Describing Videos by Exploiting Temporal Structure
Note here: it's a learning note on the topic of video representations.
Link: http://120.52.73.75/arxiv.org/pdf/1502.08029.pdf
Motivation:
They argue that there are two categories of temporal structure present in video:
- Local structure: fine-grained motio information that characterizes punctuated actions
- Global structure: sequence in which objects, actions, scenes and people in video.
A good video descriptor should exploit both the local and global temporal structure underlying video.
Proposed Model:
(This model aims at handling the video description problem, so the global encoding part of it is intergrated into the description decoder, which makes its representations of videos are not general for all video problems. But the idea is worthwhile to dive into)
1) Exploiting local temporal structure:
A spatio-temporal convolutional neural network (3-D CNN) which has recently been demonstrated to capture well the temporal dynamics in video clips.
(3-D CNN receive input as stack of multiple sequences of frames and apply 3D filter on it to encode the short temporal feature in the range of input sequences.)
The pipline is shown in the figure below. In order to make sure that local temporal structure (which the author regards motion features as the most important) are well extracted and to reduce the computation, they transform the raw pixel data into higher level sementic feature: HOG, HOF and MBH.
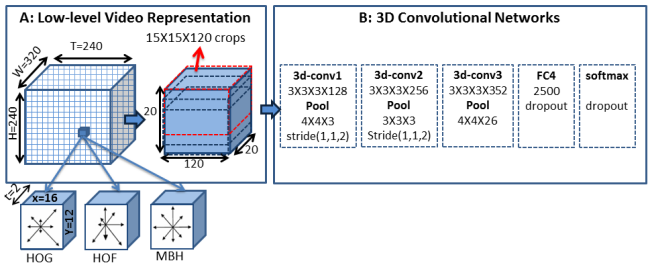
(Note that: the FC4 and softmax layer are used for training the network from scratch on activity recognition dataset, and will be removed when extracting local temporal structures.)
2) Exploiting global temporal structure:
Instead of using the vanilla LSTM framework* to encode the global structure from all local structures, this paper leverages the idea of soft attention mechanism to make the network itself looking at different local structures selectively.
(* the LSTM framework implemented in this paper is more fancier than the vanilla one, see the paper for details)
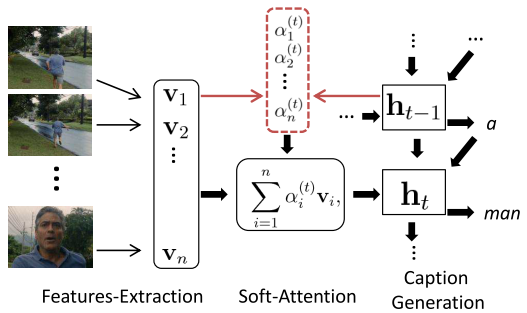
Shown as the figure above, the features-extraction part corresponds to the 3-D CNN extraction of local structures. In soft-attention part, we assign (a_{i}) ((0<=a_{i}<=1)) for each local structure (v_{i}). (a_{i}) reflects the relevance of the i-th temporal feature in the input video given all the previously generated words. And the set of (a_{i}) is computed at every time step. Lastly, soft-attention local structures are feed into LSTM to generate video description.
The computation of (a_{i}) and normalization are shown below:
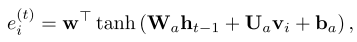
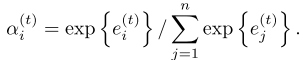
As we can see, value of new (a_{i}) set depends on the last hidden state.