| Scrapy 框架架构 |
一.Scrapy框架是基于Twisted的异步框架,纯Python实现的爬虫框架,耦合程度低,可拓展性极强。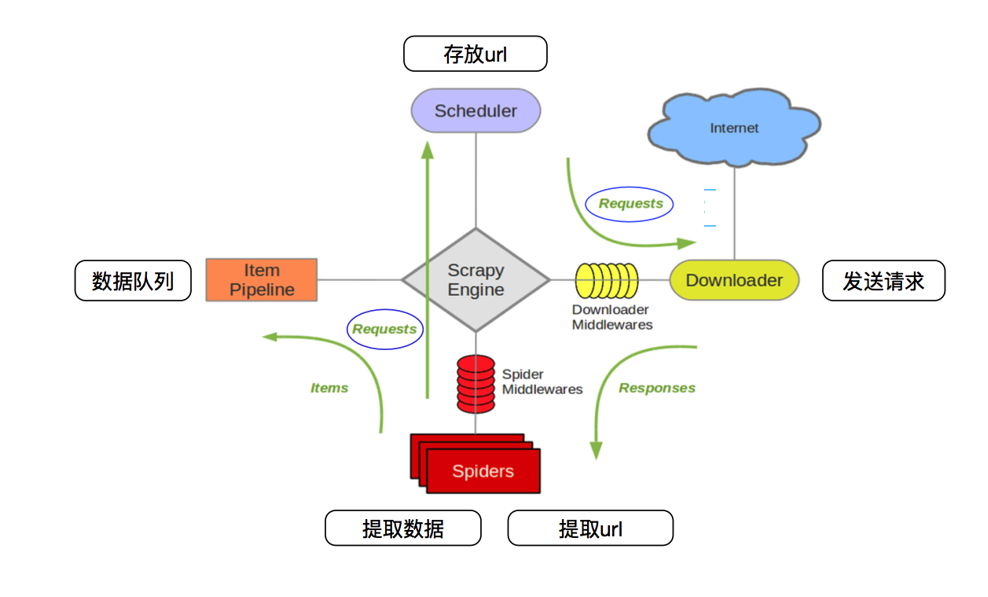
1.Engine引擎,处理整个系统的数据流、触发事物、框架的核心
2.item项目,定义爬虫爬取结果的数据结构,爬取的数据会被赋值成该item对象
3.Schedule调度器,接受engine发过来的request放入队列,然后engine再次请求时,将request发送给engine
4.Downloader下载器,下载网页内容,并将网页返回给spiders
5.spiders蜘蛛,定义爬取逻辑和网页解析规则,负责解析response提取结果并返回新的request
6.item Pipeline项目管道,负责处理由蜘蛛从网页中抽取项目,进行清洗,验证和存储数据
7.Downloader Middlewares下载器中间件,主要处理engine和Downloader之间的请求及响应
8.spider Middlewares 蜘蛛中间件,主要处理spiders输入的响应和输出结果及新的请求
| scrapy数据流 |
1.engine打开网站,向这个网站的spider请求第一个要爬取的URL
2.engine通过Scheduler以request的形式调度第一个URL
3.engine向Scheduler请求下一个要爬取的URL
4.Scheduler返回下一个要爬取的URL给engine,engine将URL通过Downloader Middlewares 转发给Downloader下载
5.一旦页面下载完毕,Downloader生成该页面的Response,并将其通过Downloader Middlewares发送给Engine
6.Engine从下载器中接受Response,并将其通过Spider Middlewares发送给Spider处理
7.Spider处理Response,并返回爬取到的Item及新的Request给Engine
8.Engine将Spider返回的Item给Item Pipeline,将新的Request给Scheduler
9.重复第2到第8步,直到Scheduler中没有更多的Request,Engine关闭该网站,爬取接受
| Scrapy项目认识 |
1.安装Scrapy通过pip安装 pip install Scrapy
2.创建Scrapy项目,直接通过scrapy命令 scrapy startproject XXXXX 这个命令可以在任意文件夹运行,我们在一个文件夹中用scrapy startproject Tanzhou命令生成一个Tanzhou的文件夹,再进入Tanzhou文件中,用命令scrapy genspider Tanzhous shiguangkey.com在文件夹中生成Tanzhous.py文件
3.构造请求
class TanzhousSpider(scrapy.Spider): name = 'Tanzhous' allowed_domains = ['shiguangkey.com'] baseUrl = 'https://www.shiguangkey.com/course/list?page=' offset=0 start_urls = [baseUrl + str(offset)]
4.创建Item,在items.py文件中
import scrapy
class TanzhouItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 课程金额
money = scrapy.Field()
# 课程名称
title = scrapy.Field()
#课程人数
personNum=scrapy.Field()
5.解析响应,在Tanzhous.py类的parse()方法中直接对response进行解析,并添加到item中,再返回Item。后面使用了前面offset来构造新的request,使用callback
函数再次解析request
def parse(self, response):
nodes=response.xpath('.//div[@class="course-item w192 h240 fl"]')
for node in nodes:
item=TanzhouItem()
item['money']=node.xpath('normalize-space(.//div[@class="item-line"]/span/text())').extract_first()
item['title']=node.xpath('normalize-space(.//div[@class="itemcont"]/a/text())').extract_first()
item['personNum']=node.xpath('.//div[@class="item-line"]/a/text()').extract_first()
yield item
if self.offset <24:
self.offset += 1
url = self.baseUrl + str(self.offset)
yield scrapy.Request(url, callback=self.parse)
6.进入目录运行项目使用命令 scrapy crawl Tanzhous,可以运行结果,
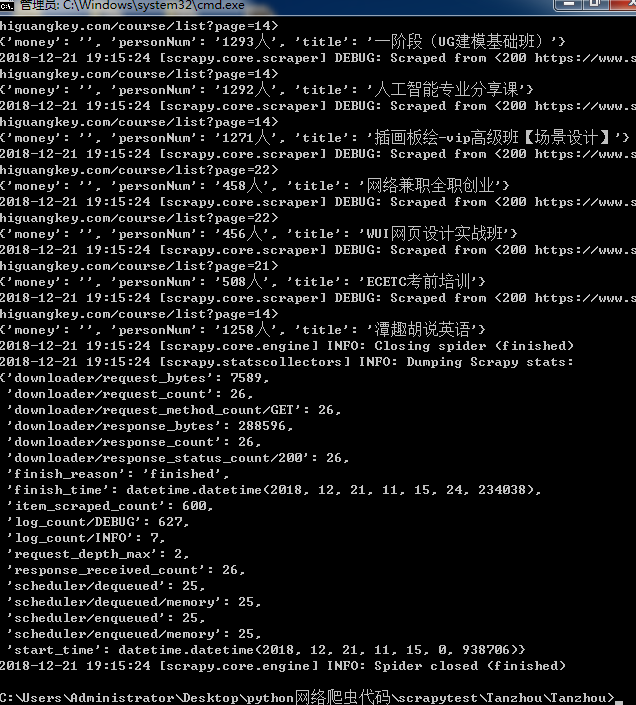
这只是一部分内容,通过Scrapy框架可以做到边解析边爬取,直到爬取结束,停止
7.可以将命令窗口爬取到的内容保存到文件,执行下面的命令保存成json文件 scrapy crawl Tanzhous -o Tanzhous.json运行之后就可以看见json文件了
还可以通过命令输出csv、xml、pickle、marshal格式
scrapy crawl Tanzhous -o Tanzhous.csv
scrapy crawl Tanzhous -o Tanzhous.xml
scrapy crawl Tanzhous -o Tanzhous.pickle
scrapy crawl Tanzhous -o Tanzhous.marshal
8.将结果保存到MongoDB数据库要通过定义Item Pipeline实现,修改pipeline.py文件添加新类TextPipeline 实现process_item()方法,ItemPipeline是项目管道,前面生成的Item都要被送到ItemPipeline进行处理,也就是清理Html数据,验证爬虫数据,查重,再保存到数据库中
import pymongo
from scrapy.exceptions import DropItem
class TextPipeline(object):
def __init__(self):
self.limit=50
def process_item(self, item, spider):
if item['title']:
if len(item['title'])>self.limit:
item['title']=item['title'][0:self.limit].rstrip()+'...'
return item
else:
return DropItem('Missing Text')
这是对数据的再处理以便保存到数据库。同样在pipeline.py中定义另一个Pipeline,我们实现另一个MongoPipeline如下
class MongoPipeline(object):
def __init__(self, mongo_uri,mongo_db):
self.mongo_uri=mongo_uri
self.mongo_db=mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client=pymongo.MongoClient(self.mongo_uri)
self.db=self.client[self.mongo_db]
def process_item(self,item,spider):
name=item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
我们还要在setting.py中配置内容
ITEM_PIPELINES={ 'Tanzhou.pipelines.TextPipeline':300, 'Tanzhou.pipelines.MongoPipeline':400, } MONGO_URI='localhost' MONGO_DB='TanzhouW'
还要启动mongodb数据库,在执行爬取运行命令 scrapy crawl Tanzhous 爬取结束后MongoDB中创建了一个数据库如下
