Extracting & Submitting Forms Automatically
Target website:http://10.0.0.45/dvwa/vulnerabilities/xss_r/
Class Scanner.
#!/usr/bin/env python import requests import re from bs4 import BeautifulSoup from urllib.parse import urljoin class Scanner: def __init__(self, url, ignore_links): self.session = requests.Session() self.target_url = url self.target_links = [] self.links_to_ignore = ignore_links def extract_links_from(self, url): response = self.session.get(url) return re.findall('(?:href=")(.*?)"', response.content.decode(errors='ignore')) def crawl(self, url=None): if url == None: url = self.target_url href_links = self.extract_links_from(url) for link in href_links: link = urljoin(url, link) if "#" in link: link = link.split("#")[0] if self.target_url in link and link not in self.target_links and link not in self.links_to_ignore: self.target_links.append(link) print(link) self.crawl(link) def extract_forms(self, url): response = self.session.get(url) parsed_html = BeautifulSoup(response.content.decode(), features="lxml") return parsed_html.findAll("form") def submit_form(self, form, value, url): action = form.get("action") post_url = urljoin(url, action) method = form.get("method") inputs_list = form.findAll("input") post_data = {} for input in inputs_list: input_name = input.get("name") input_type = input.get("type") input_value = input.get("value") if input_type == "text": input_value = value post_data[input_name] = input_value if method == "post": return requests.post(post_url, data=post_data) return self.session.get(post_url, params=post_data)
Vulnerability scanner.
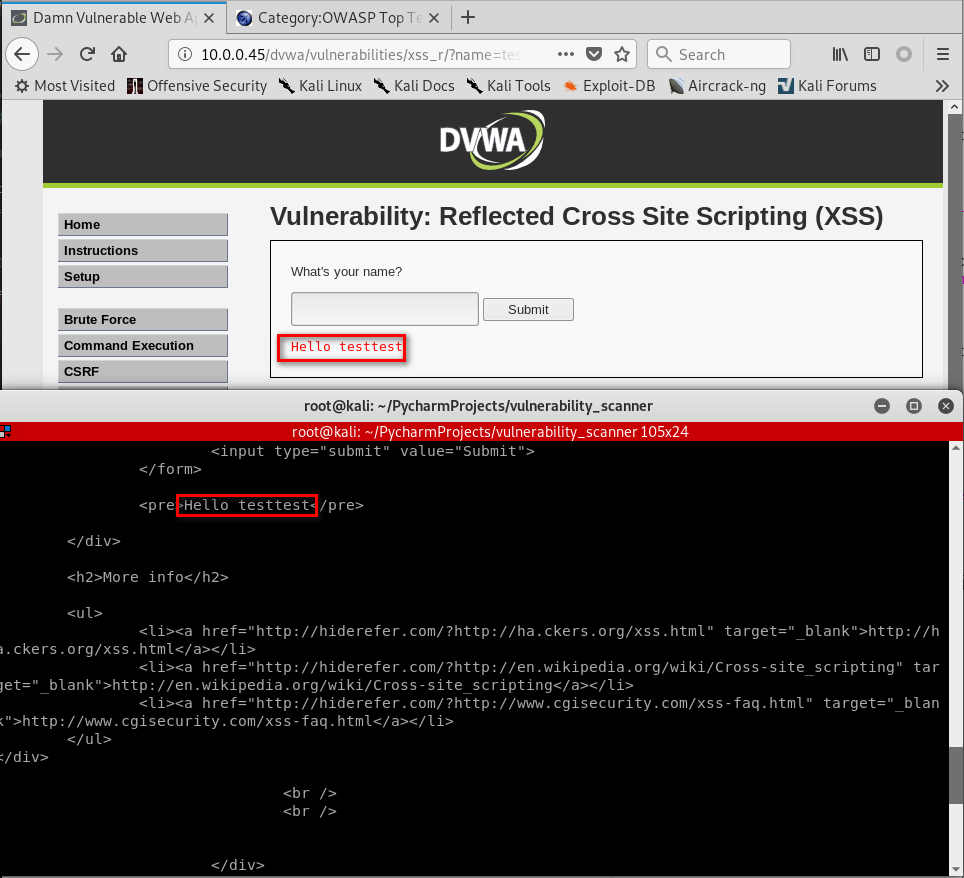
#!/usr/bin/env python import scanner target_url = "http://10.0.0.45/dvwa/" links_to_ignore = "http://10.0.0.45/dvwa/logout.php" data_dict = {"username": "admin", "password": "password", "Login": "submit"} vuln_scanner = scanner.Scanner(target_url, links_to_ignore) vuln_scanner.session.post("http://10.0.0.45/dvwa/login.php", data=data_dict) # vuln_scanner.crawl() forms = vuln_scanner.extract_forms("http://10.0.0.45/dvwa/vulnerabilities/xss_r/") print(forms) response = vuln_scanner.submit_form(forms[0], "testtest", "http://10.0.0.45/dvwa/vulnerabilities/xss_r/") print(response.content.decode())
The program runs fine.
Polish the Class Scanner to a generic scanner.
#!/usr/bin/env python import requests import re from bs4 import BeautifulSoup from urllib.parse import urljoin class Scanner: def __init__(self, url, ignore_links): self.session = requests.Session() self.target_url = url self.target_links = [] self.links_to_ignore = ignore_links def extract_links_from(self, url): response = self.session.get(url) return re.findall('(?:href=")(.*?)"', response.content.decode(errors='ignore')) def crawl(self, url=None): if url == None: url = self.target_url href_links = self.extract_links_from(url) for link in href_links: link = urljoin(url, link) if "#" in link: link = link.split("#")[0] if self.target_url in link and link not in self.target_links and link not in self.links_to_ignore: self.target_links.append(link) print(link) self.crawl(link) def extract_forms(self, url): response = self.session.get(url) parsed_html = BeautifulSoup(response.content.decode(), features="lxml") return parsed_html.findAll("form") def submit_form(self, form, value, url): action = form.get("action") post_url = urljoin(url, action) method = form.get("method") inputs_list = form.findAll("input") post_data = {} for input in inputs_list: input_name = input.get("name") input_type = input.get("type") input_value = input.get("value") if input_type == "text": input_value = value post_data[input_name] = input_value if method == "post": return requests.post(post_url, data=post_data) return self.session.get(post_url, params=post_data) def run_scanner(self): for link in self.target_links: forms = self.extract_forms(link) for form in forms: print("[+] Testing form in " + link) if "=" in link: print("[+] Testing " + link)