做的第一个nlp任务,用的textcnn来实现推特文本分类。
任务描述

判断一个tweet是否真的再说现实里的灾难,而不是说只是用一些类似灾难的形容词。
数据预处理
import torch
import torchtext
import torch.nn as nn
import torch.utils.data as Data
import torch.nn.functional as F
torch.manual_seed(916)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
import math
import random
import time
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
import numpy as np
import pandas as pd
import re
import spacy
import texthero as th
from torchtext import vocab
from d2l import torch as d2l
train_path = '/home/wu/kaggle/pipeline/textcnn/train.csv'
test_path = '/home/wu/kaggle/pipeline/textcnn/test.csv'
embed_path = '/home/wu/kaggle/wordvec/crawl-300d-2M.vec'
submission_path = '/home/wu/kaggle/pipeline/textcnn/submission.csv'
model_path = '/home/wu/kaggle/pipeline/textcnn/default_model.pkl'
w2v = torchtext.vocab.Vectors(embed_path, max_vectors=10000) #这是我的词向量
关于这个词向量,它是如果该词不再词向量列表里就返回全0的tensor。
train = pd.read_csv(train_path)
test = pd.read_csv(test_path)
all_data = pd.concat((train, test))
all_data['text'] = th.preprocessing.clean(all_data['text'])
all_data['text'] = th.preprocessing.remove_urls(all_data['text'])
all_data['text'] = th.preprocessing.tokenize(all_data.text)
这里用到了texthero这个工具,这玩意是真的好用,数据清洗就一个命令,然后直接分词。
length = all_data.text.apply(lambda x: len(x))
length.plot.hist(bins=25) # 显示每个文本词的长度
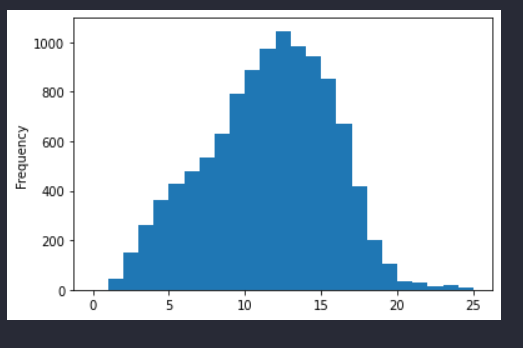
可以看到每个推文经过clean后,大部分的推文的词就在20个以下了,所以pad做就取20了。
def pad(s):
if len(s) < 20:
return s + ['<pad>'] * (20-len(s))
else:
return s[:20]
all_data.text = all_data.text.apply(lambda x : pad(x))
不得不说的是,pd的apply功能是真的好用!
train_X = all_data.text.iloc[:train.shape[0]]
test_X = all_data.text.iloc[train.shape[0]:]
train_y = torch.tensor(np.array(all_data.target_relabeled.iloc[:train.shape[0]]), dtype=torch.int64)
#进行切分
train_X = torch.concat([x for x in train_X.values], dim=0).reshape(-1, 20, 300)
train_X.shape
因为每个词向量实际上是tensor形式存储的,但是存在dataFrame里外面又套了一层list,所以没办法了。。。只能reshape回去。
这里我懒得思考了 ,直接用整个训练数据来train也不搞验证集了。就这样吧,爱咋咋地了。
train_dataset = Data.TensorDataset(train_X, train_y)
train_iter = Data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 做成迭代器
训练
模型的定义
class textcnn(nn.Module):
def __init__(self, embed_dim, nfilters, filter_sizes, classes=2, dropout=0.1):
super(textcnn, self).__init__()
self.convs = nn.ModuleList([
nn.Conv1d(in_channels=embed_dim, out_channels=nfilters, kernel_size=fs)
for fs in filter_sizes
])
self.fn = nn.Linear(len(filter_sizes)*nfilters, classes)
self.dropout = nn.Dropout(dropout)
self.mish = nn.Mish()
def forward(self, X):
# X shape (batchsize, nsteps, embed_dim)
X = X.permute(0, 2, 1)
# X (bs , embed_dim, ns)
conved = [self.mish(conv(X)) for conv in self.convs]
# (bs, nfiters, ns-filtersize[n]+1)
pooled = [F.max_pool1d(conv, conv.shape[-1]).squeeze(2) for conv in conved]
x = self.dropout(torch.cat(pooled, dim=1))
return self.fn(x)
这里怎么说呢,就是把维度看做了特征通道,所以input_channel就是输入的embed_dim。然后把时间步看做特征,那么我们的滑动窗口就很好理解了,就是在取滑动窗口的时间步进行分析。不得不说啊,用CNN来做确实快,并行度一高,train的就是快。
model = textcnn(300, 100, [3,4,5], 2, 0.5)
词向量的维度就是直接用的导入的词向量,没有直接用一层embedding,所以就是300,这个输出通道选择100,[3, 4, 5]分别表示,有3个卷积核。
训练过程
epochs = 200
model.cuda()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(epochs):
model.train()
metric = d2l.Accumulator(3)
for X, y in train_iter:
X = X.cuda()
y = y.cuda()
y_hat = model(X)
l = loss(y_hat, y) # y_hat shape (batch_size, 2)
optimizer.zero_grad()
l.backward()
optimizer.step()
acc_sum = (y_hat.argmax(dim=-1) == y).sum()
num = len(y)
lsum = l.item() * num
metric.add(num, lsum, acc_sum)
#if epoch == 0 or (epoch +1)%50 ==0:
print("epoch: %d acc: %.3f, loss: %.3f"%(epoch, metric[2]/metric[0],metric[1]/metric[0]))
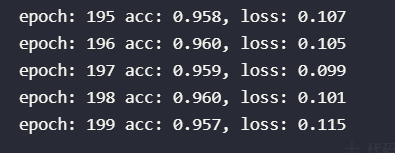
可以看到这里准确率还是可以的
预测并提交
model = model.to('cpu')
def predict(X):
X = X.unsqueeze(0)
t = model(X)
x,y = list(t[0])
if x > y:
return 0
else:
return 1
test_X['target'] = test_X['text'].apply(lambda x: predict(x))
sub = pd.read_csv('/home/wu/kaggle/pipeline/textcnn/sample_submission.csv')
sub['target'] = test_X.target
sub.to_csv('./sub.csv', index=False)
摆烂环节

简简单单900名,准确率0.728。emmm还行吧,没有用bert来做,train出0.7我觉得其实OK。开摆!