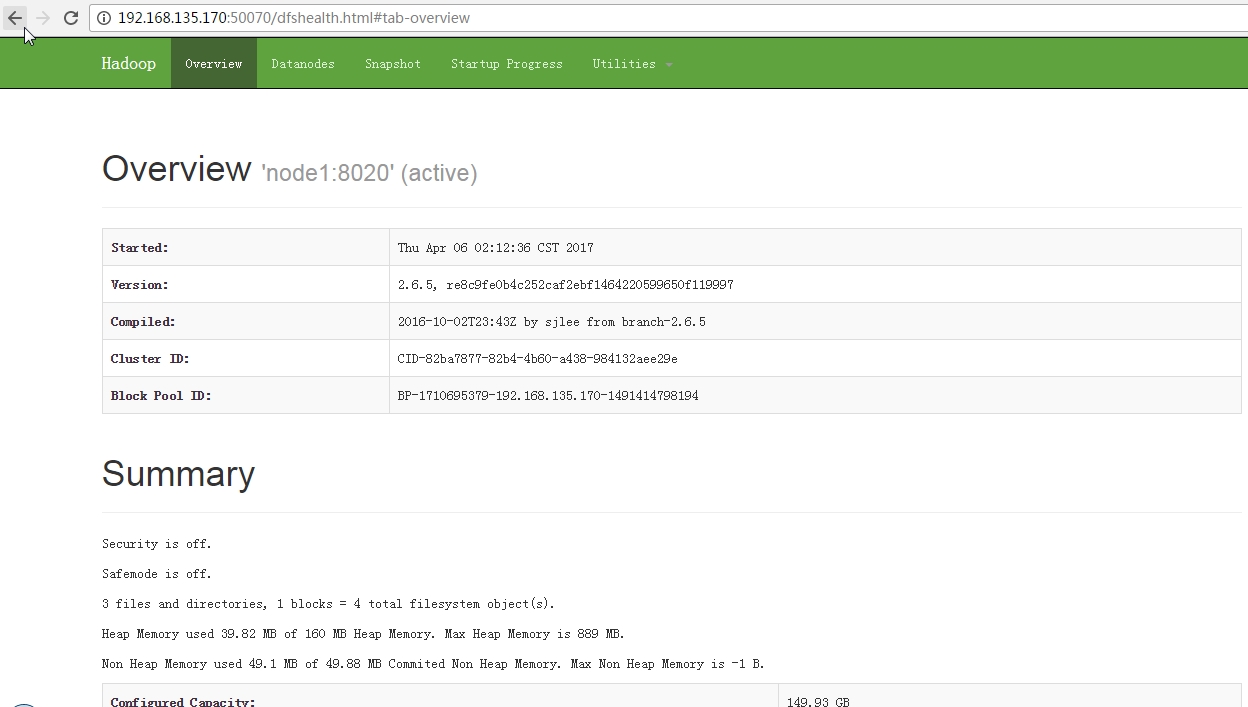
11、查看WebUI
$ netstat -tnlp
a、HDFS的WebUI
http://192.168.135.170:50070
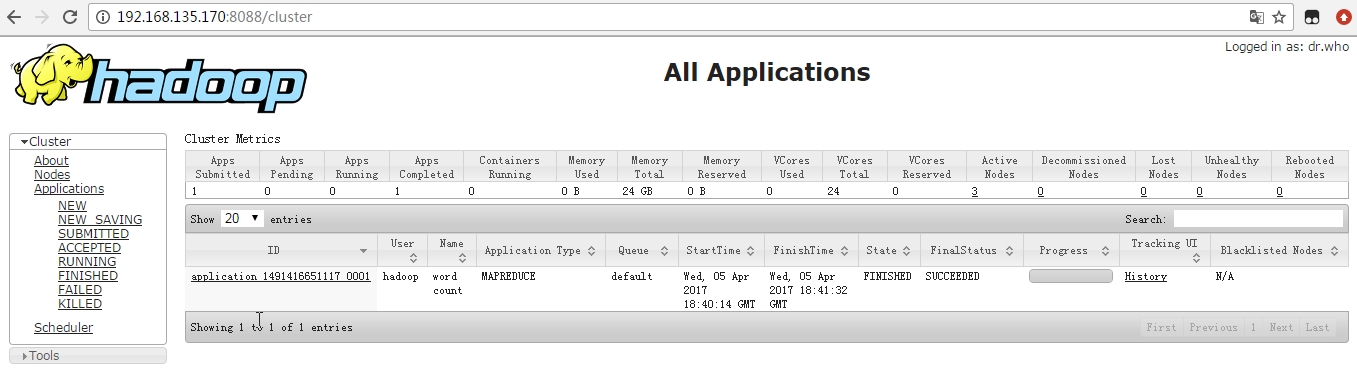
b、yarn的WebUI
http://192.168.135.170:8088
12、运行测试程序
# su - hdfs
$ cd /bdapps/hadoop/share/hadoop/mapreduce
$ yarn jar hadoop-mapreduce-examples-2.6.5.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
$ yarn jar hadoop-mapreduce-examples-2.6.5.jar wordcount /test/fstab /test/fstab.out
17/04/06 02:40:06 INFO client.RMProxy: Connecting to ResourceManager at /192.168.135.170:8032
17/04/06 02:40:12 INFO input.FileInputFormat: Total input paths to process : 1
17/04/06 02:40:12 INFO mapreduce.JobSubmitter: number of splits:1
17/04/06 02:40:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1491416651117_0001
17/04/06 02:40:14 INFO impl.YarnClientImpl: Submitted application application_1491416651117_0001
17/04/06 02:40:17 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1491416651117_0001/
17/04/06 02:40:17 INFO mapreduce.Job: Running job: job_1491416651117_0001
17/04/06 02:40:47 INFO mapreduce.Job: Job job_1491416651117_0001 running in uber mode : false
17/04/06 02:40:47 INFO mapreduce.Job: map 0% reduce 0%
17/04/06 02:41:19 INFO mapreduce.Job: map 100% reduce 0%
17/04/06 02:41:33 INFO mapreduce.Job: map 100% reduce 100%
17/04/06 02:41:34 INFO mapreduce.Job: Job job_1491416651117_0001 completed successfully
17/04/06 02:41:34 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=585
FILE: Number of bytes written=215501
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=644
HDFS: Number of bytes written=419
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=29830
Total time spent by all reduces in occupied slots (ms)=10691
Total time spent by all map tasks (ms)=29830
Total time spent by all reduce tasks (ms)=10691
Total vcore-milliseconds taken by all map tasks=29830
Total vcore-milliseconds taken by all reduce tasks=10691
Total megabyte-milliseconds taken by all map tasks=30545920
Total megabyte-milliseconds taken by all reduce tasks=10947584
Map-Reduce Framework
Map input records=12
Map output records=60
Map output bytes=648
Map output materialized bytes=585
Input split bytes=103
Combine input records=60
Combine output records=40
Reduce input groups=40
Reduce shuffle bytes=585
Reduce input records=40
Reduce output records=40
Spilled Records=80
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=281
CPU time spent (ms)=8640
Physical memory (bytes) snapshot=291602432
Virtual memory (bytes) snapshot=4209983488
Total committed heap usage (bytes)=149688320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=541
File Output Format Counters
Bytes Written=419
$ hdfs dfs -ls /test/fstab.out
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2017-04-06 02:41 /test/fstab.out/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 419 2017-04-06 02:41 /test/fstab.out/part-r-00000
$ hdfs dfs -cat /test/fstab.out/part-r-00000
# 7
'/dev/disk' 1
/ 1
/boot 1
/dev/mapper/cl-home 1
/dev/mapper/cl-root 1
/dev/mapper/cl-swap 1
/etc/fstab 1
/home 1
0 8
01:15:45 1
11 1
2017 1
Accessible 1
Created 1
Mar 1
Sat 1
See 1
UUID=b76be3cf-613c-478a-ab8b-d1eaa67a061a 1
anaconda 1
and/or 1
are 1
blkid(8) 1
by 2
defaults 4
filesystems, 1
findfs(8), 1
for 1
fstab(5), 1
info 1
maintained 1
man 1
more 1
mount(8) 1
on 1
pages 1
reference, 1
swap 2
under 1
xfs 3