1.python中使用
"""
@author :Eric-chen
@contact :sygcrjgx@163.com
@time :2020/8/13 17:43
@desc :
"""
import re
# pattern=re.compile("^.*(ods_ogg_erp_cd[w-]{1,1000}).*$")
pattern=re.compile("ods_ogg_erp_cd[w-]{1,1000}")
with open('F:pythoncodespythonLearnmappingScript_erp_cd_e5_26.xml', 'r',encoding='utf8') as f:
line=f.readline()
while line:
m=pattern.findall(line)
if m:
print(m)
line=f.readline()
2.java中使用
package com;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class test {
public static void main(String[] args) throws IOException {
Pattern pattern = Pattern.compile("ods_ogg_erp_cd[\w-]{1,1000}");
String path = "F:\python\codes\pythonLearn\mappingScript_erp_cd_e5_26.xml";
File file = new File(path);
List<String> stringList = FileUtils.readLines(file, "utf-8");
for (String line : stringList) {
Matcher matcher = pattern.matcher(line);
if (matcher.find())
System.out.println(matcher.group(0));
}
}
}
3.Sql中使用
create table t_0814 (col1 varchar2(10));
insert into t_0814 values ('aaa');
insert into t_0814 values ('aaa');
insert into t_0814 values ('aaa');
insert into t_0814 values ('aaa');
insert into t_0814 values ('BBB');
select * from t_0814 where regexp_like(col1,'[a-z]');
4.shell命令
#!/bin/bash
grep "ods_ogg_erp_cdw{1,1000}" /root/mappingScript_erp_cd_e3_09.xml >>tmp.txt
let i=0
while read line
do
line=${line#*>}
echo ${line%<*}
let i=i+1
done <tmp.txt
rm -rf tmp.txt
echo "$i"
5.vi
g/pattern/d 是找到pattern, 删之
v/pattern/d 是找到非pattern,删之
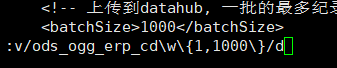
:v/ods_ogg_erp_cdw{1,1000}/d
:%s/ <datahubTopic>/
正则替换
:s/ <datahubTopic>/
正常替换
:%s/</datahubTopic>/ 有问题
用#作分割符,这样可以避免和/ 冲突。
:%s#</datahubTopic>/