1. 数据组织的维度
从一个数据到一组数据
一个数据表达一个含义,一组数据表达一个或多个含义。

维度:一组数据的组织形式
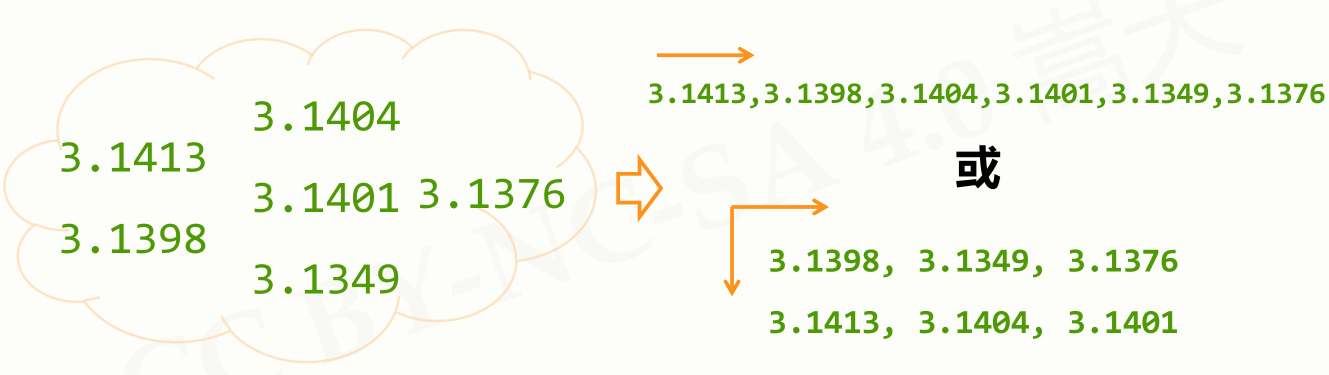
上图中右上部分是采用线性方式进行组织,右下部分是采用二维方式进行组织。
一维数据
由对等关系的有序或无序数据构成,采用线性方式组织。如:
3.1413, 3.1398, 3.1404, 3.1401, 3.1349, 3.1376
对应列表、数组和集合等概念
二维数据
由多个一维数据构成,是一维数据的组合形式。如下面的中国大学排行榜:
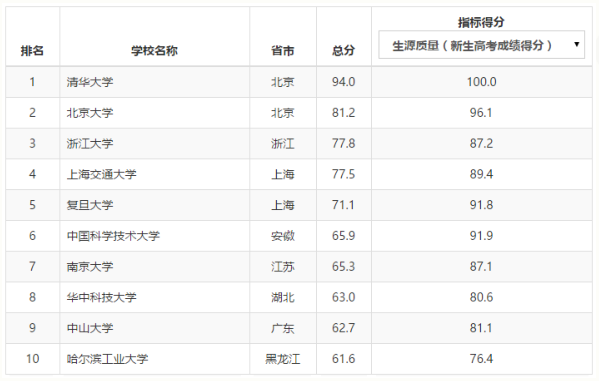
表格是典型的二维数据。其中,表头是二维数据的一部分
多维数据
由一维或二维数据在新维度上扩展形成。比如中国大学排行榜,在时间维度上又分为2016年、2017年、2018年的排行榜,在时间维度的扩展就变成了多维数据。
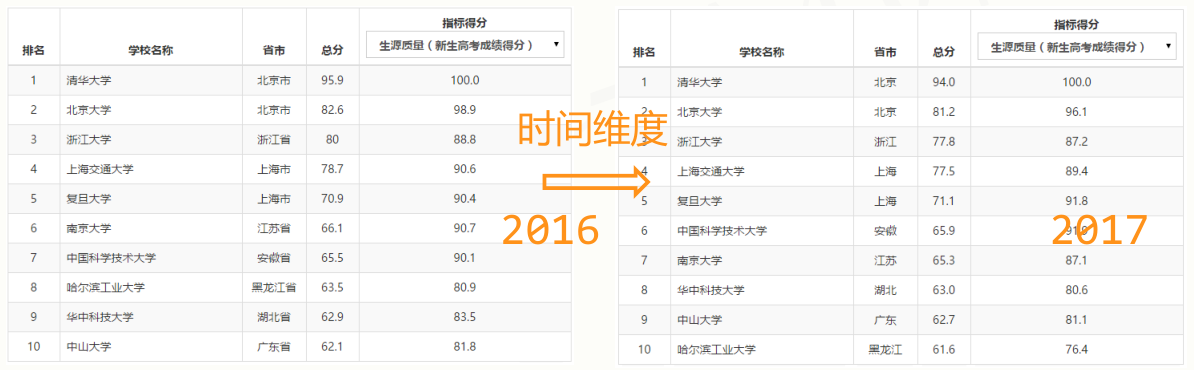
高维数据
仅利用最基本的二元关系展示数据间的复杂结构。例如字典中的键值对:
{
"firstName": "Tian",
"lastName": "Song",
"address": {
"streetAddr": "中关村南大街5号",
"city": "北京市",
"zipcode": "100081"
},
"professional": ["Computer Networking", "Security"]
}
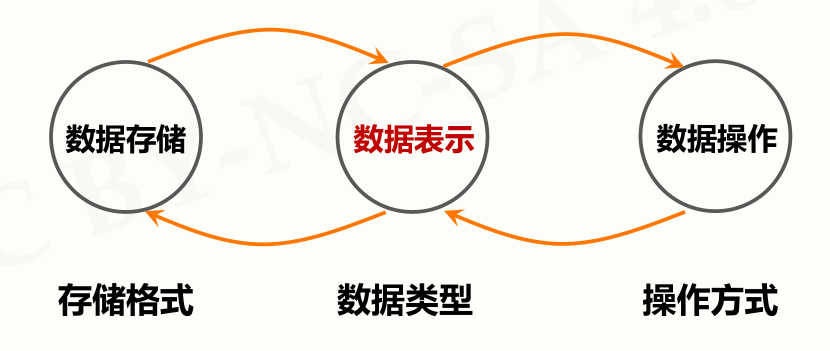
数据的操作周期
由于数据必须存在才能进行处理,所以将数据分为以下3个阶段:
存储 <-> 表示 <-> 操作
2.一维数据的表示
如果数据间有序:使用列表类型
ls = [3.1398, 3.1349, 3.1376]
列表类型可以表达一维有序数据
for循环可以遍历数据,进而对每个数据进行处理
如果数据间无序:使用集合类型
st = {3.1398, 3.1349, 3.1376}
集合类型可以表达一维无序数据
for循环可以遍历数据,进而对每个数据进行处理
3. 一位数据的存储
存储方式一:空格分隔
如:
中国 美国 日本 德国 法国 英国 意大利
使用一个或多个空格分隔进行存储,不换行
缺点:数据中不能存在空格
存储方式二:逗号分隔
如:
中国,美国,日本,德国,法国,英国,意大利
使用英文半角逗号分隔数据进行存储,不换行
缺点:数据中不能有英文逗号
存储方式三:其他方式
如:
中国$美国$日本$德国$法国$英国$意大利
使用其他符号或符号组合分隔,建议采用特殊符号
缺点:需要根据数据特点定义,通用性较差
4. 一维数据的处理
这里处理是指一维数据的存储格式和一维数据的列表或者集合的表示方式之间的一种转换。
存储 <-> 表示
将存储的数据读入程序
将程序表示的数据写入文件
一维数据的读入处理
实例:从空格分隔的文件中读入数据
中国 美国 日本 德国 法国 英国 意大利
txt = open(fname).read()
ls = txt.split()
f.close()
>>> ls
['中国', '美国', '日本', '德国', '法国', '英国', '意大利']
实例:从特殊符号分隔的文件中读入数据
中国$美国$日本$德国$法国$英国$意大利
txt = open(fname).read()
ls = txt.split("$")
f.close()
>>> ls
['中国', '美国', '日本', '德国', '法国', '英国', '意大利']
一维数据的写入处理
实例:采用空格分隔方式将数据写入文件
ls = ['中国', '美国', '日本']
f = open(fname, 'w')
f.write(' '.join(ls))
f.close()
实例:采用特殊分隔方式将数据写入文件
ls = ['中国', '美国', '日本']
f = open(fname, 'w')
f.write('$'.join(ls))
f.close()
以上内容资料均来源于中国大学MOOC网-北京理工大学Python语言程序设计课程
课程地址:https://www.icourse163.org/course/BIT-268001