创建、删除数据库
格式
use DATABASE_NAME
如果不存在,则创建,否则直接切换到该数据库
显示当前所在的数据库
db
显示所有数据库
show dbs
删除数据库
db.dropDatabase()
例子
> show dbs admin 0.078GB db_log 0.953GB local 0.078GB test 0.078GB > use del_db switched to db del_db > db.col.insert({x:123}) WriteResult({ "nInserted" : 1 }) > show dbs admin 0.078GB db_log 0.953GB del_db 0.078GB local 0.078GB test 0.078GB > db del_db > db.dropDatabase() { "dropped" : "del_db", "ok" : 1 }
插入文档
文档的数据结构和json基本一致
所有存储在集合中都是BSON格式
BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON
>db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
删除文档
语法
db.collection.remove( <query>, <justOne> )
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
对比
- 删除集合中的所有文档(保留集合):db.col.remove({})
- 删除集合:db.col.drop()
案例
> db.col.find() { "_id" : ObjectId("56c55cf5ca446fab71e4c382"), "x" : 1 } { "_id" : ObjectId("56c55cf6ca446fab71e4c383"), "x" : 1 } { "_id" : ObjectId("56c55cffca446fab71e4c384"), "x" : 1 } > db.col.remove({x:1}, 1) WriteResult({ "nRemoved" : 1 }) > db.col.find() { "_id" : ObjectId("56c55cf6ca446fab71e4c383"), "x" : 1 } { "_id" : ObjectId("56c55cffca446fab71e4c384"), "x" : 1 } > db.col.remove({x:1}) WriteResult({ "nRemoved" : 2 }) > db.col.find()
查询文档
读取格式:db.COL_NAME.find()
以易读的方式读取:db.COL_NAME.find().pretty()
只读一个文档:db.COL_NAME.findOne()
AND条件
db.col.find({key1:value1, key2:value2})
OR条件
db.col.find( { $or: [ {key1: value1}, {key2:value2} ] } )
条件查询

案例:
x>1 & (y=3 or y = 4)
db.col.find( { x:{$gt:1}, $or:[ {y:3},{y:4} ] } )
$type操作符
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果
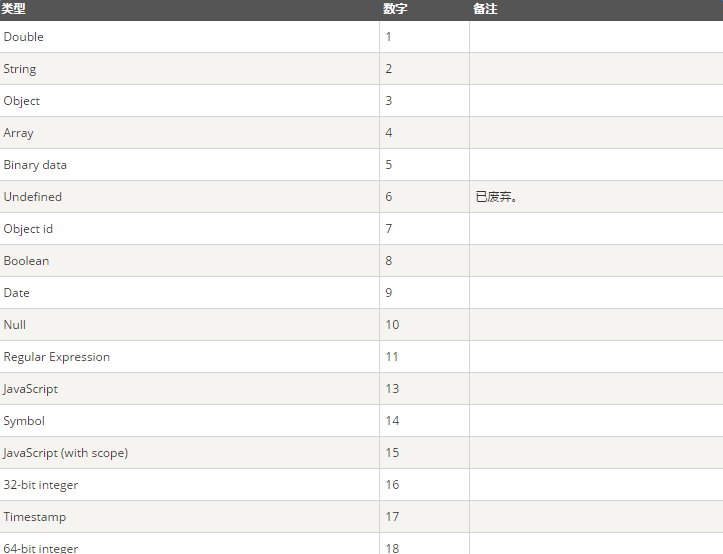
示例
> db.col.find() { "_id" : ObjectId("56c562c1ca446fab71e4c387"), "x" : 2, "y" : 3 } { "_id" : ObjectId("56c562c8ca446fab71e4c388"), "x" : 3, "y" : 4 } { "_id" : ObjectId("56c568a8b708aa3d13c61cc6"), "x" : "aaa" } > db.col.find({x:{$type:2}}) { "_id" : ObjectId("56c568a8b708aa3d13c61cc6"), "x" : "aaa" } > db.col.find({x:{$type:1}}) { "_id" : ObjectId("56c562c1ca446fab71e4c387"), "x" : 2, "y" : 3 } { "_id" : ObjectId("56c562c8ca446fab71e4c388"), "x" : 3, "y" : 4 }
limit(n)与skip(n)方法
limit显示前n条文档
skip调到第n条文档开始显示
示例
> db.col.find() { "_id" : ObjectId("56c562c1ca446fab71e4c387"), "x" : 2, "y" : 3 } { "_id" : ObjectId("56c562c8ca446fab71e4c388"), "x" : 3, "y" : 4 } { "_id" : ObjectId("56c568a8b708aa3d13c61cc6"), "x" : "aaa" } > db.col.find().limit(2) { "_id" : ObjectId("56c562c1ca446fab71e4c387"), "x" : 2, "y" : 3 } { "_id" : ObjectId("56c562c8ca446fab71e4c388"), "x" : 3, "y" : 4 } > db.col.find().skip(1) { "_id" : ObjectId("56c562c8ca446fab71e4c388"), "x" : 3, "y" : 4 } { "_id" : ObjectId("56c568a8b708aa3d13c61cc6"), "x" : "aaa" } > db.col.find().skip(1).limit(1) { "_id" : ObjectId("56c562c8ca446fab71e4c388"), "x" : 3, "y" : 4 }
排序
格式:
db.COL_NAME.find().sort({KEY:1})
KEY对应的值:1(升序),-1(降序)
示例:
> db.col.find() { "_id" : ObjectId("56c56dd4ca446fab71e4c38a"), "x" : 1, "y" : 3 } { "_id" : ObjectId("56c572c2ca446fab71e4c38b"), "x" : 2, "y" : 2 } { "_id" : ObjectId("56c572c8ca446fab71e4c38c"), "x" : 3, "y" : 1 } > db.col.find().sort({x:1}) { "_id" : ObjectId("56c56dd4ca446fab71e4c38a"), "x" : 1, "y" : 3 } { "_id" : ObjectId("56c572c2ca446fab71e4c38b"), "x" : 2, "y" : 2 } { "_id" : ObjectId("56c572c8ca446fab71e4c38c"), "x" : 3, "y" : 1 } > db.col.find().sort({x:-1}) { "_id" : ObjectId("56c572c8ca446fab71e4c38c"), "x" : 3, "y" : 1 } { "_id" : ObjectId("56c572c2ca446fab71e4c38b"), "x" : 2, "y" : 2 } { "_id" : ObjectId("56c56dd4ca446fab71e4c38a"), "x" : 1, "y" : 3 }
索引
如果没有索引,MongoDB读取文件时,首先扫描整个文件从中找到符合条件的记录。查询效率巨低!
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
语法格式
db.COLLECTION_NAME.ensureIndex({KEY:1})
KEY值是要创建的索引字段,1为指定按升序建索引,-1是指定按降序建索引。
> db.col.ensureIndex({y:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
聚合
聚合主要用来处理数据(如平均值、求和等),并返回计算后的数据结果
语法格式
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
复制
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
原理
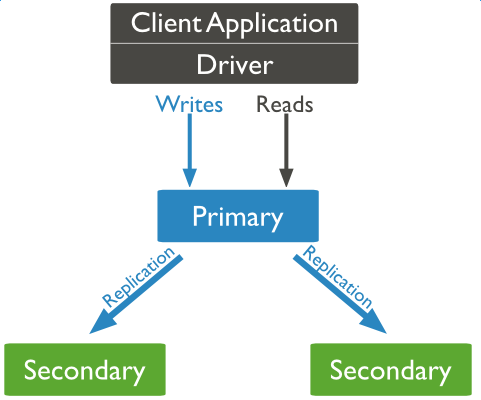
副本集特征
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复