转载自博客:https://www.sohu.com/a/445563555_198222

说了一个案例是为了说明如何去考量一个Kafka集群的部署,算是一个参考吧,毕竟大家在不同的公司工作肯定也会有自己的一套实施方案。
这次我们再回到原理性的问题,这次会延续 的风格,带领大家把图一步一步画出来。
Kafka的Producer原理
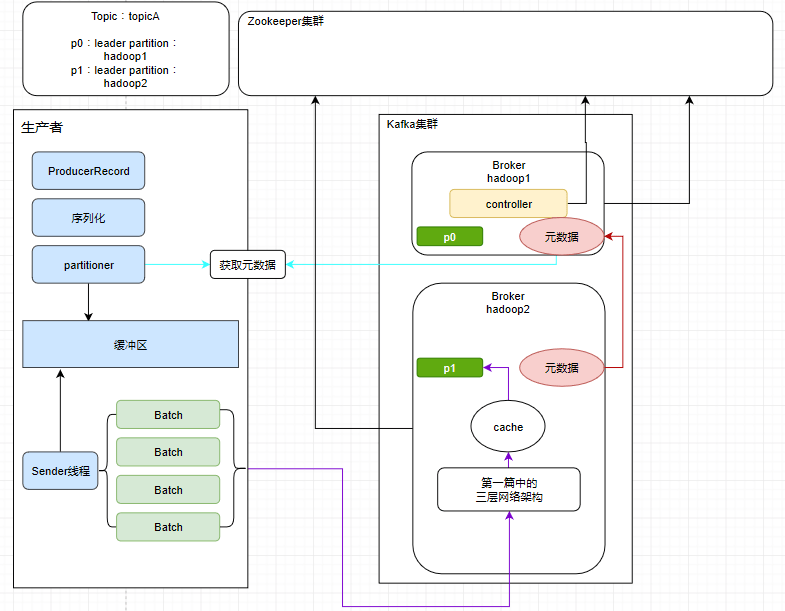
首先我们得先有个集群吧,然后集群中有若干台服务器,每个服务器我们管它叫Broker,其实就是一个个Kafka进程。
如果大家还记得 第一篇 的内容,就不难猜出来,接下来肯定会有一个controller和多个follower,还有个ZooKeeper集群,一开始我们的Broker都会注册到我们的ZooKeeper集群上面。
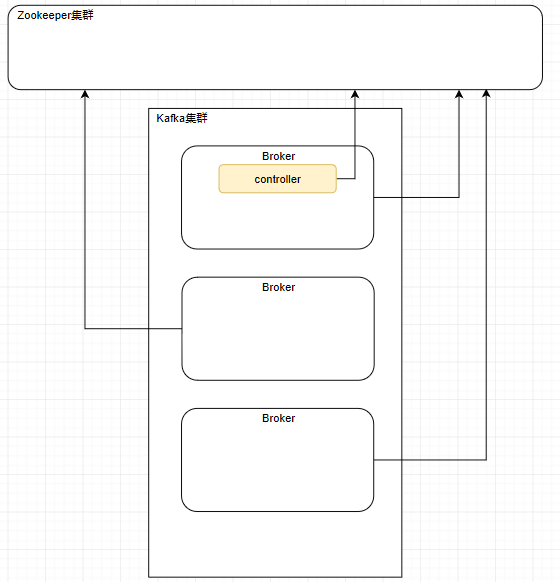
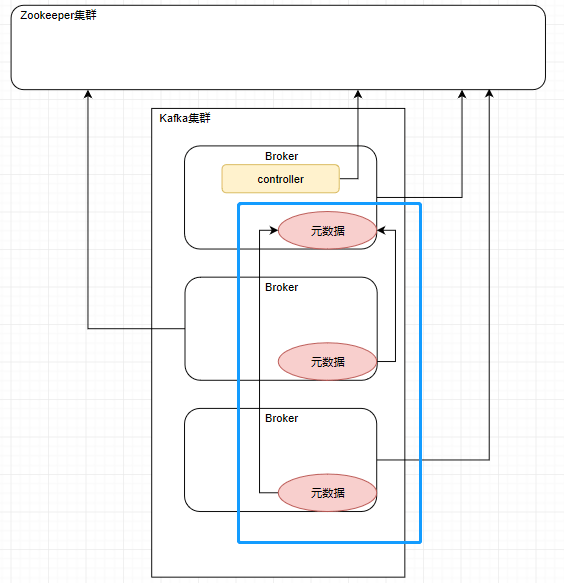
然后controller也会监听ZooKeeper集群的变化,在集群产生变化时更改自己的元数据信息。并且follower也会去它们的老大controller那里去同步元数据信息,所以一个Kafka集群中所有服务器上的元数据信息都是一致的。
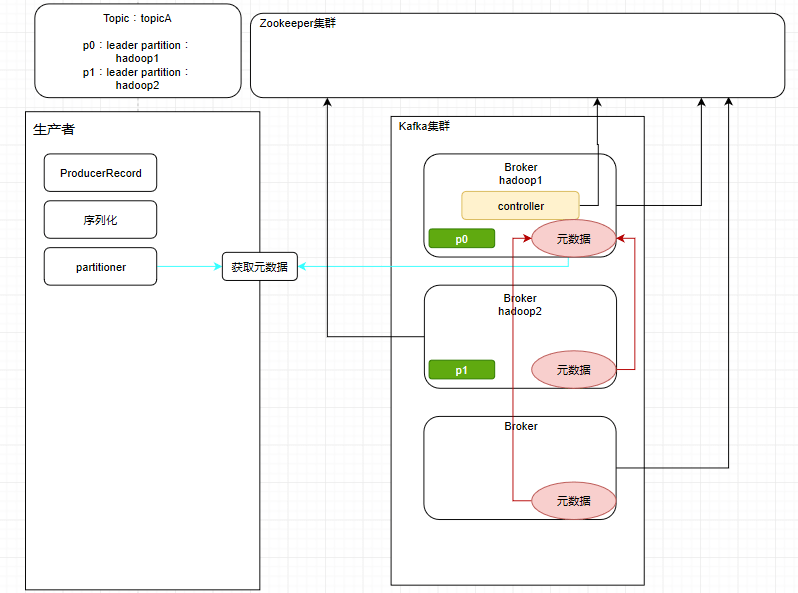
上述准备完成后,我们正式开始我们生产者的内容。
名词1——ProducerRecord
生产者需要往集群发送消息前,要先把每一条消息封装成ProducerRecord对象,这是生产者内部完成的。之后会经历一个序列化的过程。之前好几篇专栏也是有提到过了,需要经过网络传输的数据都是二进制的一些字节数据,需要进行序列化才能传输。
此时就会有一个问题,我们需要把消息发送到一个Topic下的一个leader partition中,可是生产者是怎样get到这个topic下哪个分区才是leader partition呢?
可能有些小伙伴忘了,提醒一下,controller可以视作为broker的领导,负责管理集群的元数据,而leader partition是做负载均衡用的,它们会分布式地存储在不同的服务器上面。集群中生产数据也好,消费数据也好,都是针对leader partition而操作的。
名词2——partitioner
怎么知道哪个才是leader partition,只需要获取到元数据不就好了嘛。
说来要怎么获取元数据也不难,只要随便找到集群下某一台服务器就可以了(因为集群中的每一台服务器元数据都是一样的)。
名词3——缓冲区
此时生产者不着急把消息发送出去,而是先放到一个缓冲区。
名词4——Sender
把消息放进缓冲区之后,与此同时会有一个独立线程Sender去把消息分批次包装成一个个Batch,不难想到如果Kafka真的是一条消息一条消息地传输,一条消息就是一个网络连接,那性能就会被拉得很差。为了提升吞吐量,所以采取了分批次的做法。
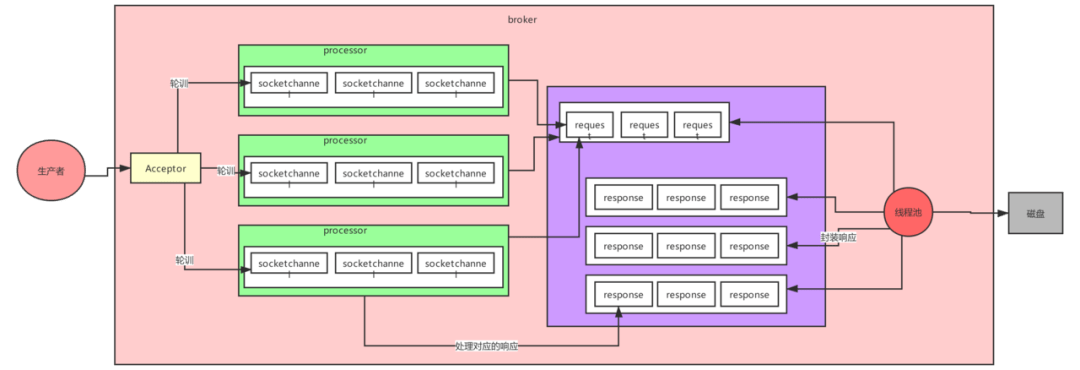
整好一个个batch之后,就开始发送给对应的主机上面。此时经过第一篇所提到的Kakfa的网络设计中的模型,然后再写到os cache,再写到磁盘上面。
下图是当时我们已经说明过的Kafka网络设计模型。
生产者代码
设置参数部分
创建生产者实例
// 创建一个Producer实例:线程资源,跟各个broker建立socket连接资源
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
创建消息
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-value");
当然你也可以指定一个key,作用之后会说明:
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-key", "test-value");
发送消息
带有一个回调函数,如果没有异常就返回消息发送成功。
// 这是异步发送的模式
producer.send(record, new Callback{
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
// 消息发送成功
System.out.println( "消息发送成功");
} else{
// 消息发送失败,需要重新发送
}
}
});
Thread.sleep(10 * 1000);
// 这是同步发送的模式(是一般不会使用的,性能很差,测试可以使用)
// 你要一直等待人家后续一系列的步骤都做完,发送消息之后
// 有了消息的回应返回给你,你这个方法才会退出来
producer.send(record).get;
关闭连接
producer.close;
干货时间:调优部分的代码
区分是不是一个勤于思考的打字员的部分其实就是在1那里还没有讲到的那部分调优,一个个拿出来单独解释,就是下面这一大串。
acks 消息验证
props.put( "acks", "-1");
| acks | 消息发送成功判断 |
| -1 | leader & all follower接收 |
| 1 | leader接收 |
| 0 | 消息发送即可 |
这个acks参数有3个值,分别是-1,0,1,设置这3个不同的值会成为kafka判断消息发送是否成功的依据。Kafka里面的分区是有副本的,如果acks为-1.则说明消息在写入一个分区的leader partition后,这些消息还需要被另外所有这个分区的副本同步完成后,才算发送成功(对应代码就是输出System.out.println("消息发送成功")),此时发送数据的性能降低。
如果设置acks为1,需要发送的消息只要写入了leader partition,即算发送成功,但是这个方式存在丢失数据的风险,比如在消息刚好发送成功给leader partition之后,这个leader partition立刻宕机了,此时剩余的follower无论选举谁成为leader,都不存在刚刚发送的那一条消息。
如果设置acks为0,消息只要是发送出去了,就默认发送成功了。啥都不管了。
retries 重试次数(重要)
这个参数还是非常重要的,在生产环境中是必须设置的参数,为设置消息重发的次数。
props.put( "retries", 3);
在Kafka中可能会遇到各种各样的异常(可以直接跳到下方的补充异常类型),但是无论是遇到哪种异常,消息发送此时都出现了问题,特别是网络突然出现问题,但是集群不可能每次出现异常都抛出,可能在下一秒网络就恢复了呢,所以我们要设置重试机制。
这里补充一句:设置了retries之后,集群中95%的异常都会自己乘风飞去,我真没开玩笑!
代码中我配置了3次,其实设置5~10次都是合理的,补充说明一个,如果我们需要设置隔多久重试一次,也有参数,没记错的话是retry.backoff.ms,下面我设置了100毫秒重试一次,也就是0.1秒。
props.put( "retry.backoff.ms",100);
batch.size 批次大小
批次的大小默认是16K,这里设置了32K,设置大一点可以稍微提高一下吞吐量,设置这个批次的大小还和消息的大小有关,假设一条消息的大小为16K,一个批次也是16K,这样的话批次就失去意义了。所以我们要事先估算一下集群中消息的大小,正常来说都会设置几倍的大小。
props.put( "batch.size", 32384);
linger.ms 发送时间限制
比如我现在设置了批次大小为32K,而一条消息是2K,此时已经有了3条消息发送过来,总大小为6K,而生产者这边就没有消息过来了,那在没够32K的情况下就不发送过去集群了吗?显然不是,linger.ms就是设置了固定多长时间,就算没塞满Batch,也会发送,下面我设置了100毫秒,所以就算我的Batch迟迟没有满32K,100毫秒过后都会向集群发送Batch。
props.put( "linger.ms", 100);
buffer.memory 缓冲区大小
当我们的Sender线程处理非常缓慢,而生产数据的速度很快时,我们中间的缓冲区如果容量不够,生产者就无法再继续生产数据了,所以我们有必要把缓冲区的内存调大一点,缓冲区默认大小为32M,其实基本也是合理的。
那应该如何去验证我们这时候应该调整缓冲区的大小了呢,我们可以用一般Java计算结束时间减去开始时间的方式测试,当结束时间减去开始时间大于100ms,我们认为此时Sender线程处理速度慢,需要调大缓冲区大小。
当然一般情况下我们是不需要去设置这个参数的,32M在普遍情况下已经足以应付了。
Long startTime=System.currentTime;
producer.send(record, new Callback{
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
// 消息发送成功
System.out.println( "消息发送成功");
} else{
// 消息发送失败,需要重新发送
}
}
});
Long endTime=System.currentTime;
If(endTime - startTime > 100){//说明内存被压满了
说明有问题
}
compression.type压缩方式
compression.type,默认是none,不压缩,但是也可以使用lz4压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大producer端的CPU开销。
props.put( "compression.type", lz4);
max.block.ms
留到源码时候说明,是设置某几个方法的阻塞时间。
props.put( "max.block.ms", 3000);
max.request.size最大消息大小
max.request.size:这个参数用来控制发送出去的消息的大小,默认是1048576字节,也就1M,这个一般太小了,很多消息可能都会超过1mb的大小,所以需要自己优化调整,把它设置更大一些(企业一般设置成10M),不然程序跑的好好的突然来了一条2M的消息,系统就报错了,那就得不偿失。
request.timeout.ms请求超时
request.timeout.ms:这个就是说发送一个请求出去之后,他有一个超时的时间限制,默认是30秒,如果30秒都收不到响应(也就是上面的回调函数没有返回),那么就会认为异常,会抛出一个TimeoutException来让我们进行处理。如果公司网络不好,要适当调整此参数。
props.put( "request.timeout.ms", 30000);
补充:Kafka中的异常
不管是异步还是同步,都可能让你处理异常,常见的异常如下:
- LeaderNotAvailableException:这个就是如果某台机器挂了,此时leader副本不可用,会导致你写入失败,要等待其他follower副本切换为leader副本之后,才能继续写入,此时可以重试发送即可。如果说你平时重启kafka的broker进程,肯定会导致leader切换,一定会导致你写入报错,是LeaderNotAvailableException
- NotControllerException:这个也是同理,如果说Controller所在Broker挂了,那么此时会有问题,需要等待Controller重新选举,此时也是一样就是重试即可
- NetworkException:网络异常,重试即可。我们之前配置了一个参数,retries,他会自动重试的,但是如果重试几次之后还是不行,就会提供Exception给我们来处理了。
参数:retries 默认值是3
参数:retry.backoff.ms 两次重试之间的时间间隔
总结
上面从生产者生产消息到发送这一个流程分析下来,从而引出下面的各种各样关于整个过程的参数的设置,如果真的能清晰地理解好这些基础知识,相信对你必定是有所帮助。