对比Zookeeper
- 回顾CAP原则
RDBMS (Mysql、Oracle、sqlServer)=>ACID
NoSQL(redis、mongdb)=> CAP
- ACID是什么?
A(Atomicity)原子性
C(Consistency) 一致性
I (Isolation)隔离性
D(Durability)持久性
- CAP是什么?
C(Consistency)强一致性
A(Availability)可用性
P(Partition tolerance)分区容错性
CAP的三进二:CA、AP、CP
- CAP理论的核心
一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求
根据CAP原理,将NoSQL数据库分成了满足CA原则,满足CP原则和满足AP原则三大类:
CA:单点集群,满足一致性,可用性的系统,通常可扩展性较差
CP:满足一致性,分区容错性的系统,通常性能不是特别高
AP:满足可用性,分区容错性的系统,通常可能对一致性要求低一些
- 作为服务注册中心,Eureka比Zookeeper好在哪里?
著名的CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)、P(容错性)。
由于分区容错性P在分布式系统中是必须要保证的,因此我们只能在A和C之间进行权衡。
Zookeeper保证的是CP;Eureka保证的是AP;
Zookeeper保证的是CP(标黑的不是说的zk)
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30~120s,且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因为网络问题使得zk集群失去master节点是较大概率会发生的事件,虽然服务最终能够恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证的是AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册时,如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保住注册服务的可用性,只不过查到的信息可能不是最新的,除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上(即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其他节点中
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪
1、单服务搭建ribbon
- 1、在springcloud-consumer-dept-80的pom.xml添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
- 2、在springcloud-consumer-dept-80的application.yml添加如下配置

- 3、在springcloud-consumer-dept-80的ConfigBean中的方法上添加@LoadBalanced注解
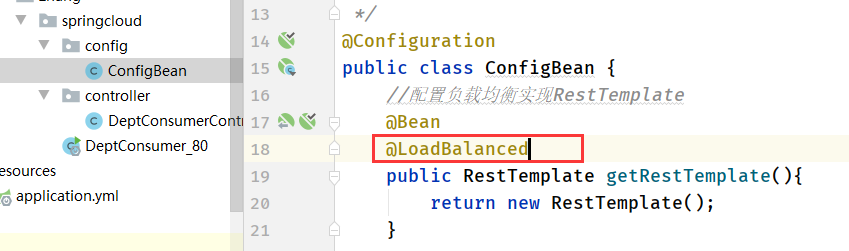
- 4、修改springcloud-consumer-dept-80的DeptConsumerController的请求前缀

- 5、在springcloud-consumer-dept-80的启动类上添加@EnableEurekaClient
- 6、访问http://localhost/consumer/get/3

2、集群服务搭建ribbon
- 为了达到效果需要用到三个数据库,就可以看出效果;db01,db02,db03
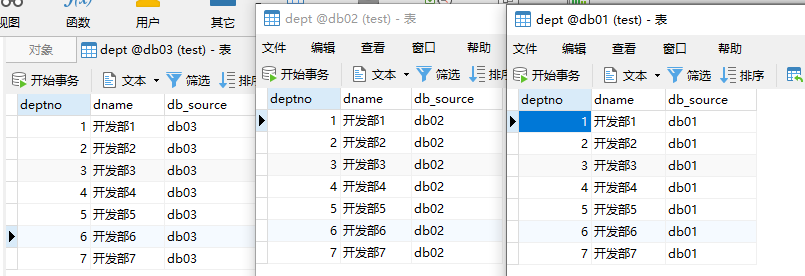
- 创建8002和8003两个服务,把8001的pom依赖拷进去,同时修改对应的application.yml(port,instance-id,数据库名)
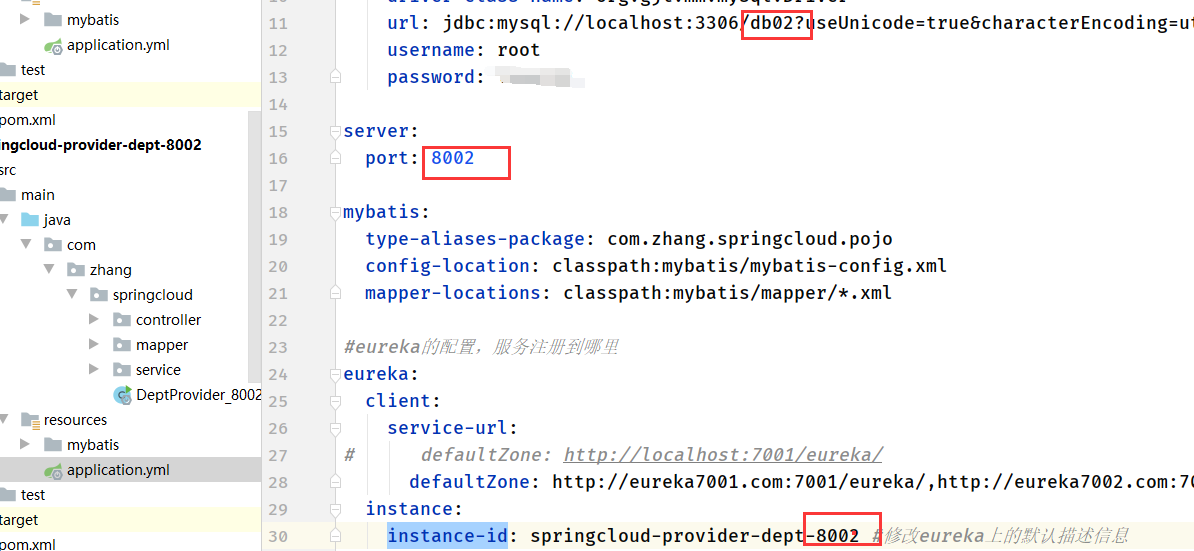
- 修改对应的启动类,然后启动8001,8002,8003,访问http://eureka7001.com:7001/ 查看服务是否注册成功

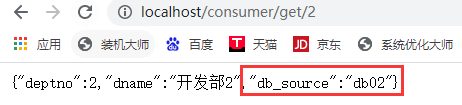
- 访问http://localhost/consumer/get/2 ,其中db_source依次改变,刷新一次,变一次,1,2,3依次(默认轮询)
3、自定义ribbon负载均衡算法
- 在和springclolud平级创建一个包(如果建在springcloud里边的话,会不生效)
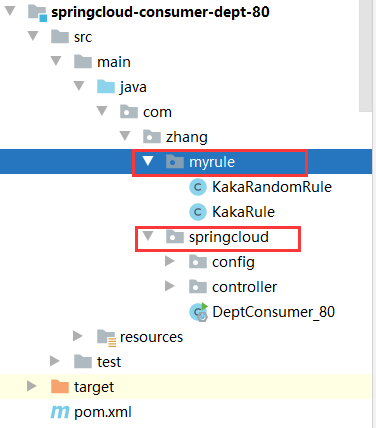
- 自定义算法实现类
import com.netflix.client.config.IClientConfig;
import com.netflix.loadbalancer.AbstractLoadBalancerRule;
import com.netflix.loadbalancer.ILoadBalancer;
import com.netflix.loadbalancer.Server;
import java.util.List;
import java.util.concurrent.ThreadLocalRandom;
public class KakaRandomRule extends AbstractLoadBalancerRule {
private int total = 0;//被调用的次数
private int currentIndex = 0;//当前是谁在提供服务
/**
* 每个服务访问5次,换下一个服务(3个)
* total=0,默认=0,如果=5,我们指向下一个服务节点
* index=0,默认=0,如果total=5,index+1.
* @param lb
* @param key
* @return
*/
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
} else {
Server server = null;
while(server == null) {
if (Thread.interrupted()) {
return null;
}
List<Server> upList = lb.getReachableServers();//获得活着的服务
List<Server> allList = lb.getAllServers();//获得全部服务
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
// int index = this.chooseRandomInt(serverCount);//生成区间随机数
// server = (Server)upList.get(index);//从活着的服务中,随机获取一个
//=================================================
if(total < 5){
server = upList.get(currentIndex);
total ++;
}else {
total = 0;
currentIndex ++;
if(currentIndex >= upList.size()){
currentIndex = 0;
}
// server = upList.get(currentIndex);
}
//=================================================
if (server == null) {
Thread.yield();
} else {
if (server.isAlive()) {
return server;
}
server = null;
Thread.yield();
}
}
return server;
}
}
protected int chooseRandomInt(int serverCount) {
return ThreadLocalRandom.current().nextInt(serverCount);
}
@Override
public Server choose(Object key) {
return this.choose(this.getLoadBalancer(), key);
}
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
- 配置到bean里
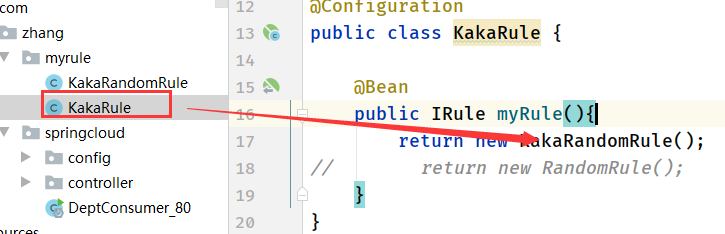
- 在启动类添加注解@RibbonClient(name = "SPRINGCLOUD-PROVIDER-DEPT",configuration = KakaRule.class)
name = "SPRINGCLOUD-PROVIDER-DEPT"是服务名
- 访问http://localhost/consumer/get/2 ,每一个id都显示5次,然后就是下一个,就实现了自定义ribbon算法。