前言
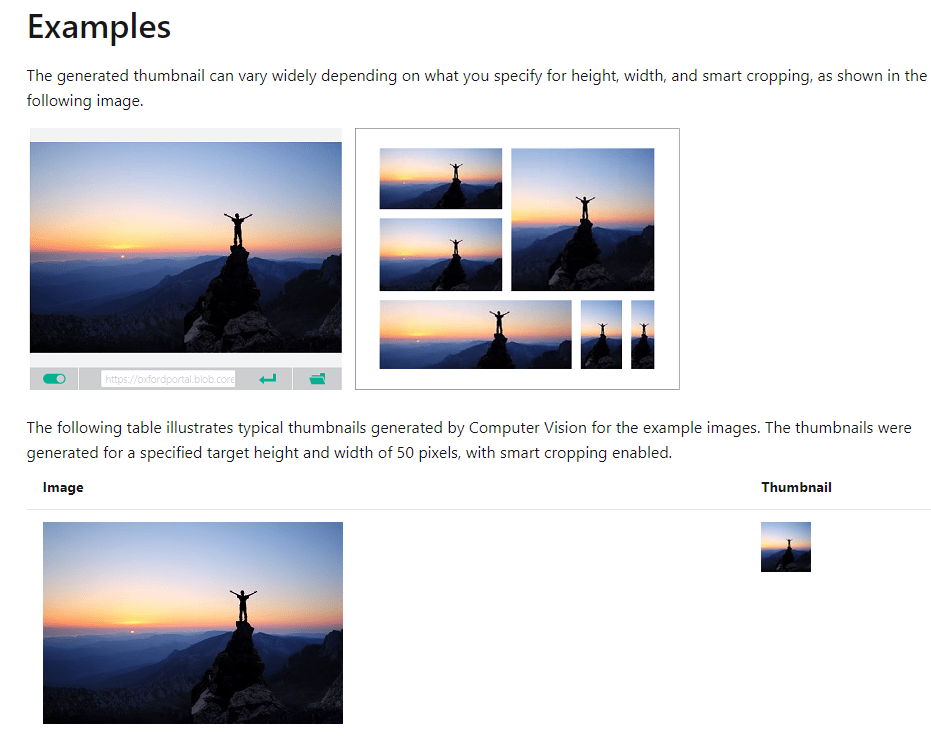
一个网站通常有许多地方会用到同一张图,但是比例又不一样.
一般的做法就是用 CSS 的 cover 和 contain 来处理.
由于 cover 只会保留中间信息, 所以很多时候需要人工裁剪.
于是就有了智能裁剪的需求了.
Azure Computer Vision
参考:
价格还可以

实现步骤
1. 到 Azure portal 创建 Computer Vision
没有什么特别的, 默认就可以了 (注: 一个 account 只能有一个 free 的 Computer Vision 哦)
2. 进入 Computer Vision Resource > Keys and Endpoint 把 key 和 endpoint 抄起来
3. 安装 SDK
dotnet add package Microsoft.Azure.CognitiveServices.Vision.ComputerVision
2 个核心功能, 第 1 个是获取全图焦点, 第 2 个是给定要求智能裁剪
[HttpPost("SmartCrop")] public async Task<ActionResult> SmartCropAsync() { var subscriptionKey = "key"; var endpoint = "https://jbreviews-cv.cognitiveservices.azure.com/"; var client = new ComputerVisionClient(new ApiKeyServiceClientCredentials(subscriptionKey)) { Endpoint = endpoint }; var imageFileFullPath = @"WebApiControllerTestSmartCrop10.png"; using var imageStream = new FileStream(imageFileFullPath, FileMode.Open); // get area of interest var areaOfInterestResult = await client.GetAreaOfInterestInStreamAsync(imageStream); // 这里返回之后 imageStream 就自动被 close 了 using var image = Image.Load(imageFileFullPath); var croppedImage = image.Clone(imageProcessing => { imageProcessing.Crop(new Rectangle( x: areaOfInterestResult.AreaOfInterest.X, y: areaOfInterestResult.AreaOfInterest.Y, areaOfInterestResult.AreaOfInterest.W, height: areaOfInterestResult.AreaOfInterest.H) ); }); croppedImage.SaveAsJpeg( @"WebApiControllerTestSmartCrop11.png", new SixLabors.ImageSharp.Formats.Jpeg.JpegEncoder { Quality = 85 } ); // get smart crop image using var imageStream2 = new FileStream(imageFileFullPath, FileMode.Open); var croppedImageStream = await client.GenerateThumbnailInStreamAsync(300, 100, imageStream2, smartCropping: true); using var imageFileStream = System.IO.File.Create(@"WebApiControllerTestSmartCrop12.png"); croppedImageStream.CopyTo(imageFileStream); return Ok(); }
缺陷
GetAreaOfInterest 可以获取到一张图的焦点, 这个焦点并不是指人脸, 它只是去掉背景,保留主题而已.
比如这张杨幂图, 焦点就是中间的部分

结果:

如果再拿这张图去找焦点, 返回的结果是一样的, 并不会返回杨幂的脸, 所以它并不会一只往下找焦点中的焦点.
使用 GenerateThumbnail 可以指定一个 width 和 height. 它会通过找到 interest 之后再调整 zoom 然后 crop.
如果需求是 100x100 那么结果依然是上面这张焦点图, 只是被压缩到 100x100 而已. 它会尽可能保留焦点的全部信息.
如果限制是 400x100 那么它就没办法调整 zoom 了. 这个时候它只能取舍掉焦点图的信息. 类似 css cover 的做法.
而由于它没有办法识别出焦点的焦点, 所以它只能从中心点开始, 结果就和 css cover 一模一样的效果了

由人处理的话应该是这样的:

所以它并不能没有想象中的智能.