我们经常在业务中会遇到无限上下级关系的表,比如组织机构表,一般来说这种表有两种设计方式,一是,表内两个字段自关联(属于物理上的关联),二是,表内根据一个字段的规律来判断(属于逻辑上的关联)
这个时候我们在查询等级关系时,第二种表设计的查询方式是: 使用 LIke '**__' 进行模糊查询,而第一种表设计方式就是 使用递归查询了,
ORACLE中可以使用 START WITH .... CONNECT BY PRIOR ... 进行递归查询,而Mysql则只能使用存储过程来执行递归查询了,递归查询网上的教程就比较多,我这里就不一一概述了,这里讲递归查询的优化
首先 我的表设计如图所示
组织表【 organization 】:
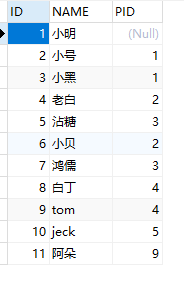
组织关系表【 organization_concern 】:
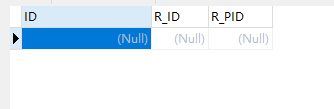
表关系一目了然,唯一有差别的是我这里多了一张关系表,当然也可以看出 organization_concern.R_ID = organization.ID organization_concern.R_PID = organization.PID
这里所做的优化 就是通过一张关联表进行连接查询 从而避免递归查询,来进行优化的!
那么这个时候我们就需要为这张关系表提供数据了,通过存储过程,因为我们不能手动去填关系
CREATE DEFINER=`root`@`%` PROCEDURE `DATA_CONVERSION`() BEGIN #所有变量应在游标前定义 #子ID集合 DECLARE STR_IDS VARCHAR(255) ; #分隔IDS集合的索引 DECLARE V_INDEX CHAR(255); DECLARE V_ID CHAR(255); #外层游标赋值变量 DECLARE S_ID INT(11); DECLARE NO_ROW_FOUND INT DEFAULT 0; #定义外层游标[定义游标,与打开游标之间尽量隔几行代码,NAVICAT可能会报错] DECLARE OUTER_CUR CURSOR FOR SELECT ID FROM organization; #错误[Err] 1329 - No data - zero rows fetched, selected, or processed 解决方式:http://blog.sina.com.cn/s/blog_544c72960101bvl3.html #需要注意的是这个HANDLER变量需要声明到游标后面[如果不加该行 游标为空的时候 就会报错] #https://blog.csdn.net/liyongshun82/article/details/52813711 CONTINUE DECLARE CONTINUE HANDLER FOR NOT FOUND SET NO_ROW_FOUND = 1; #当组织机构表发生变化时,就需要运行该存储过程,因为组织关系变化种类繁多所以需要清空关系表,再重新生成 TRUNCATE TABLE organization_concern; #打开游标 OPEN OUTER_CUR; OUTER_LOOP:Loop #这里设置为1是因为在进行字符串截取时我的字符串第一项为空字符串,所以直接略过第一项 SET V_INDEX = 1; #设为空字符串准备下次循环 SET STR_IDS =''; #SELECT '游标循环!!!'; #游标赋值 FETCH OUTER_CUR INTO S_ID; #如果游标的值为NULL,则会触发前面的异常处理HANDLER,且将NO_ROW_FOUND置为1,由于是按照CONTINUE来处理的所以代码继续执行 #此处判断NO_ROW_FOUND是否为1,如果为1则跳出循环,由于本例中游标是通过查询得到的,所以如果游标为NULL,说明游标已遍历完结果集,但令人疑惑的是mysql的存储过程遍历完结果集并不自动退出循环 IF NO_ROW_FOUND = 1 THEN #对于循环有两个操作:LEAVE表示离开循环,好比编程里面的break一样;ITERATE则继续循环,好比编程里面的continue一样。 LEAVE OUTER_LOOP; END IF; #主键变量 SET V_ID=CAST(S_ID AS CHAR); #此WHILE的作用是将传入的ID,找到它所有的子节点的ID,并将其转换成字符串放到STR_IDS中 WHILE V_ID IS NOT NULL DO SET STR_IDS= CONCAT(STR_IDS,',',V_ID); #GROUP_CONCAT(),FIND_IN_SET()函数介绍:https://www.cnblogs.com/longzhongren/p/4775293.html #需要注意的是GROUP_CONCAT()可能会数据不全,解决方式:https://blog.csdn.net/dream_broken/article/details/69554303 #这条SQL的意思是从组织表中查找PID存在V_ID字符串中的记录行, #将其ID组成新的字符串赋值给V_ID,即根据一个ID,获取该ID 下的所有子ID的集合 SELECT GROUP_CONCAT(ID) INTO V_ID FROM organization WHERE FIND_IN_SET(PID,V_ID) > 0 ; END WHILE; #如果仅仅想通过,传入ID,获取其所有的子节点,则取消注释下面这段代码,同时删掉下面的代码即可 #SELECT * from organization where FIND_IN_SET(ID,STR_IDS); #打印ID的结果 #SELECT STR_IDS; #@STR_IDS_LENGTH是获取要分割字符串[我这里是逗号]根据符号分割后的数组长度 SET @STR_IDS_LENGTH = (LENGTH(STR_IDS) - LENGTH(REPLACE(STR_IDS,',',''))) + 1; #SELECT @STR_IDS_LENGTH; WHILE V_INDEX < @STR_IDS_LENGTH DO #索引加1 SET V_INDEX = V_INDEX + 1; #根据索引截取ID SET @ID = REVERSE(SUBSTRING_INDEX(REVERSE(SUBSTRING_INDEX(STR_IDS,',',V_INDEX)),',',1)); #SELECT @ID; #插入关系表,需要注意的是游标变量就是父ID,STR_IDS是该父ID下的所有子ID的集合 INSERT INTO organization_concern (R_ID,R_PID) VALUES (@ID,S_ID); END WHILE; #终止循环 END Loop OUTER_LOOP; #去掉表中R_ID与R_PID一致的数据,一个节点的父节点不能是自己 DELETE FROM organization_concern WHERE R_ID = R_PID; #将根节点插入关系表中where条件根据自己的表设计来判断,一般是NULL或者是0等等 INSERT INTO organization_concern (R_ID,R_PID) SELECT ID,PID FROM organization where PID IS NULL; #关闭游标 CLOSE OUTER_CUR; END
我们创建了一个 名叫 DATA_CONVERSION 的存储过程,他的作用就是为关系表写入数据,他通过遍历当前所有节点,并将每个节点的所有子节点记录下来,写入到关系表中
需要注意的是,每次组织表由变动时,都需要调用这个存储过程,这个存储过程会清空关系表并重新写数据,那么为什么不修改这张关系表呢?因为组织表如果发生了改变,其变化
是不可控的[比如一个人从A部门调到B部门,或者一个升职,一个人降职,一个部门取消了等等],修改起来也十分复杂,倒不如重新生成,而且组织表一般都是读多写少的操作,所以我
们只用关心读取的性能就好了!
那么我们现在关系表中有了数据,再进行读取数据就方便多了!
直接连接查询就好了!
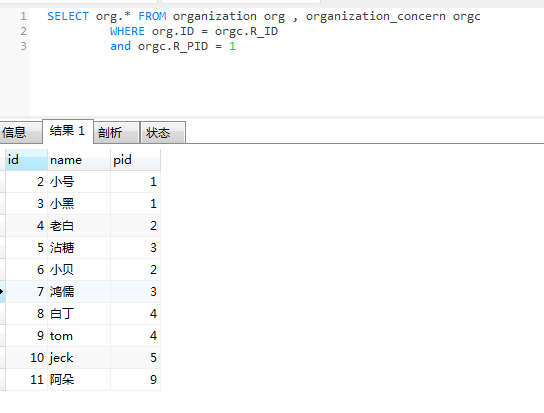
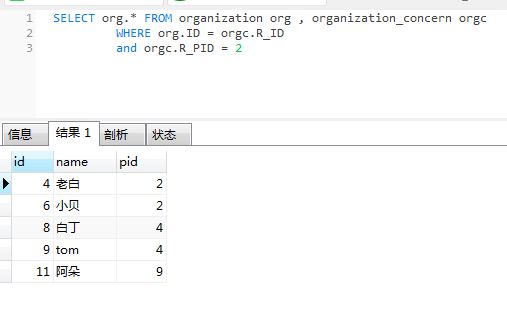
这样性能是不是比递归查询性能好很多呢?