Spark数据本地化-->如何达到性能调优的目的
1.Spark数据的本地化:移动计算,而不是移动数据
2.Spark中的数据本地化级别:
| TaskSetManager 的 Locality Levels 分为以下五个级别: |
| PROCESS_LOCAL |
| NODE_LOCAL |
| NO_PREF |
| RACK_LOCAL |
| ANY |
PROCESS_LOCAL 进程本地化:task要计算的数据在同一个Executor中

NODE_LOCAL 节点本地化:速度比 PROCESS_LOCAL 稍慢,因为数据需要在不同进程之间传递或从文件中读取
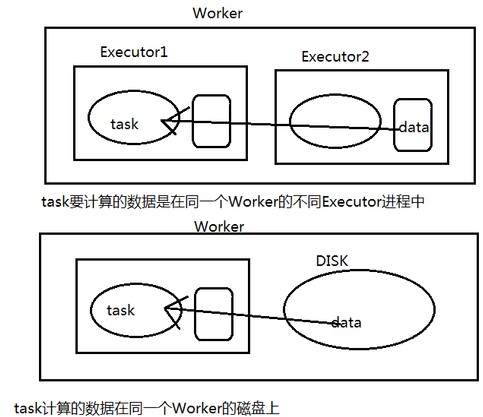
情况一:task要计算的数据是在同一个Worker的不同Executor进程中
情况二:task要计算的数据是在同一个Worker的磁盘上,或在 HDFS 上,恰好有 block 在同一个节点上。
Spark计算数据来源于HDFS,那么最好的数据本地化级别就是NODE_LOCAL
NODE_PREF 没有最佳位置这一说,数据从哪里访问都一样快,不需要位置优先。比如说SparkSQL读取MySql中的数据
RACK_LOCAL 机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据及文件 IO,比 NODE_LOCAL 慢
情况一:task计算的数据在Worker2的Executor中
情况二:task计算的数据在Worker2的磁盘上
ANY 跨机架,数据在非同一机架的网络上,速度最慢
3.Spark中的数据本地化由谁负责?
DAGScheduler,TaskScheduler
val rdd1 = rdd1.cache
rdd1.map.filter.count()
Driver(TaskScheduler)在发送task之前,首先应该拿到RDD1缓存在哪一些节点上(node1,node2)-->这一步就是由DAGScheduler通过cacheManager对象调用getPreferredLocations()来拿到RDD1缓存在哪些节点上,TaskScheduler根据这些节点来发送task。
val rdd1 = sc.textFile("hdfs://...") //rdd1中封装了是这个文件所对应的block的位置,getPreferredLocation()-->TaskScheduler调用拿到partition所对应的数据的位置
rdd1.map.filter.count()
Driver(TaskScheduler)在发送task之前,首先应该拿到rdd1数据所在的位置(node1,node2)-->RDD1封装了这个文件所对应的block的位置,TaskScheduler通过调用getPreferredLocations()拿到partition所对应的数据的位置,TaskScheduler根据这些位置来发送相应的task
总的来说:
Spark中的数据本地化由DAGScheduler和TaskScheduler共同负责。
DAGScheduler切割Job,划分Stage, 通过调用submitStage来提交一个Stage对应的tasks,submitStage会调用submitMissingTasks,submitMissingTasks 确定每个需要计算的 task 的preferredLocations,通过调用getPreferrdeLocations()得到partition 的优先位置,就是这个 partition 对应的 task 的优先位置,对于要提交到TaskScheduler的TaskSet中的每一个task,该task优先位置与其对应的partition对应的优先位置一致。
TaskScheduler接收到了TaskSet后,TaskSchedulerImpl 会为每个 TaskSet 创建一个 TaskSetManager 对象,该对象包含taskSet 所有 tasks,并管理这些 tasks 的执行,其中就包括计算 TaskSetManager 中的 tasks 都有哪些locality levels,以便在调度和延迟调度 tasks 时发挥作用。
4.Spark中的数据本地化流程图
即某个 task 计算节点与其输入数据的位置关系,下面将要挖掘Spark 的调度系统如何产生这个结果,这一过程涉及 RDD、DAGScheduler、TaskScheduler,搞懂了这一过程也就基本搞懂了 Spark 的 PreferredLocations(位置优先策略)
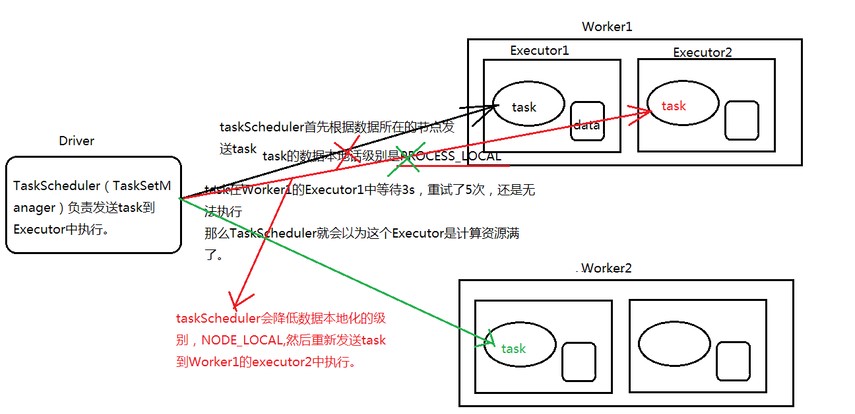
第一步:PROCESS_LOCAL-->TaskScheduler首先根据数据所在的节点发送task,
如果task在Worker1的Executor1中等待了3s(这个3s是spark的默认等待时间,通过spark.locality.wait来设置,可以在SparkConf()中修改),重试了5次,还是无法执行
TaskScheduler会降低数据本地化的级别,从PROCESS_LOCAL降到NODE_LOCAL
第二步:NODE_LOCAL-->TaskScheduler重新发送task到Worker1中的Executor2中执行,
如果task在Worker1的Executor2中等待了3s,重试了5次,还是无法执行
TaskScheduler会降低数据本地化的级别,从NODE_LOCAL降到RACK_LOCAL
第三步:RACK_LOCAL -->TaskScheduler重新发送task到Worker2中的Executor1中执行。
第四步:当task分配完成之后,task会通过所在Worker的Executor中的BlockManager来获取数据,如果BlockManager发现自己没有数据,那么它会调用getRemote()方法,通过ConnectionManager与原task所在节点的BlockManager中的ConnectionManager先建立连接,然后通过TransferService(网络传输组件)获取数据,通过网络传输回task所在节点(这时候性能大幅下降,大量的网络IO占用资源),计算后的结果返回给Driver。
总结:
TaskScheduler在发送task的时候,会根据数据所在的节点发送task,这时候的数据本地化的级别是最高的,如果这个task在这个Executor中等待了三秒,重试发射了5次还是依然无法执行,那么TaskScheduler就会认为这个Executor的计算资源满了,TaskScheduler会降低一级数据本地化的级别,重新发送task到其他的Executor中执行,如果还是依然无法执行,那么继续降低数据本地化的级别...
现在想让每一个task都能拿到最好的数据本地化级别,那么调优点就是等待时间加长。注意!如果过度调大等待时间,虽然为每一个task都拿到了最好的数据本地化级别,但是我们job执行的时间也会随之延长
spark.locality.wait 3s//相当于是全局的,下面默认以3s为准,手动设置了,以手动的为准spark.locality.wait.processspark.locality.wait.nodespark.locality.wait.racknewSparkConf.set("spark.locality.wait","100")