MySQL的InnoDB的细粒度行锁,是它最吸引人的特性之一。
但是,如《InnoDB,5项最佳实践》所述,如果查询没有命中索引,也将退化为表锁。
InnoDB的细粒度锁,是实现在索引记录上的。
一,InnoDB的索引
InnoDB的索引有两类索引,聚集索引(Clustered Index)与普通索引(Secondary Index)。
InnoDB的每一个表都会有聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个非空unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
为了方便说明,后文都将以PK说明。
索引的结构是B+树,这里不展开B+树的细节,说几个结论:
(1)在索引结构中,非叶子节点存储key,叶子节点存储value;
(2)聚集索引,叶子节点存储行记录(row);
画外音:所以,InnoDB索引和记录是存储在一起的,而MyISAM的索引和记录是分开存储的。
(3)普通索引,叶子节点存储了PK的值;
画外音:
所以,InnoDB的普通索引,实际上会扫描两遍:
第一遍,由普通索引找到PK;
第二遍,由PK找到行记录;
索引结构,InnoDB/MyISAM的索引结构,如果大家感兴趣,未来撰文详述。
举个例子,假设有InnoDB表:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A 3, zhangsan, m, A 5, lisi, m, A 9, wangwu, f, B
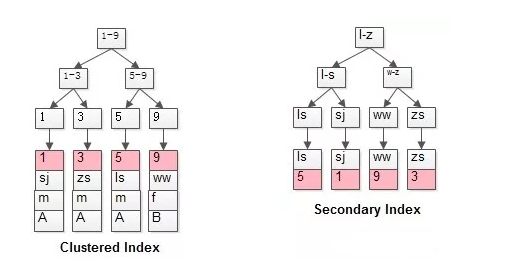
以看到:
(1)第一幅图,id PK的聚集索引,叶子存储了所有的行记录;
(2)第二幅图,name上的普通索引,叶子存储了PK的值;
对于:
select * from t where name=’shenjian’;
(1)会先在name普通索引上查询到PK=1;
(2)再在聚集索引衫查询到(1,shenjian, m, A)的行记录;
下文简单介绍InnoDB七种锁中的剩下三种:
-
记录锁(Record Locks)
-
间隙锁(Gap Locks)
-
临键锁(Next-Key Locks)
为了方便讲述,如无特殊说明,后文中,默认的事务隔离级别为可重复读(Repeated Read, RR)。
二、记录锁(Record Locks)
记录锁,它封锁索引记录,例如:
select * from t where id=1 for update;
它会在id=1的索引记录上加锁,以阻止其他事务插入,更新,删除id=1的这一行。
需要说明的是:
select * from t where id=1;
则是快照读(SnapShot Read),它并不加锁,具体在《InnoDB为什么并发高,读取快?》中做了详细阐述。
三、间隙锁(Gap Locks)
间隙锁,它封锁索引记录中的间隔,或者第一条索引记录之前的范围,又或者最后一条索引记录之后的范围。
依然是上面的例子,InnoDB,RR:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A 3, zhangsan, m, A 5, lisi, m, A 9, wangwu, f, B
这个SQL语句
select * from t
where id between 8 and 15
for update;
会封锁区间,以阻止其他事务id=10的记录插入。
画外音:
为什么要阻止id=10的记录插入?
如果能够插入成功,头一个事务执行相同的SQL语句,会发现结果集多出了一条记录,即幻影数据。
间隙锁的主要目的,就是为了防止其他事务在间隔中插入数据,以导致“不可重复读”。
如果把事务的隔离级别降级为读提交(Read Committed, RC),间隙锁则会自动失效。
四、临键锁(Next-Key Locks)
临键锁,是记录锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。
更具体的,临键锁会封锁索引记录本身,以及索引记录之前的区间。
如果一个会话占有了索引记录R的共享/排他锁,其他会话不能立刻在R之前的区间插入新的索引记录。
画外音:原文是说
If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
依然是上面的例子,InnoDB,RR:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A 3, zhangsan, m, A 5, lisi, m, A 9, wangwu, f, B
PK上潜在的临键锁为:
(-infinity, 1] (1, 3] (3, 5] (5, 9] (9, +infinity]
临键锁的主要目的,也是为了避免幻读(Phantom Read)。如果把事务的隔离级别降级为RC,临键锁则也会失效。
画外音:关于事务的隔离级别,以及幻读,之前的文章一直没有展开说明,如果大家感兴趣,后文详述。
今天的内容,主要对InnoDB的索引,以及三种锁的概念做了介绍。场景与例子,也都是最简单的场景与最简单的例子。
InnoDB的锁,与索引类型,事务的隔离级别相关,更多更复杂更有趣的案例,后续和大家介绍。
五、总结
(1)InnoDB的索引与行记录存储在一起,这一点和MyISAM不一样;
(2)InnoDB的聚集索引存储行记录,普通索引存储PK,所以普通索引要查询两次;
(3)记录锁锁定索引记录;
(4)间隙锁锁定间隔,防止间隔中被其他事务插入;
(5)临键锁锁定索引记录+间隔,防止幻读;