数据库的性能测试可以帮助你提前知道你的系统的负载能力,可以帮助你改进系统的实施或设计,可以帮助你确定一些设计和编程原则. 但是,这里面也有陷阱. 如果不小心,你会自己把自己陷进去,却最终不明白是什么原因. 这里,我拿一位先生为例,来看看他怎么自己把自己搞糊涂的.
最近, 想起在存储过程中究竟是使用临时表还是使用表变量对性能更为有利的问题. 我想这个问题的关键涉及到数据库是否对其进行transaction 管理的问题, 如果进行transaction 管理, 那么在改变表中的记录时就会使用 write-ahead transaction log 策略, 这样数据改变操作就会变慢. 所以, 如果数据库engine仅对一种类型的表进行事物管理, 那么使用不同类型的表就会体现出性能差别. 于是, 我就在网上搜了一下, 还真查出一篇特别对口的文章, Temporary Tables vs. Table Variables and Their Effect on SQL Server Performance.
总结Tsuranoff的这篇文章, 关于临时表和表变量, 理论上说, 有三点:
1. 数据库engine对临时表进行事务管理,但不对表变量进行事务管理.
2. 表变量是完全局域的,因此,不需要任何的locking.
3. 表变量相对临时表而言,比较少引起重编译
然后,Tsuranoff便展示了性能测试的结果,转录如下:
|
N |
T1 |
T2 |
T3 |
V1 |
V2 |
|
10 |
0.5 |
0.5 |
5.3 |
0.2 |
0.2 |
|
100 |
2 |
1.2 |
6.4 |
61.8 |
2.5 |
|
1000 |
9.3 |
8.5 |
13.5 |
168 |
140 |
|
10000 |
67.4 |
79.2 |
71.3 |
17133 |
13910 |
|
100000 |
700 |
794 |
659 |
Too long! | Too long! |
|
1000000 |
10556 |
8673 |
6440 |
Too long! | Too long! |
Table 2: Using SQL Server 2005 (time in ms).
为了读者阅读方便,我这里给出上表的解释:
1. T1, T2, T3, V1, V2代表了不同的存储过程,他们的逻辑和功能完全相同,仅仅是实现手法上略有差别. T1, T2, T3对应使用临时表的存储过程,其差别在于, T1不使用索引, T2使用预先定义的索引,T3先对临时表倒入数据,在进行查询前再建索引. V1使用表变量,但不使用索引,V2使用表变量并使用索引. "N"一列的数值是试验时对这些存储过程所采用的参数.
2. 结果显示,使用表变量的存储过程的性能并不比使用临时表的存储过程性能更好,相反,当输入参数N(即处理的行数)变大时,性能完全变坏.
毫无疑问,试验数据和理论推测的结果相反. 然而作者不去追究其深层的原因,就糊里糊涂的给出一堆结论. 可想而知,连数据都是错的,那给出的结论还不误人子弟吗? 这里就不重复他的结论了.
当我看到这些数据时,我就怀疑. 我猜,这些数据的产生可能是因为数据库engine使用了不同的查询计划导致的. 于是,我就用Sql Server Management Studio 来显示这些查询的计划,果然如我所猜.
存储过程T2的计划:
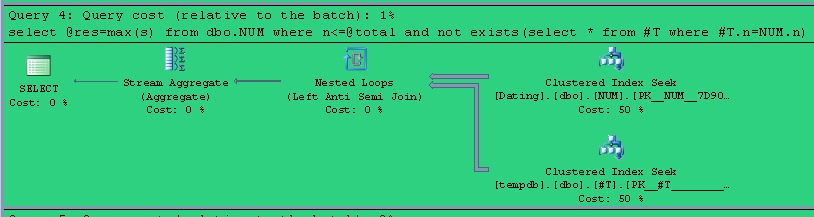 存储过程V2的计划:
存储过程V2的计划:
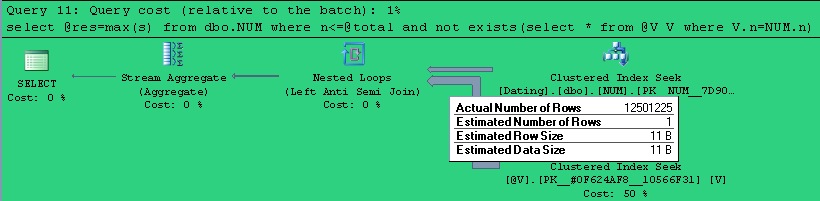
比较上面两个计划,我们就可以看出,Tsuranoff先生会得出那样的实验数据一点都不奇怪.
找出了问题的原因,解决方法就有了. 为此, 我先用 sp_recompile 把cache 中相应的查询计划清掉,然后,我改变了实验中使用参数的次序,转而先使用大的N参数值,再使用小的N参数值, 得出一系列的实验数据. 结果表明, 确实, 一般而言, 使用表变量的性能同等情况下比使用临时表略好.
这里解释一下,为什么改变了使用参数大小的次序,就能够得出正确的结果呢? 这是因为Sql Server Engine针对具体的参数值进行了优化,并把产生的查询计划缓存在系统中. 先使用大的参数,Engine就把对大参数优化的查询计划缓存在系统, 并重复使用之.
由此又产生了一个新的问题,那就是在生产环境中,先出现大参数或小参数完全是随机的,这样一来,如果参数出现的次序不对,那岂不是会让一个本来能够绰绰有余的负载客户量的系统变的完全瘫痪掉? 这显然是不可取的.
不用担心,Sql Server 还提供了其他一些途径来控制系统如何产生查询计划. 这其中,包括 Query hint, 和 Join hint. 如果这些还不够,你还可以更进一步使用Plan Guide. 关于这些,不在此多讲.
以下是本性能试验中使用的一些代码,是我在Tsuranoff先生的代码的基础上改进的结果.
--------create table and populate data
CREATE TABLE [dbo].[NUM]
([n] int NOT NULL, s varchar(128) NULL, PRIMARY KEY CLUSTERED([n] ASC))
go
-- populate data
set nocount on
declare @n int, @i int
set @n=1000000
set @i = 0
while @n>0 begin
if @i = 0 begin tran
insert into dbo.NUM
select @n, convert(varchar,@n + @i * 2)
set @n=@n-1
set @i = (@i + 1) % 1000
if @i = 0 commit
end
GO
---Create stored procs
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
Create procedure [dbo].[T1]
@total int
as begin
create table #T (n int, s varchar(128))
set nocount on
insert into #T select n,s from dbo.NUM
where n%100>0 and n<=@total
declare @res varchar(128)
select @res=max(s) from dbo.NUM
where n<=@total
and not exists(select * from #T where #T.n=NUM.n)
return @res
end
go
----------
CREATE procedure [dbo].[T2]
@total int
as
begin
create table #T (n int primary key, s varchar(128))
set nocount on
insert into #T select n,s from dbo.NUM
where n%100>0 and n<=@total
declare @res varchar(128)
select @res=max(s) from dbo.NUM
where n<=@total and
not exists(select * from #T where #T.n=NUM.n)
option(merge join) -- Query hint
return @res
end
go
-------
CREATE procedure [dbo].[T3]
@total int
as begin
create table #T (n int, s varchar(128))
set nocount on
insert into #T select n,s from dbo.Num
where n%100>0 and n<=@total
create clustered index Tind on #T (n)
declare @res varchar(128)
select @res=max(s) from dbo.Num
where n<=@total and
not exists(select * from #T
where #T.n=NUM.n)
return @res
end
go
--------
CREATE procedure [dbo].[V1]
@total int
as begin
declare @V table (n int, s varchar(128))
set nocount on
insert into @V select n,s from dbo.NUM
where n%100>0 and n<=@total
declare @res varchar(128)
select @res=max(s) from dbo.NUM
where n<=@total and
not exists(select * from @V V
where V.n=NUM.n)
return @res
end
go
---------------
CREATE procedure [dbo].[V2]
@total int
as begin
declare @V table (n int primary key, s varchar(128))
set nocount on
insert into @V select n,s from dbo.NUM
where n%100>0 and n<=@total
declare @res varchar(128)
select @res=max(s) from dbo.NUM
where n<=@total and
not exists(select * from @V V where V.n=NUM.n)
option(merge join) -- query hint
return @res
end
go
-------- Test Code
declare @t1 datetime, @n int, @i int, @total int
set @total = 50000 -- should less than 1,000,000
set @n=10 -- 重复次数,先取小值,逐渐加大,以免用时过长
print @total
-- test T1
set @t1=getdate()
set @i = 0
while @i < @n begin
exec dbo.T1 @total
set @i=@i + 1
end
select datediff(ms,@t1,getdate()) * 1.0 / @n
-- test T2
set @t1=getdate()
set @i = 0
while @i < @n begin
exec dbo.T2 @total
set @i=@i + 1
end
select datediff(ms,@t1,getdate()) * 1.0 / @n
-- test T3
set @t1=getdate()
set @i = 0
while @i < @n begin
exec dbo.T3 @total
set @i=@i + 1
end
select datediff(ms,@t1,getdate()) * 1.0 / @n
-- test V1
set @t1=getdate()
set @i = 0
while @i < @n begin
exec dbo.V1 @total
set @i=@i + 1
end
select datediff(ms,@t1,getdate()) * 1.0 / @n
-- test V2
set @t1=getdate()
set @i = 0
while @i < @n begin
exec dbo.V2 @total
set @i=@i + 1
end
select datediff(ms,@t1,getdate()) * 1.0 / @n
-------------
注意,在T2和V2的代码中使用了 option(merge join), 这时再来看它们的查询计划图,就发现,T2和V2现在使用完全相同的查询计划.
带有query hint 的T2的查询计划:

带有query hint 的V2的查询计划:
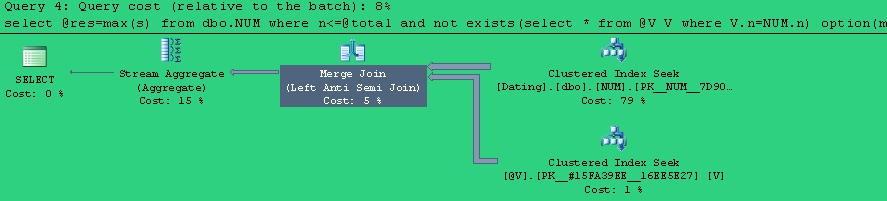
现在,T2和V2的查询计划相同,再进行性能比较试验,就能得出完全合理的实验数据.
|
N |
T1 |
T2 |
T3 |
V1 |
V2 |
| 100 | 11.9 | 8 | 11.3 | 8.4 | 6.8 |
| 1000 | 166 | 23 | 36 | 239 | 19 |
| 10000 | 366 | 304 | 384 | 17695 | 290 |
| 100000 | 3338 | 3740 | 3653 | 太长 | 3586 |
| 500000 | 21040 | 25096 | 18076 | 太长 | 20036 |
| 1000000 | 37716 | 87783 | 68246 | 太长 | 40956 |
Note: 单位为ms, 只有 T2 和 V2 的数据是可比的, 因为它们的execution plan 是相同的.