强化学习(Reinforcement Learning)
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
通过阅读《神经网络与深度学习》及其他资料,了解强化学习(Reinforcement Learning)的基本知识,并介绍相关强化学习算法。更多强化学习内容,请看:随笔分类 - Reinforcement Learning。
1. 强化学习背景与基本概念
1.1 强化学习概念图
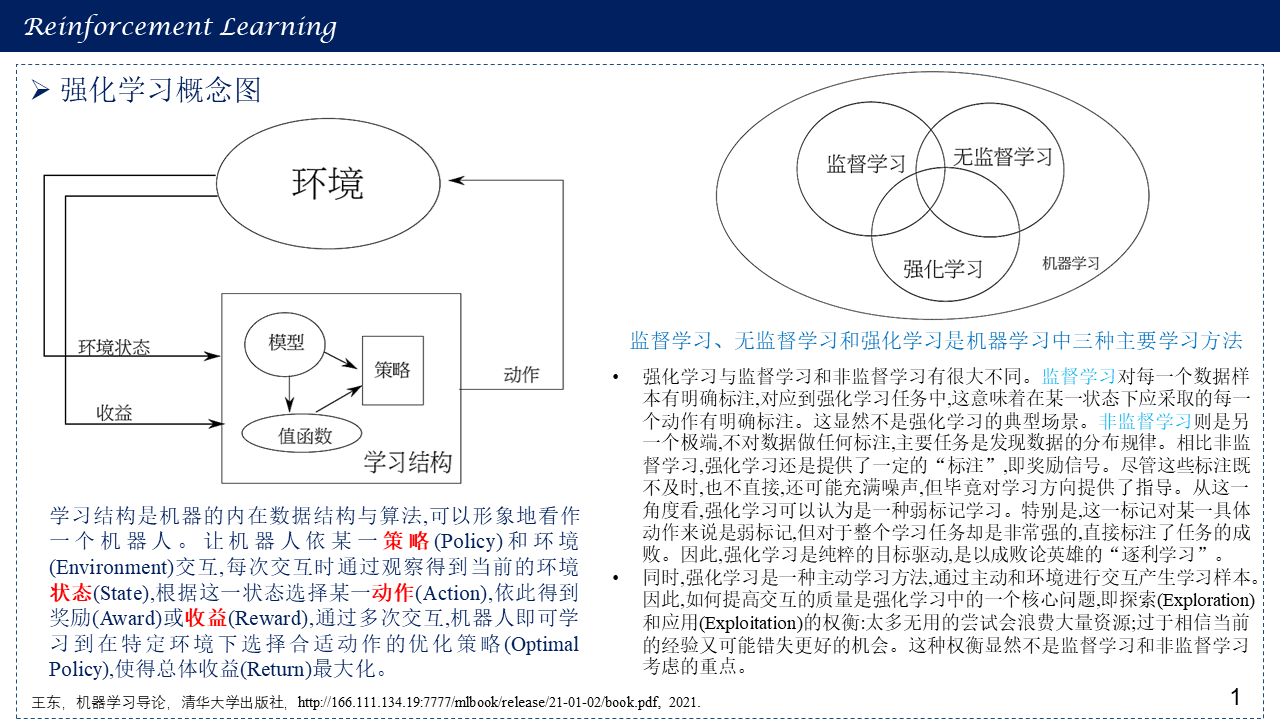
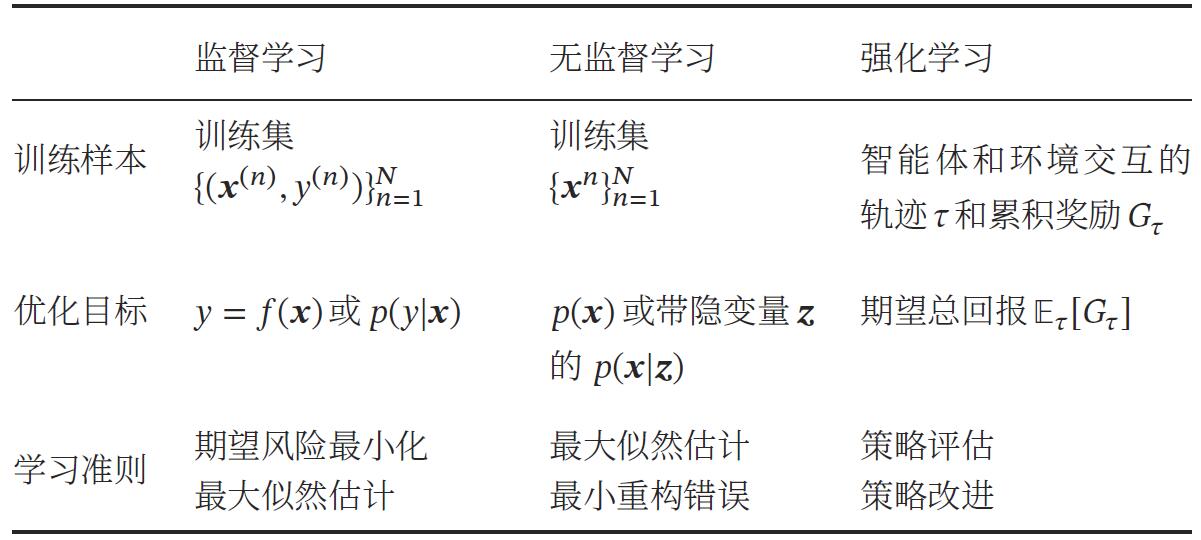
三种机器学习方法(监督学习,无监督学习与强化学习)比较:
1.2 基于学习信号的结构复杂度和时序复杂度对机器学习方法进行归类

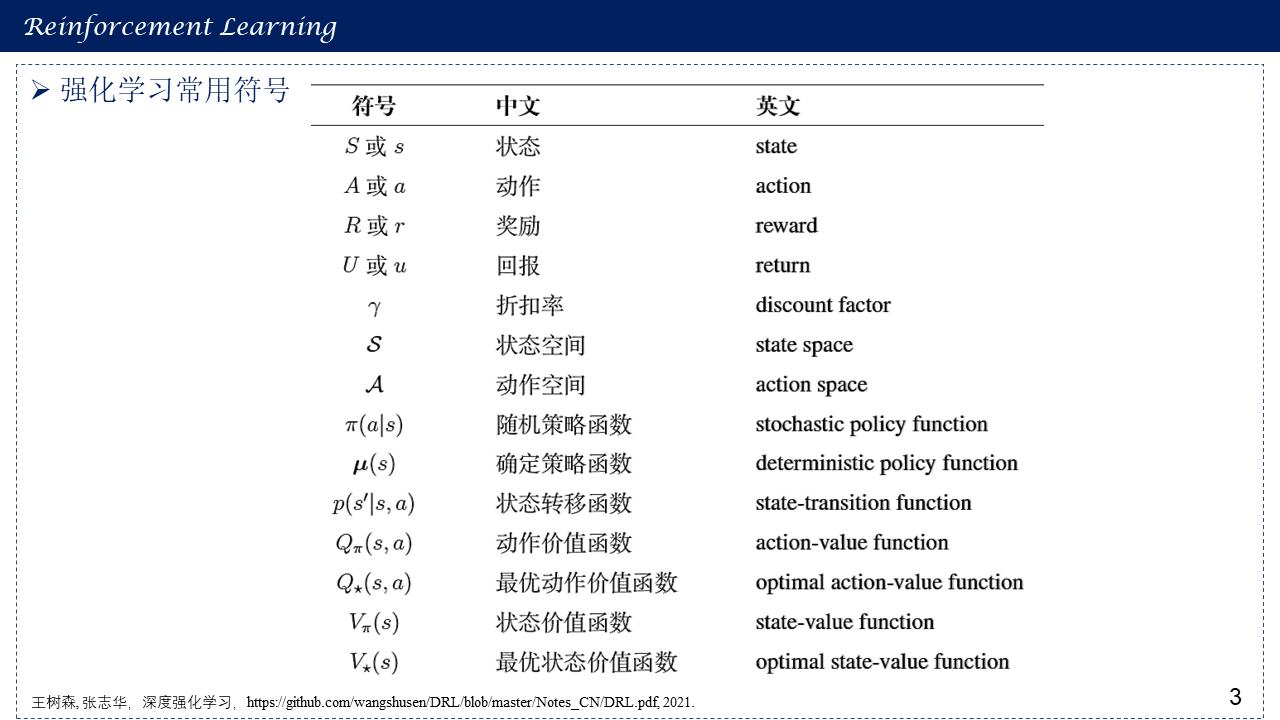
1.3 强化学习常用符号
1.4 强化学习定义与概念

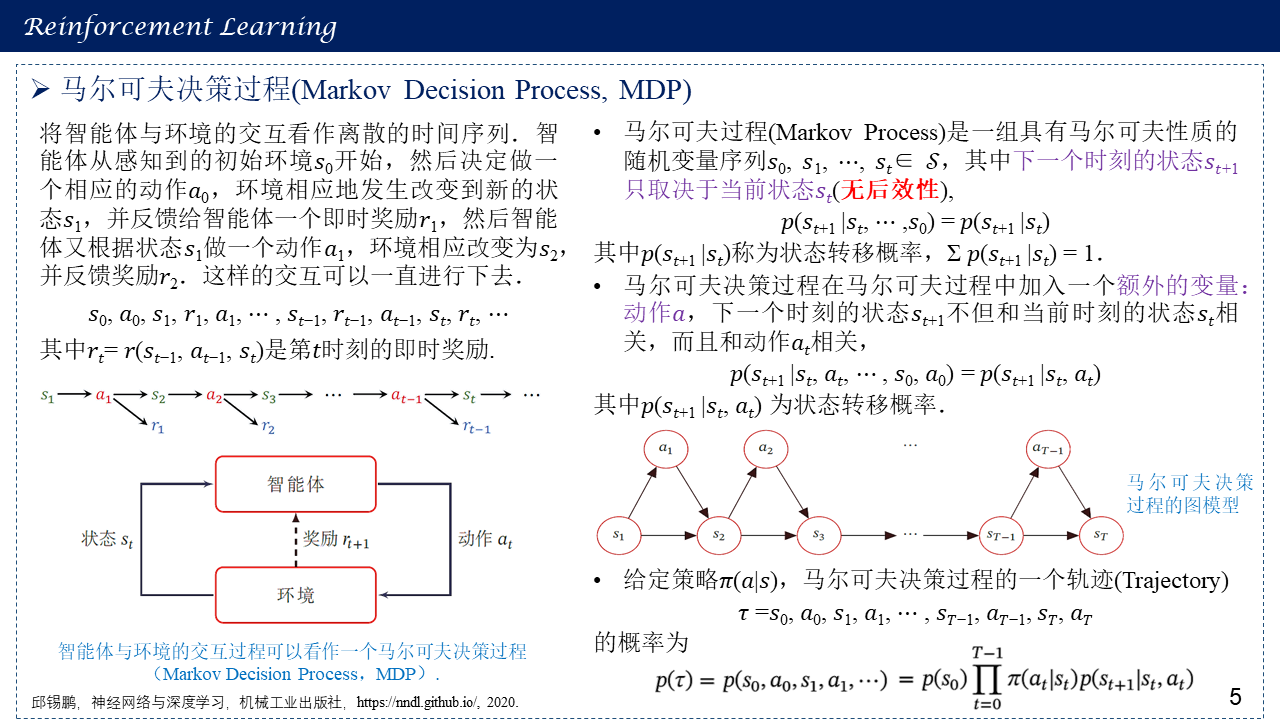
1.5 马尔可夫决策过程(Markov Decision Process, MDP)
1.6 强化学习的目标函数

1.7 值函数


1.8 强化学习方法总体概括
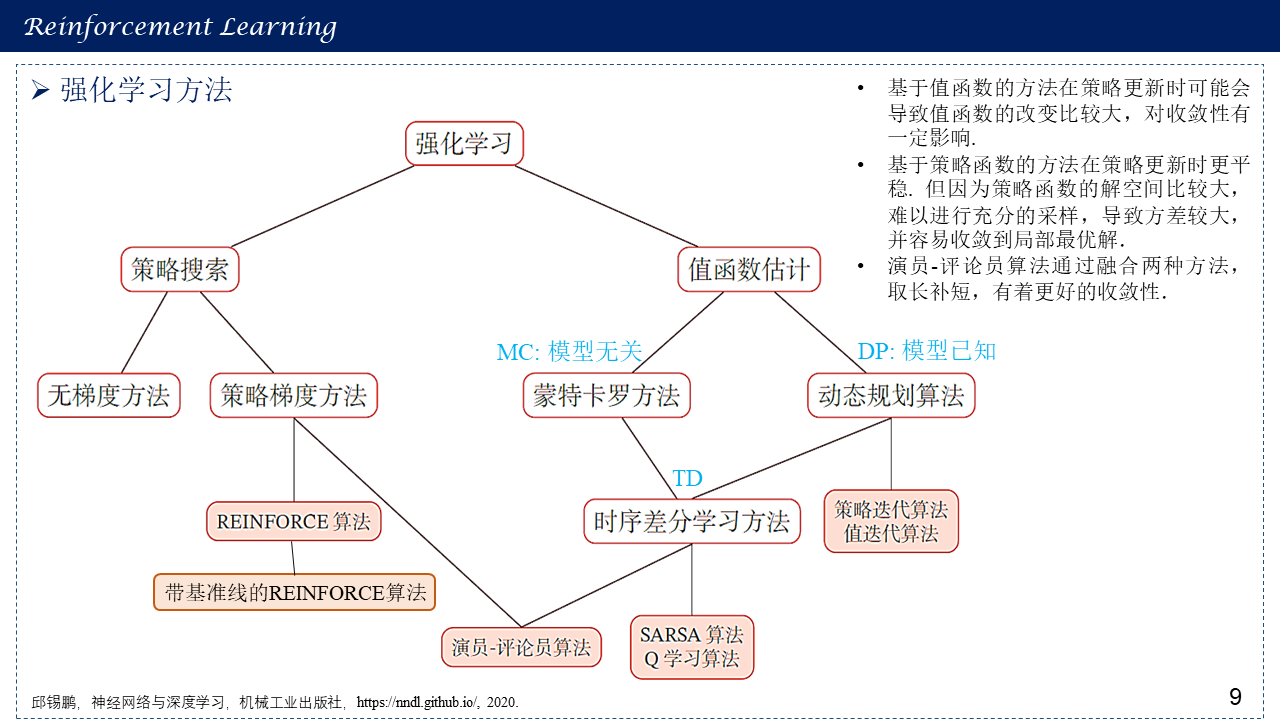
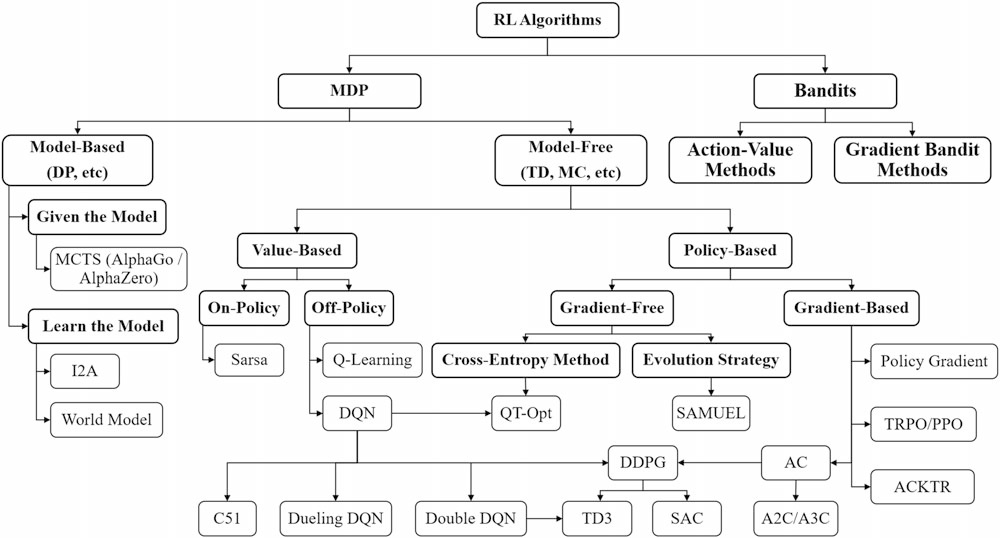

算法小结:
1. 值函数算法:通过迭代更新值函数来间接得到智能体的策略,当值函数迭代达到最优时,智能体的最优策略通过最优值函数得到。在算法应用的场景上,值函数算法需要对动作进行采样,因此只能处理离散动作的情况。
2. 策略梯度算法:直接采用函数近似的方法建立策略网络,通过策略网络选取动作得到奖励值,并沿梯度方向对策略网络参数进行优化,得到优化的策略最大化奖励值。在算法应用的场景上,策略梯度算法直接利用策略网络对动作进行搜索,可以被用来处理连续动作的情况。
3. 演员-评论员算法:将值函数算法和策略梯度算法结合得到的演员-评论员(Actor-Critic, AC)结构也受到了广泛的关注。在AC结构中,演员使用策略梯度法选取动作,通过值函数对演员采取的动作进行评价,并且在训练时,演员和评论员的参数交替更新。
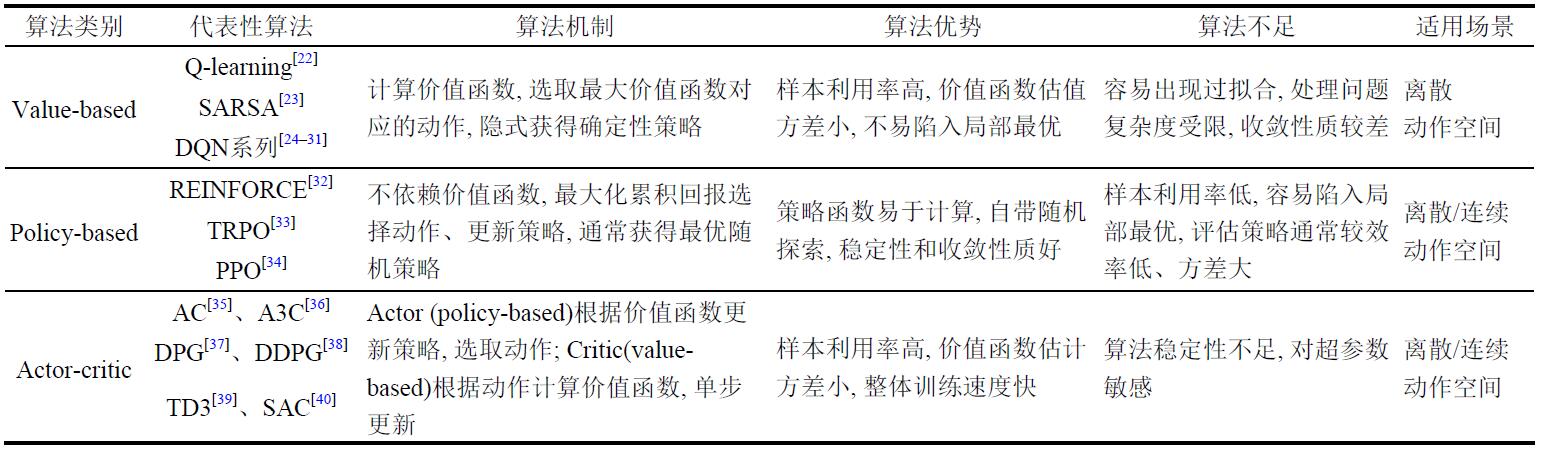
图源:李茹杨,彭慧民,李仁刚,赵坤.强化学习算法与应用综述.计算机系统应用,2020,29(12):13-25.
2. 基于值函数的方法
2.1 值函数估计——优化思路

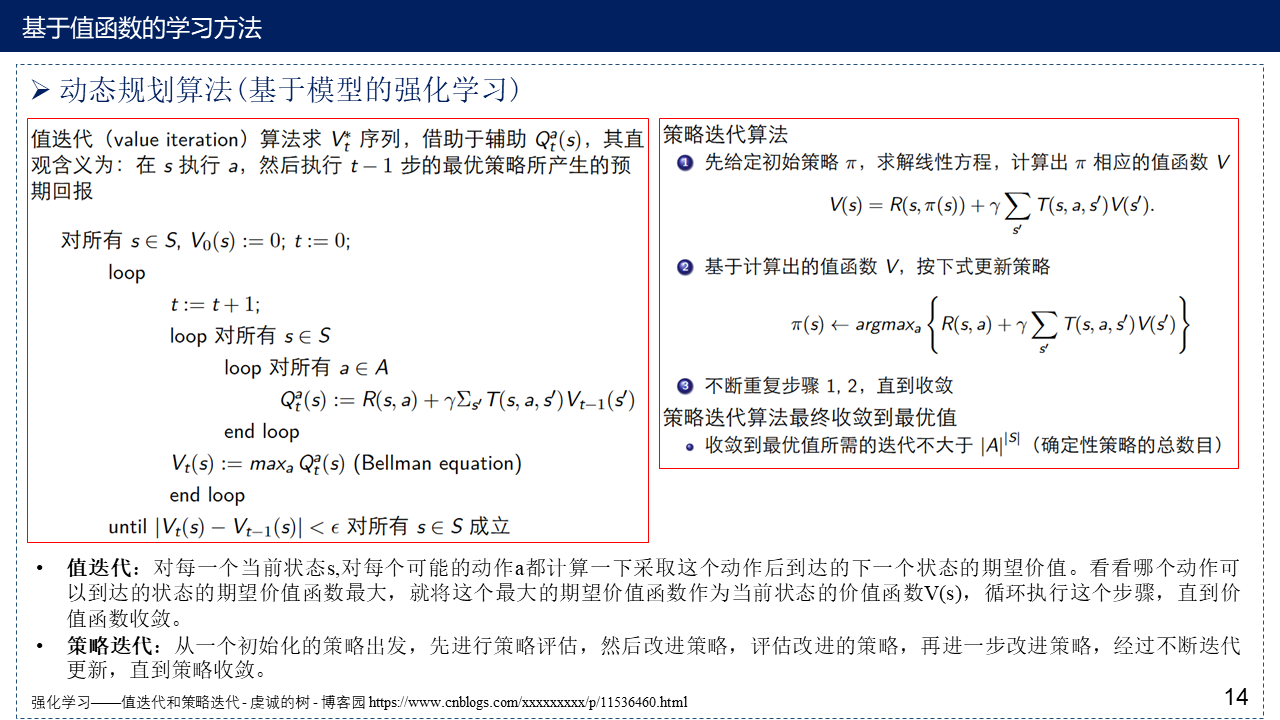
2.2 动态规划算法(基于模型的强化学习)


2.3 蒙特卡罗方法(模型无关的强化学习)


2.4 时序差分学习方法(蒙特卡罗+动态规划)

2.4.1 SARSA:一种同策略的时序差分学习算法

2.4.2 Q学习:一种异策略的时序差分学习算法

Q学习通常假设智能体贪婪地选择动作,即只选择Q值最大的动作,其他动作的选择概率为0,从而保证了Q学习的收敛性。与Sarsa相比,异策略Q学习需要更短的训练时间,跳出局部最优解的概率更大。然而,如果智能体根据Q值的概率模型而不是贪婪选择对动作进行采样,则采用异策略技术的Q值估计误差将增大。
2.4.3 深度Q网络(Deep Q-Networks,DQN)


DQN网络结构:
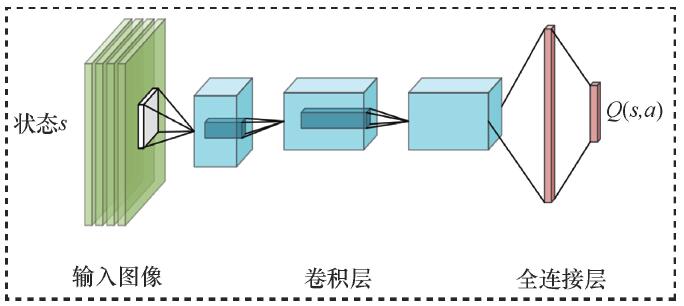
DQN(off-policy)算法流程:
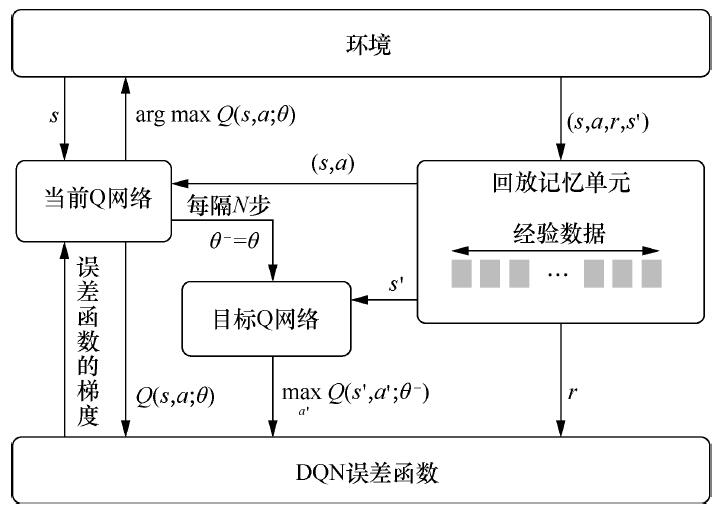
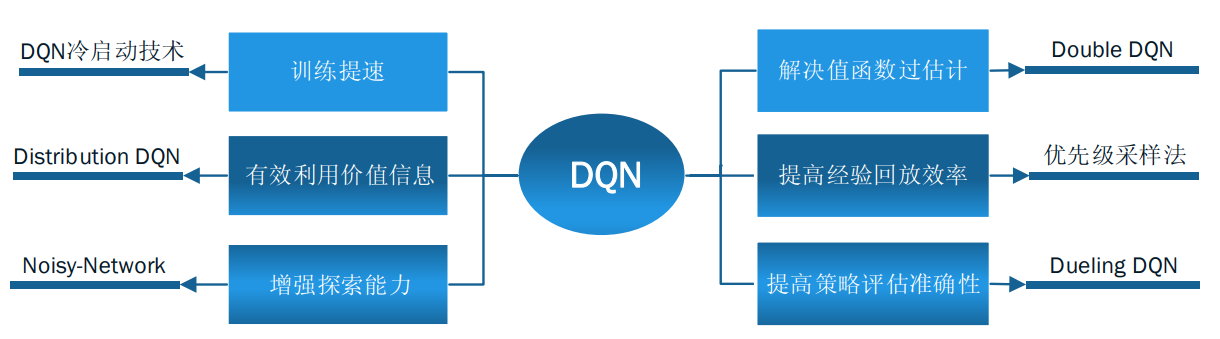
DQN算法改进:
 Dueling DQN 的网络结构
Dueling DQN 的网络结构

补充:为什么需要经验回放池(Experience Replay Buffer)?
1. 重复利用收集到的经验,而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现。重复利用经验、不重复利用经验的收敛曲线通常如下图所示。图的横轴是样本数量,纵轴是平均回报。

图来自:王树森, 张志华, 深度强化学习,https://github.com/wangshusen/DRL/blob/master/Notes_CN/DRL.pdf, 2021.
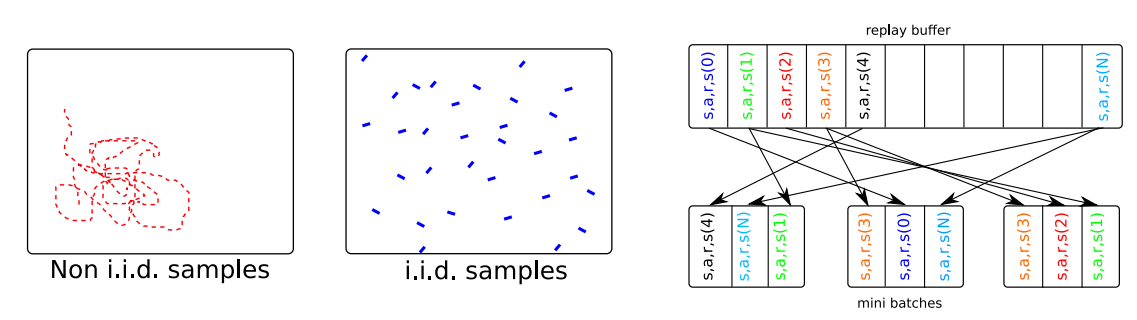
2. 采用神经网络训练时,一般需要进行基于梯度的优化,并对数据进行分批次训练,设立batch,但采用这种方式的前提是假设样本之间都是独立同分布的(independent and identically distributed,i.i.d.),这样每个batch内的噪声可以互相抵消。但强化学习中的决策过程是一个时间序列,这意味着前后数据之间具有很强的相关性,这样不利于进行梯度优化。设立经验回放池,将贝尔曼公式中需要的数据保存起来,通过随机的(或者基于优先度的)从经验回放池中进行抽样,当回放池中的数据足够多,随机抽样得到的数据就接近独立同分布,因此设立经验回放池可以打破序列之间的相关性,避免模型陷入局部最优。
图来自:From Policy Gradient to Actor-Critic methods https://rl-vs.github.io/rlvs2021/class-material/pg/6_baseline_AC.pdf
3. 基于策略函数的学习方法
3.1 策略梯度(Policy Gradient)

3.2 REINFORCE算法

3.3 带基准线的REINFORCE算法(REINFORCE with Baseline)


补充:策略梯度法改进思路
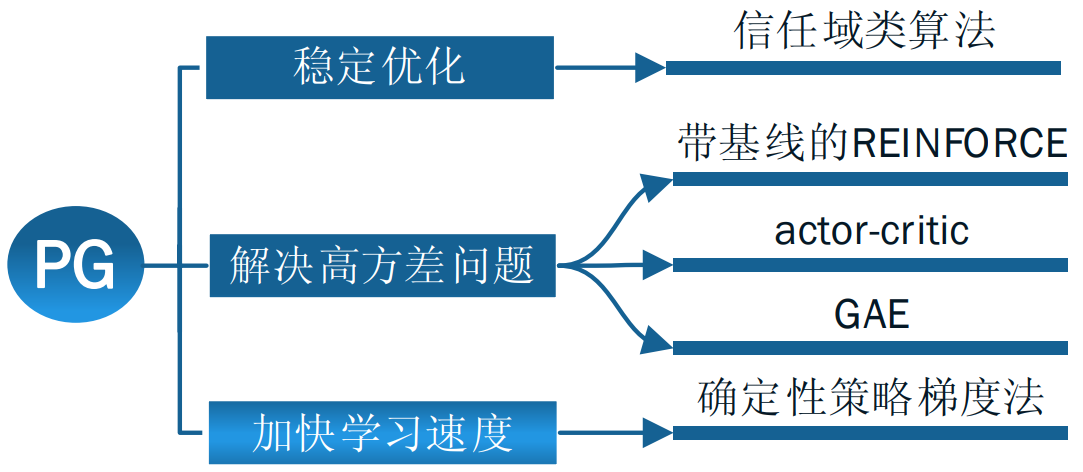
信任域类算法请看:信赖域策略优化(Trust Region Policy Optimization, TRPO),近端策略优化算法(Proximal Policy Optimization Algorithms, PPO),重要性采样(Importance Sampling)——TRPO与PPO的补充
4. 演员-评论员算法(Actor-Critic Algorithm)

A2C的基本结构:

A3C(on-policy)异步训练框架图:

Soft Actor-Critic:

5. 深度强化学习算法分类与应用
5.1 算法分类

5.2 应用与意义

6. 基于模型的方法与定义奖励函数方法概述
根据智能体是否通过与环境交互获得的,数据来预定义环境动态模型,将强化学习分为模型化强化学习(基于模型的强化学习)和无模型强化学习(与模型无关的强化学习),上述讨论的均为无模型强化学习。

无模型的深度强化学习算法需要大量的采样数据进行训练,而这些数据往往很难通过交互得到,因此可以考虑使用已有的现实环境中的数据建立环境模型,然后利用环境模型对智能体进行训练。
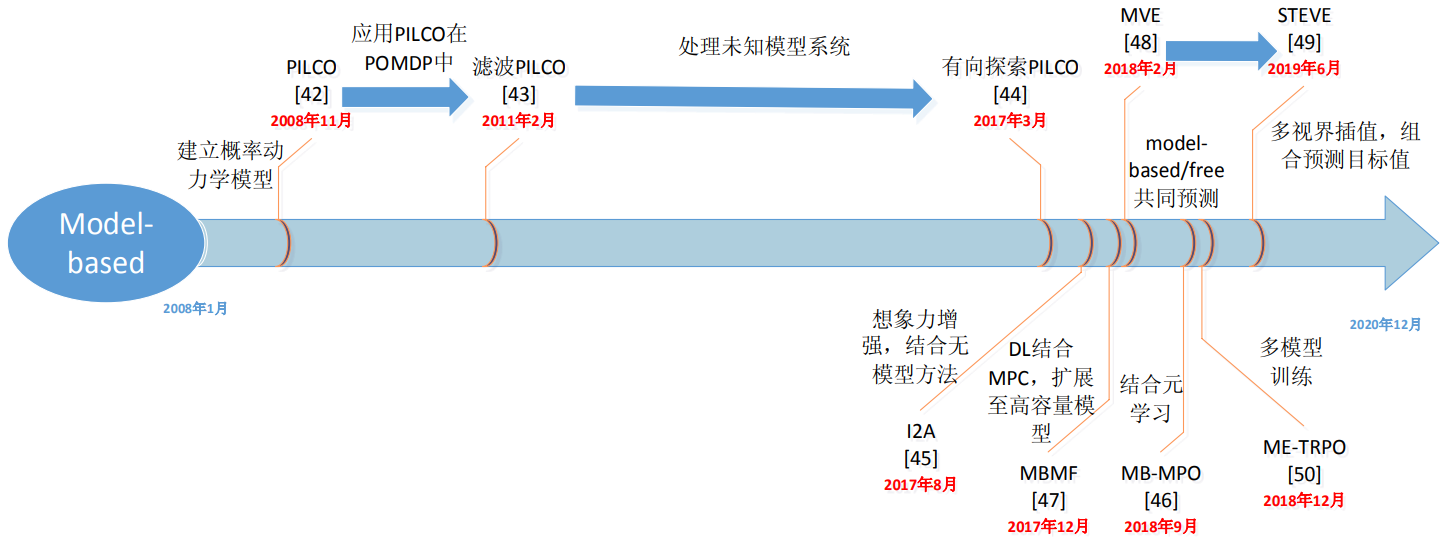
基于模型的强化学习:
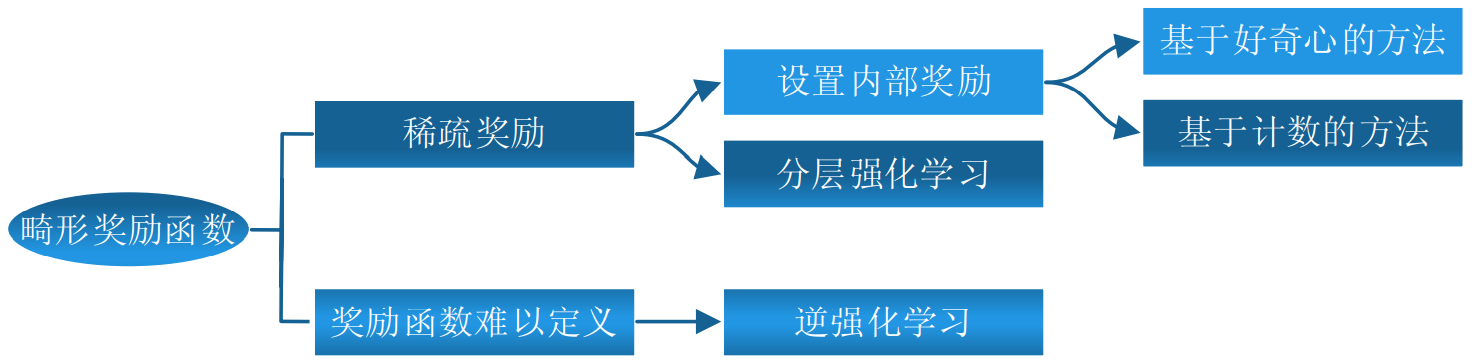
定义奖励函数方法概述:
7. 参考文献
[1] 强化学习相关资料(书籍,课程,网址,笔记等) - 凯鲁嘎吉 博客园
[2] 邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.
[3] 强化学习——值迭代和策略迭代 - 虔诚的树 - 博客园 https://www.cnblogs.com/xxxxxxxxx/p/11536460.html
[4] 杨思明 , 单征 , 丁煜 , 李刚伟. 深度强化学习研究现状及展望[J]. 计算机工程, 2021, doi: 10.19678/j.issn.1000-3428.0061116.
[5] 刘朝阳, 穆朝絮, 孙长银. 深度强化学习算法与应用研究现状综述[J]. 智能科学与技术学报, 2020, 2(4): 314-326.
[6] 秦智慧, 李宁, 刘晓彤, 刘秀磊, 佟强, 刘旭红. 无模型强化学习研究综述[J]. 计算机科学, 2021, 48(3): 180-187.