字符串的驻留机制

简单来说就是 当字符串的值相同时,不开辟新的空间,而是直接指向该字符串

字符串驻留机制的优缺点
·当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的。
·在需要进行字符串拼接时建议使用str类型的join方法,而非+,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率要比“+”效率高
字符串的常用操作
查询操作

1 # 2 # @author:浊浪 3 # @version:0.1 4 # @time: 2021/3/21 16:51 5 # 6 7 # 字符串的查询操作 8 s = 'hello,hello' 9 print(s.index('lo')) # 3 10 print(s.find('lo')) # 3 11 print(s.rindex('lo')) # 9 12 print(s.rfind('lo')) # 9 13 14 # 查找不存在的字符 15 print(s.find('k')) # -1 16 # print(s.index('k')) ValueError: substring not found 17 print(s.rfind('k')) # -1 18 # print(s.rindex('k')) ValueError: substring not found
字符串的大小写转换操作的方法
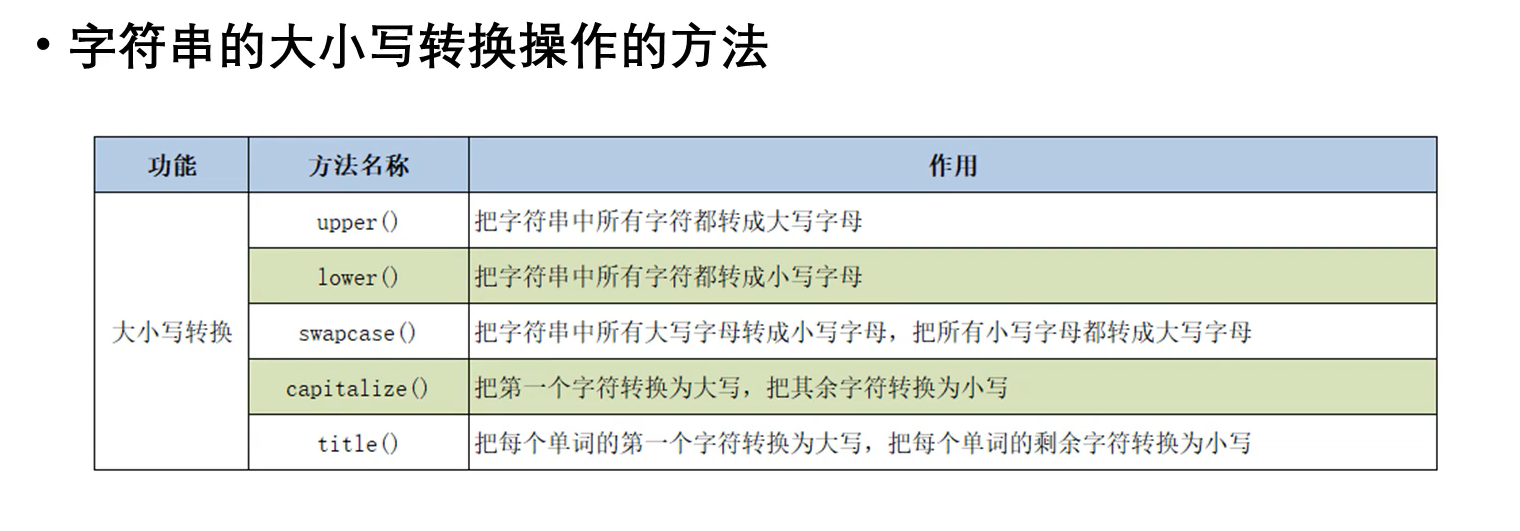
1 # 2 # @author:浊浪 3 # @version:0.1 4 # @time: 2021/3/29 9:11 5 # 6 s = 'hello world!' 7 a = s.upper() # 转成大写之后会产生一个新的字符串对象 8 print(a, id(a)) 9 print(s, id(s)) 10 print(s.lower(), id(s.lower())) 11 12 print(s == s.lower()) # True 13 print(s is s.lower()) # False 14 15 s2 = 'hello, Python' 16 print(s2.swapcase()) 17 print(s2.title()) 18 print(s2.capitalize())
字符串内容对齐操作的方法

1 # 2 # @author:浊浪 3 # @version:0.1 4 # @time: 2021/3/29 9:19 5 # 6 7 s = 'hell, world' 8 # 居中对齐 9 print(s.center(20, '*')) # ****hell, world***** 10 11 # 左对齐 12 print(s.ljust(20, '*')) # hell, world********* 13 14 # 右对齐 15 print(s.rjust(20, '*')) # *********hell, world 16 17 # 右对齐 使用0填充 18 print(s.zfill(20)) # 000000000hell, world 19 print('-8967'.zfill(8)) # -0008967 这个是添加 在符号的后面 20 21 # 长度小于实际长度则返回原字符串 22 print(s.center(10, "*")) # hell, world
字符串劈分操作的方法
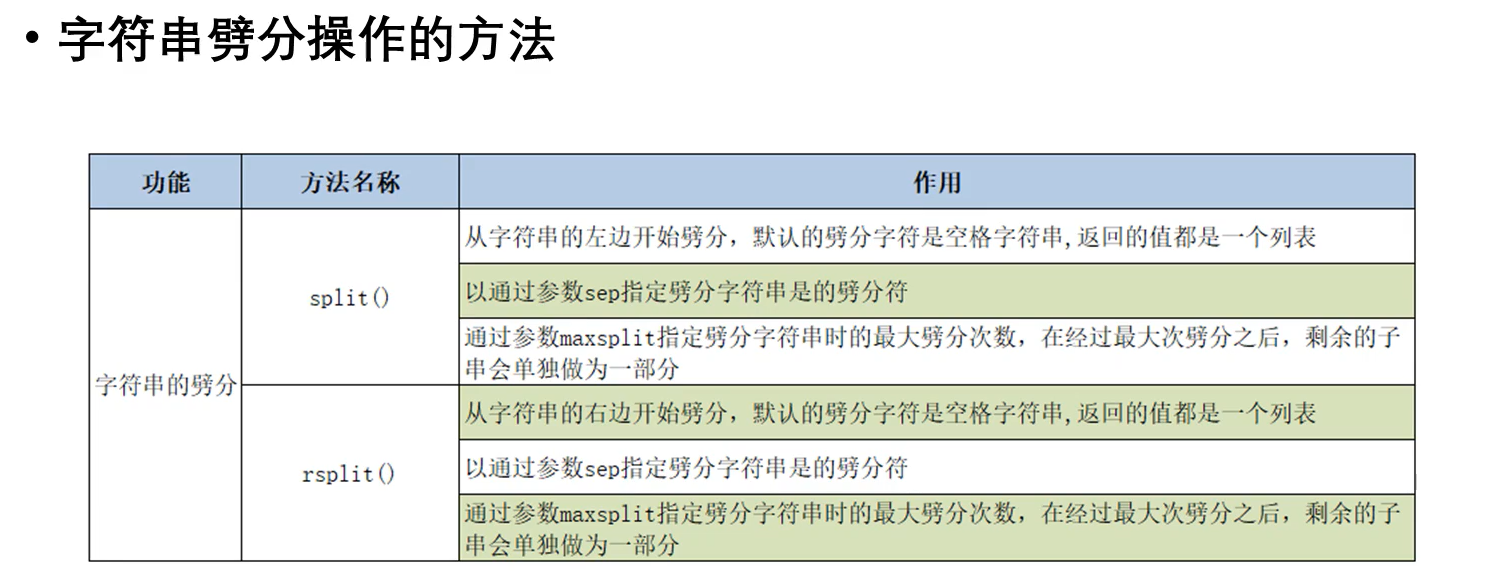
1 # 2 # @author:浊浪 3 # @version:0.1 4 # @time: 2021/3/29 9:31 5 # 6 7 s = 'hello world Python' 8 print(s.split()) # ['hello', 'world', 'Python'] 9 10 s1 = 'hello*world*Python' 11 print(s1.split()) # ['hello*world*Python'] 12 print(s1.split(sep='*')) # ['hello', 'world', 'Python'] 13 14 # 指定最大分割次数 15 print(s1.split(sep='*', maxsplit= 1)) # ['hello', 'world*Python'] 16 17 # rsplit 从右边开始分割 18 print(s1.rsplit(sep='*', maxsplit= 1)) # ['hello*world', 'Python']
判断字符串的操作方法

字符串的切片操作方法
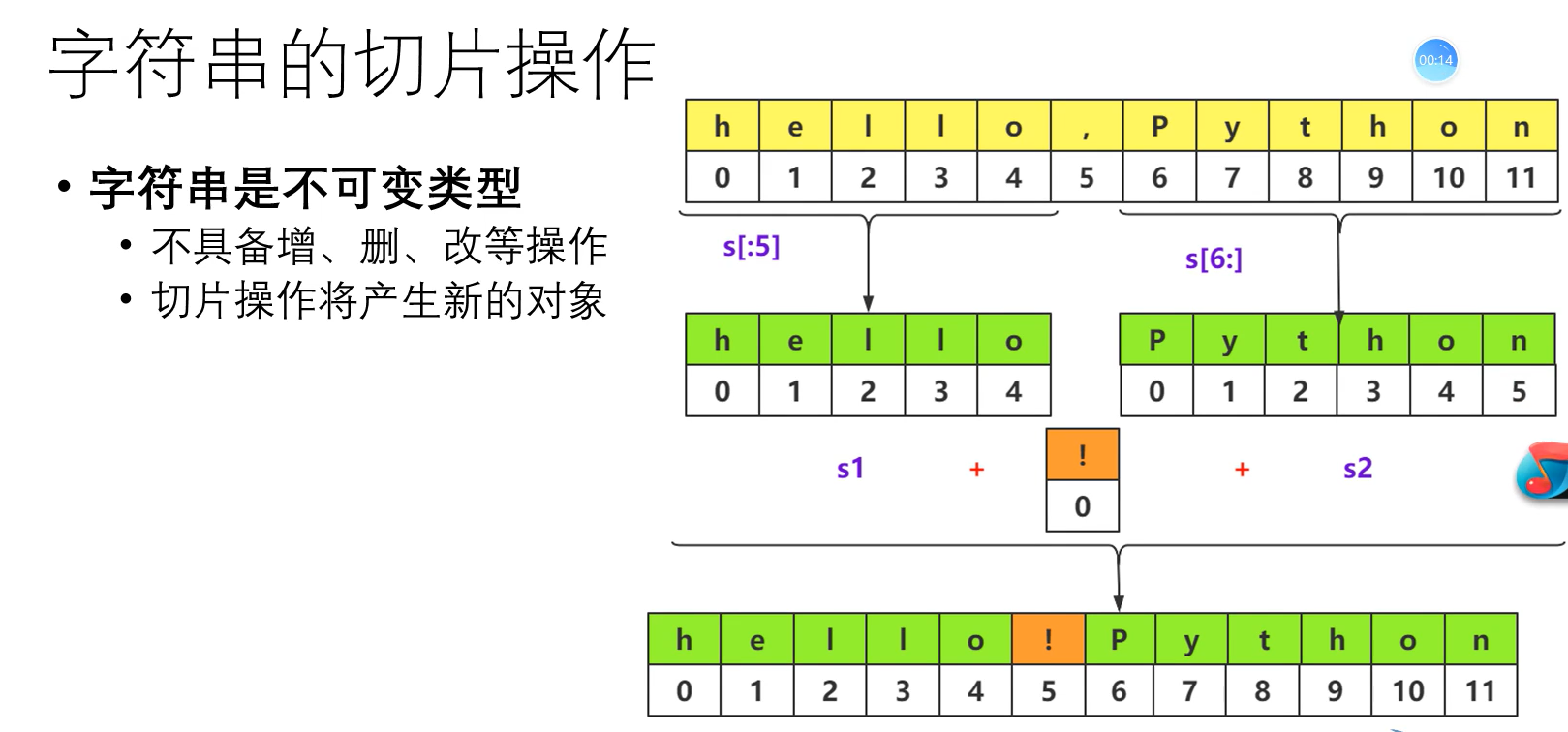
原理和列表的切片相同

字符串的其他操作方法

1 # 2 # @author:浊浪 3 # @version:0.1 4 # @time: 2021/3/29 10:02 5 # 6 s = 'hello, world' 7 print(s.replace('world', 'python')) # hello, python 8 9 s1 = 'hello, world world world world' 10 print(s1.replace('world', 'python', 2)) # hello, python python world world 11 12 lst = ['hello', 'java', 'python'] 13 print('|'.join(lst)) # hello|java|python 14 print(''.join(lst)) # hello|java|python 15 16 t = ('hello', 'java', 'python') # 同上 17 18 print('#'.join('python')) # p#y#t#h#o#n
格式化字符串

1 # 2 # @author:浊浪 3 # @version:0.1 4 # @time: 2021/3/29 10:25 5 # 格式化字符串 6 7 # (1) % 占位符 8 name = '张三' 9 age = 20 10 print('我叫%s,今年%d岁' % (name,age)) # 我叫张三,今年20岁 11 12 # (2) {} 13 print('我叫{0},今年{1}岁'.format(name,age)) # 我叫张三,今年20岁 14 15 # (3) f-string 16 print(f'我叫{name},今年{age}岁') # 我叫张三,今年20岁 17 18 # 宽度 19 print('%7d' % 89) # 89 20 # 精度 21 print('%.3f' % 3.14159) #3.142 22 # 同时表示宽度和精度 23 print('%10.3f' % 3.1415926) # 3.142 24 25 # 另一种方法 26 # 0表示第一个占位符 如有多个的时候就需要写,一个时可以省略如下面0可省略 27 print('{0:.3}'.format(3.1415926)) # .3表示是三个数 3.14 28 print('{0:.3f}'.format(3.1415926)) # .3f表示是小数点后三个数 3.142 29 print('{0:10.3f}'.format(3.1415926)) # 同时设置宽度和精度 3.142
字符串的编码转换
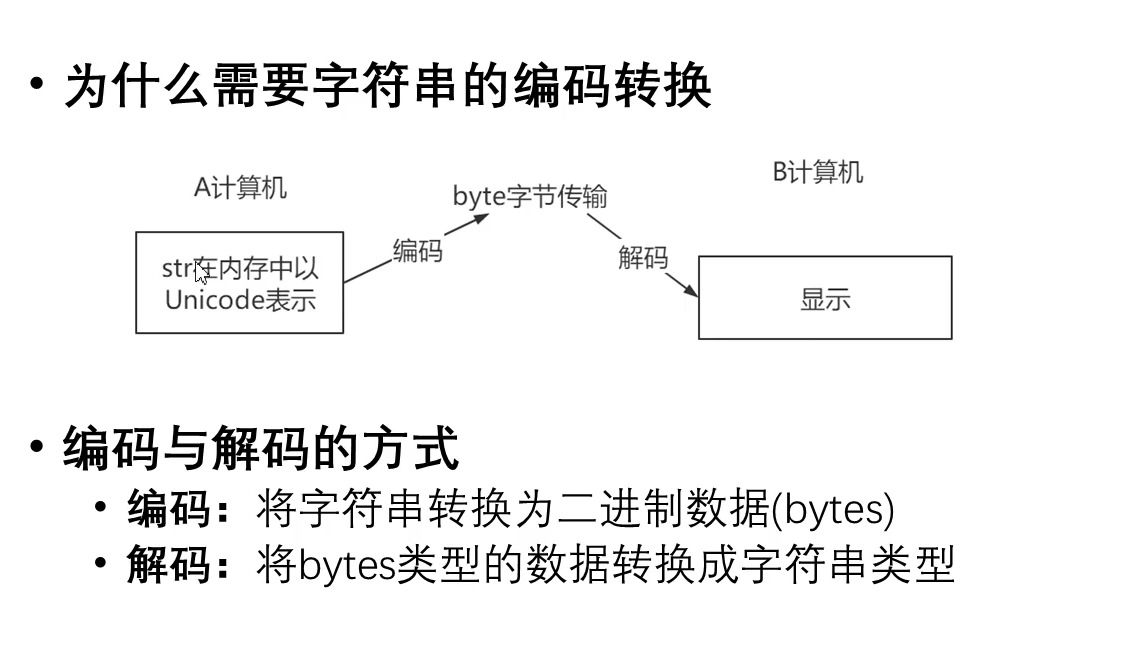

编码和解码要用同一种编码格式