一、问题概述
已知现在与一篇英文的阅读文献,要求我们统计出里面字符评率出现的最高的10个单词。源代码地址
二、字符匹配算法
字符串从下标0开始计算
这个问题的难点之一就是字符如匹配 ———— 如何在已知单词的情况,通过字符匹配来计算它出现的频率。
2.1 朴素模式匹配算法
字符串的匹配字符算法应该是我们经常使用的一种算法。理解也非常容易,基本不需要专门的讲解,大家都会。所以如果只会这一种字符匹配算法会显得不太专业(开个玩笑)。接下来,让我们那个我们走进朴素字符算法。
ensp;简单的概括一下朴素模式的匹配算法,其实就是让目标串和源字符串按位进行比较,一旦与不匹配的字符出现。就将源字符串的下标后移一位,在和目标字符串进行比较。一直到出现目标字符或者源字符串的确没有目标字符串结束。
假设现在我们从主串"goodgoogle"中找到目标串"google"。显然利用朴素模式算法的流程图应该是:


相应的它的算法实现也很容易理解:
//朴素模式算法
void match(char *S,char *T)
{
//两串字符的长度
int i = 0,j = 0;//循环变量
int lenS = strlen(S);
int lenT = strlen(T);
while(i<=lenS && j<lenT)
{
if(T[j] == S[i])
{
j++;
i++;
}
else
{
j=0;
i=i-j+1;
}
}
if(j==lenT-1)
{
printf("匹配失败!
");
}
else
{
printf("匹配成功!
");
}
}
2.1、KMP算法模式匹配算法
讲了简单一点的,自然就会有复杂一点的。KMP模式匹配算法(克鲁特-莫里斯-普拉特模式匹配算法)。整个算法最大的两亮点就在于对于目标串,如果其中出现字符(串)重复不多。这个算法的效率将会比朴素模式匹配算法的效率高很多。接下来,我们看一个实例:现在我们要求从主串“abcdefgab”匹配目标串“abcdex”。按照朴素模式匹配算法,我们应该这样来一步一步的计算他们是否匹配,前面5位字符相同,我们直接从出现不匹配的地方开始讨论。

(这个示意图的字符位置是从下标1开始,十分抱歉因为我不想自己画图。)
当然,按照朴素匹配模式,我们可以得到正确的回应。但是,我们有不有更加有效率的算法?
我们换一个关注对象,明显我们的目标串"abcdex",每一个字符都不相同,那么当第5位发现后面字符不在匹配,我们可否根据目标串本身的状态( 就是字符(串)是否重复出现),仅仅靠改变目标串的下标位置而不移动主串的下标来达到字符匹配的目的呢?
这个问题非常简单,当然是可以的啦。就像刚才的那个题目。其实我们的第2 、3、4 、5步都是多余的,因为我们明显知道子串的头为字符和之后的4位均不相同。那么去从头匹配一次是没有必要的。现在我们想法有了接下来就要设计算法了。
现在我们讲一个定义一个next数组,用它来记录目标串每一个字符在对应位置上面的变化记录。(简单的理解一下其实就是,目标串在该位置之前的字符串中,串首和串尾是否有相同的字符串,如果有记录的值也就是相同字符串的字符个数)。下面的公式也可以得出每一个next数组的值。

//获得next索引
void get_next(char* T,char *next)
{
int len = strlen(T);
int i=0;
int j=-1;
next[0] = -1;
while(i<len)
{
if(j == -1 || T[i] == T[j])
{
++i;
++j;
next[i] = j;
}
else
{
j = next[j];
}
}
}
//匹配算法
int kmp(char* S,char* T)
{
int i=0,j=0;
int lenS = strlen(S);
int lenT = strlen(T);
char next[255];
get_next(T,next);
while(i<lenS || j<lenT)
{
if(j==-1 || S[i] == T[j])
{
++i;
++j;
}
else j=next[j];
}
if(j==lenT)
{
return 1;
}
return 0;
}
算法这个东西,就一个办法。理解不到就先背到。好记性不如烂笔头嘛!这个kmp算法大家可以直接用两串字符来实验一下。流程一走什么不懂的都懂了。
三、项目具体实现
3.1、解题思路
对这个问题的大致解题阶段:

拿到这个题目的时候,因为他要实现的功能相对较多。所以,我先对每一个要实现的功能设计了函数。
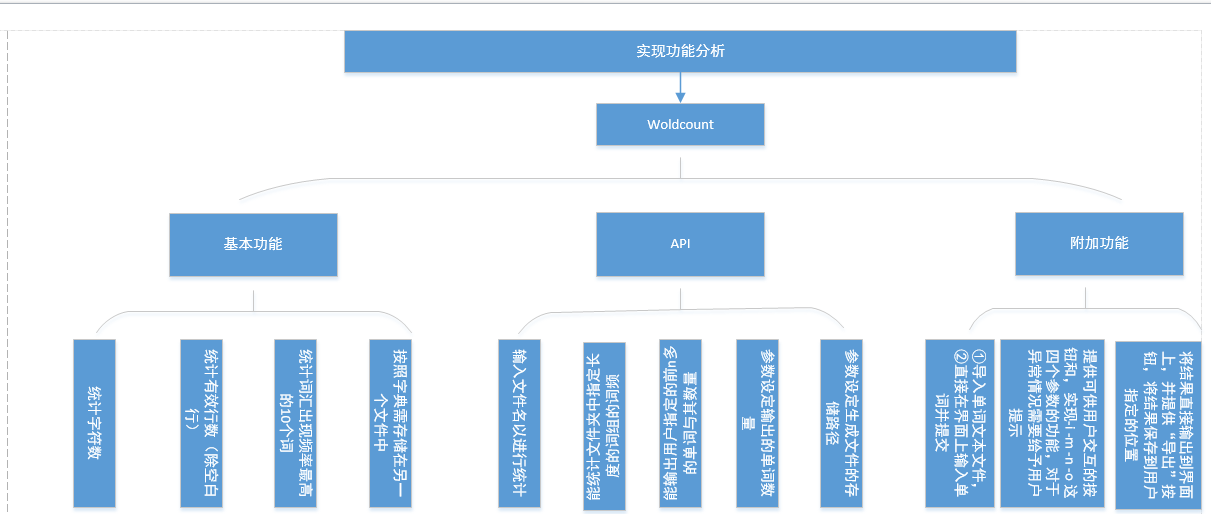
所以,我先对每一个要实现的功能设计了函数。下面是一些我认为相对来说比较麻烦的功能的实现:
3.1.1:对文件中出现的规定字符串的统计

3.1.2:统计文件中出现的规定字符串评率最大的10个字符串。

3.2、封装为类
一共两个类:
基类:
class word_count
{
public:
void f_open();/*打开文件函数*/
void count_acill();/*统计文件中出现的acill 码*/
void count_aphabet();/*统计文件中出现的字母*/
void count_Enum();/*统计文件中出现的字母*/
void count_seperetors();/*统计文件中出现的分割符号*/
void count_line();/*存储文件中的每一行的字符串*/
void display_1();
protected:
ifstream f_in;
private:
int acill;
int aphabate;
int Enum;
int seperetors;
string line_count[MAX];
string line_count_all[MAX];
};
继承类:
class word_count2 :public word_count
{
public :
void read_str();
void store_str(string s);
void display();
void count_limit();
void ruin_node();
private:
count_str *first, *rear;
};
3.3更加细致的思路

3.4重点代码展示
void word_count2::read_str()
{
char ch;//收集每一个文件中字符
string str_1;//记录每一个规定的字符
long pos;//记录f_in的位置
int fir = 0;//判断第一个字符是否为字母
f_in.clear();
f_in.seekg(0, ios::beg);
while (!f_in.eof())
{
f_in.get(ch);
fir++;
if (('a' <= ch && 'z' >= ch) || ('A' <= ch && 'Z' >= ch))
{
int read=1;//记录规定字符创的长度。
//-------------------------------------------------->增加代码
if (fir == 1)
{
pos = f_in.tellg();
}
else
{
pos = f_in.tellg();
f_in.seekg(pos-1);//得到上一个字符
f_in.get(ch);
}
if (('0' <= ch && ch <= '9') || ch== '" ')
{
f_in.seekg(pos);
f_in.get(ch);
while (('a' <= ch && 'z' >= ch) || ('A' <= ch && 'Z' >= ch) || ('0' <= ch && ch <= '9'))
{
f_in.get(ch);
}
}//-------------------------------------------------------------------------------------------------------------------
else
{
read++;
int k;
f_in.seekg(pos);
//f_in.get(ch);
for ( k = 1; k < 4; k++)
{
read++;
f_in.get(ch);
if ( ch<'A' || (ch > 'Z'&& ch < 'a') || ch>'z' ) break;
}
if (k == 4)
{
f_in.get(ch);
while (('a' <= ch && 'z' >= ch) || ('A' <= ch && 'Z' >= ch)|| ( '0' <= ch && ch <= '9'))
{
f_in.get(ch);
read++;
}
pos = f_in.tellg();
f_in.seekg(pos - read);
getline(f_in, str_1, ch);
store_str(str_1);
f_in.seekg(pos);
}
}
}
}
}