必知必会13条
1. all() 查询所有结果 2. get(**kwargs) 返回筛选条件匹配的对象,返回结果只有一个(没有匹配到或者撇屁了多个会报错) 3. filter(**kwargs) 它包含了与所给条件相匹配的对象 4. exclude(**kwargs) 它包含了与所给筛选条件不匹配的对象 5. values(*field) 返回一个ValueQuerySet----一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列 6. vaules_list(*field) 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 7. order_by 对查询结果排序 8. reverse() 对查询结果反向排序,注意:reverse()通常只能在具有已定义顺序的QuerySet上调用 9. distinct() 从返回结果中提出重复记录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果.此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重) 10. count() 返回数据库中匹配查询的对象数量 11. first() 返回第一条记录 12. last() 返回最后一条记录 13. exists() 如果QuerySet包含数据,就返回True,否则返回False
返回QuerySet对象的方法有
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QEuerySet
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元组序列
返回具体对象的
get() first() last()
返回布尔值的
exists()
返回数字的方法
count()
单表查询值神奇的双下划线
models.Tb1.object.filter(id__lt=10,id__gt=1) #获取id大于1,且 小于10的值 models.Tb1.objects.filter(id_in=[11,22,33]) #获取id等于11,22,33的数据 models.Tb1.objects.exclude(id_in=[11,22,33]) # not in 排除不包括 models.Tb1.objects.filter(name_contains="ven") # 获取name字段包含"ven"的 models.Tb1.objects.filter(name_icontains="ven") #获取name中包含ven的,忽略大小写 models.Tb1.object.filter(id_range=[1,3]) #id范围是1到3的,等价与SQL的between and 类似的还有: startswith .istartswith,endswith,iendswith date字段还可以: models.Class.objects.filter(first_day_year=2017)
ForeignKey操作
正向查询
对象查询(跨表)
语法:
对象,关联字段.字段
示例:
book_obj = models.Book.objects.first() # 第一本书对象 print(book_obj.publisher) #得到这本书关联的出版色对象 print(book_obj.publisher.name) #得到出版社对象的名臣
字段查询(跨表)
语法:
关联字段__字段
示例:
print(models.Book.objects.values_list("publisher_name"))
反向查询
对象查找
语法:
obj.表名_set
示例:
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象 books = publisher_obj.book_set.all() # 找到第一个出版社的所有书 titles = books.values_list("title") #找到第一个出版社出版的所有书的书名
字段查找
语法:
obj.表名_set
示例:
titles = models.Publisher.objects.values_list("book_title")
ManyToManyField
class RelatedManager
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器.
它存在于下面两种情况:
- 外键关系的反向查询
- 多对多关联关系
简单来说就是当点后面的对象可能存在多个的时候就可以使用以下的方法.
方法
create()
创建一个新的对象,保存对象,并将它添加到关键对象集之中,返回新创建的对象.
import datetime models.Author.objects.first().book_set.create(title='番茄物语',publish_date=datetime.date.today())
add()
把指定的model对象添加到关联对象集中.
添加对象
author_objs = models.Author.objects.filter(id_lt=3)
models.Book.objects.first().authors.add(*author_objs)
添加id
models.Book.objects.first().authors.add(*[1,2])
set()
更新mode对象的关联对象.
book_obj = models.Book.objects.first()
book_obj.authors.set([2,3])
remove()
从关联对象集中移除执行的model对象
book_obj = models.Book.objects.first()
book_obj.authors.remove(3)
clear()
从关联对象集中移除一切对象.
book_obj = models.Book.objects.first()
book_obj.authors.clear()
注意:
对于ForeignKey对象,clear()和remove()方法仅在null = True是存在.
ForeignKey字段设置null=True: 才有clear()和remove() 方法
ForeignKey字段没有设置null=True: 没有clear()和remove() 方法
注意:
- 对于所有类型的关联字段,add(),create(),remove(),set()都会马上更新数据库.换句话说,在关联的任何一端,都不需要再调用save()方法.
聚合查询和分组查询
聚合
aggregate()是QuerySet的一个终止子句,意思是说,它返回一个包含一些键值对的字典.
键的名称是聚合值的标识符,值是计算出来的聚合值.键的名称是按照字段和聚合函数的名称自定生成出来的.
用到的内置函数:
from django.db.models import Avg,Sum,Max,Min,Count
示例:
from django.db.models import Avg,Sum,Max,Min,Count moels>Book.objects.all().aggregate(Avg('price')) {'prive_avg':13.233333}
如果你想要为聚合值指定一个名称,可以向聚合子句提供它.
models.Book.objects.aggregate(average_price=Avg('price')) {'average_price':13.2333333}
如果你希望生成不止一个聚合,你可以向aggregate()句子中添加另外一个参数,所以,如果你也想纸袋所有图书价格的最大值和最小值,可以这样查询.
>>> models.Book.objects.all().aggregate(Avg("price"), Max("price"), Min("price")) {'price__avg': 13.233333, 'price__max': Decimal('19.90'), 'price__min': Decimal('9.90')}
分组
假设有一张员工职员表:
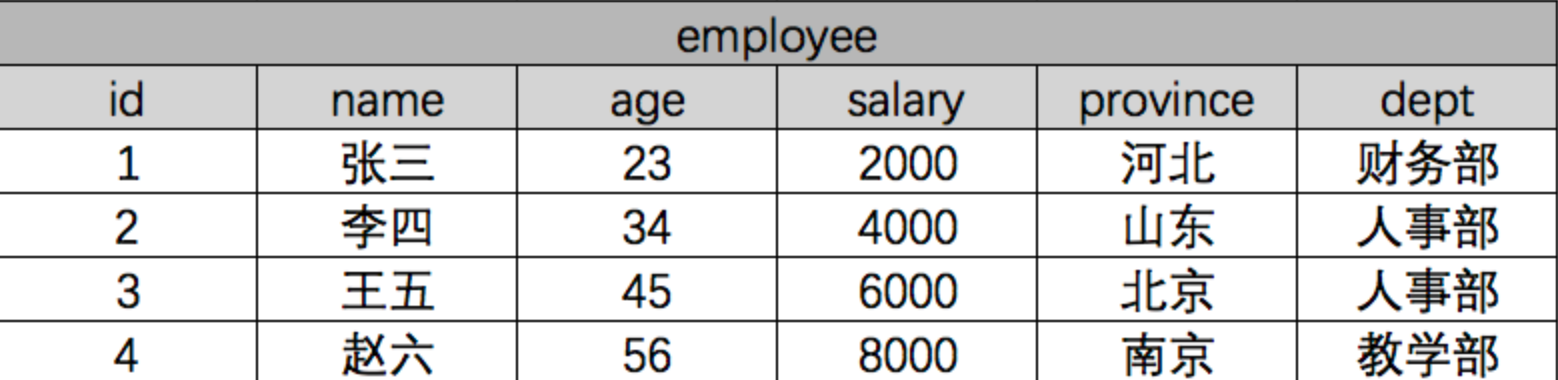
我们使用原生SQL语句,按照部门分组求平均工资:
select dept,AVG(salary) from employee group by dept;
ORM查询:
from django.db.models import Avg Employee.objects.values('dept').annotate(avg-Avg('salary')).values('dept',"avg")
连表查询的分组:
SQL查询
select dept.name,AVG(salary) from employee inner join dept on (employee.dept_id=dept.id) group by dept_id;
ORM查询:
from django.db.models import Avg models.Dept.objects.annotate(avg=Avg("employee__salary")).values("name", "avg")
更多示例
示例1:统计每一本书的作者个数
>>> book_list = models.Book.objects.all().annotate(author_num=Count("author")) >>> for obj in book_list: ... print(obj.author_num) ... 2 1 1
示例2:
>>> publisher_list = models.Publisher.objects.annotate(min_price=Min("book__price")) >>> for obj in publisher_list: ... print(obj.min_price) ... 9.90 19.90
方法二:
>>> models.Book.objects.values("publisher__name").annotate(min_price=Min("price")) <QuerySet [{'publisher__name': '沙河出版社', 'min_price': Decimal('9.90')}, {'publisher__name': '人民出版社', 'min_price': Decimal('19.90')}]>
示例3:统计不止一个作者的图书
>>> models.Book.objects.annotate(author_num=Count("author")).filter(author_num__gt=1) <QuerySet [<Book: 番茄物语>]>
示例4:根据一本图书作者数量的多少多查询集QuerySet进行排序.
>>> models.Book.objects.annotate(author_num=Count("author")).order_by("author_num") <QuerySet [<Book: 香蕉物语>, <Book: 橘子物语>, <Book: 番茄物语>]>
示例5:查询各个作者出的书的总价格
>>> models.Author.objects.annotate(sum_price=Sum("book__price")).values("name", "sum_price") <QuerySet [{'name': '小精灵', 'sum_price': Decimal('9.90')}, {'name': '小仙女', 'sum_price': Decimal('29.80')}, {'name': '小魔女', 'sum_price': Decimal('9.90')}]>
分组