一、多边形的扫描转换
一、
1、定义:把多边形的顶点表示转化为点阵表示(就是已知多边形的边界,如何找到多边形内部的点,即把多边形内部填上颜色)
2、表示方法:顶点表示和点阵表示
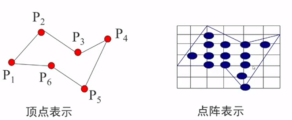
3.顶点表示:是用多边形的顶点序列来表示多边形。
优点:这种表示直观、几何意义强。占内存少,易于进行几何变换。
缺点:没有明确指出哪些像素在多边形内,故不能直接用于面着色。
4、点阵表示:用位于多边形内的像素集合来刻画多边形
优点:是光栅显示系统显示时所需的表现形式
缺点:丢失了许多几何信息(如边界,顶点等)
5.多边形分类:
1>凸多边形:任意两点的连线均在多边形内
2>凹多边形:两顶点的连线有可能不在多边形内
3>含内环的多边形:多边形内包含多边形
多边形扫描算法对这三种多变形均应满足。
二、X-扫描线算法
1、基本思想:按扫描线顺序,计算扫描线与多边形的相交区间,再用要求的颜色显示这些区间的像素,即完成填充工作。
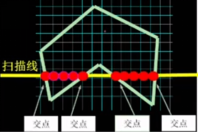
2、算法核心:按X递增顺序排列交点的X坐标序列
3、算法步骤:
1>确定多边形所占有的最大扫描线数,得到多边形顶点的最小和最大的y值
2>从Ymin到Ymax,每次用一条扫描线进行填充
3>对一条扫描线进行填充可分为4个步骤:
A、求交:计算扫描线与多边形各边的交点
B、排序:把所有交点按递增顺序进行排序
C、交点配对:交点的个数应保证为偶数个
D、区间填色:把相交区间内的像素置成填充色
4、当扫描线与多边形顶点相交时,交点的取舍问题:
1>若共享顶点的两条边分别落在扫描线的两边,交点算一个
2>若共享顶点的两条边在扫描线的同一边,交点算零个或两个(检查若共享顶点的两条边的另外两个端点的y值,若在共享顶点的下方,则算0,在上方,则算2)
举例计算交点个数:
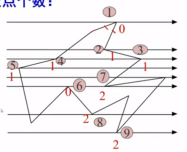
5、为了计算每条扫描线与多边形各边的交点,最简单的方法是把多边形的所有边放在一个表中。在处理每条扫描线时,按顺序从表中取出所有的边,分别于扫描线求交
但是效率极低(求交计算量大,比如说有100个多边形,每个多边形有5条边,就要算100*5*768次求交运算)
所以尽量不求交!
三、改进的X-扫描线算法
1、从三方面考虑改进:
1>在处理扫描线时,仅对与它相交的多边形边(有效边)进行求交运算
2>考虑扫描线的连贯性:即当前扫描线与各边的交点顺序与下一条扫描线与各边的交点顺序相同或相似

3>考虑多边形的连贯性:即当某条边与当前扫描线相交时,它很可能也与下一条扫描线相交
为避免求交运算,引入一种数据结构:
(1)活性边表:把与当前扫描线相交的边称为活性边(有效边),并把他们按与扫描线交点x坐标递增的顺序存放在一个链表中。
(2)结点内容:
X:当前扫描线与边的交点坐标
△x:从当前扫描线到下一条扫描线间x的增量
Ymax:该边所交的最高扫描线的坐标值Ymax

2、增量的值
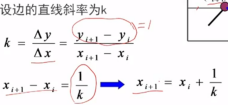
△x=1/k(即从当前扫描线到下一条扫描线间x的增量为当前直线的斜率的倒数)
另外需要知道一条边何时不再与下一条扫描线相交,以便及时把它从有效边表中删除出去,避免下一步无谓的计算,这也是Ymax的作用。
例如:
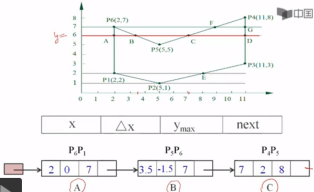
3.新边表
为了方便活性边表的建立与更新,需构造一个新边表,用来存放多边形边的信息,分为4个步骤
1>首先构造一个纵向链表,链表的长度为多边形所占有的最大扫描线数,链表的每个结点,称为一个吊桶,对应多边形覆盖的每一条扫描线。
2>新边表存放该扫描线第一次出现的边
存放Ymax,该边低点的X坐标,△x=1/k,next

例子:
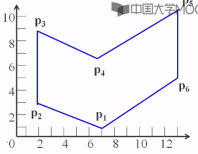
结果如下:

在这个表里只有1,3,5,7,处有边,从y=1开始,而在1扫描线上有两条边进来,然后就把两条边放进活性边表来处理。
每做一次新的扫描线时,要对已有的便进行三个处理:
1、是否被去除掉(不是活性边)
2、若没有,则对其数据更新x值,加上1/k
3、看是否有新边进来,新的边在新边表里
避免了求交运算!
四、多边形扫描转换算法小结
扫描转换算法可以实现已知任意多边形域边界的填充。该填充算法是按扫描线的顺序,计算扫描线与待填充区域的相交区间,再用要求的颜色显示这些区间的像素,即完成填充工作。
为了提高算法效率:
1>增量的思想
2>连贯性思想
3>构建了一套特殊的数据结构
缺点:无法实现对未知边界的区间填充