| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 100 |
| · Estimate | · 估计这个任务需要多少时间 | 510 | 648 |
| Development | 开发 | 100 | 200 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 25 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 20 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 15 | 30 |
| · Coding | · 具体编码 | 80 | 80 |
| · Code Review | · 代码复审 | 5 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 5 | 5 |
| Reporting | 报告 | 30 | 60 |
| · Test Repor | · 测试报告 | 50 | 50 |
| · Size Measurement | · 计算工作量 | 5 | 8 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
主函数里包含计算字符数、单词数、行数以及前十的单词。
int main() { double t = clock(); ofstream os("result.txt", ios::out); if (!os) { cerr << "Cannot write file result.txt!" << endl; exit(1); } get_characters(os); get_words(10, os); get_lines(os); priority_words(os); os.close(); cout<<"< Elapsed Time: "<<(clock()-t)/CLOCKS_PER_SEC<<" >"<<endl; return 0; }
用桶来记录字符串出现的次数,再用结构体使用迭代器将桶内的字符串和出现次数提取出来,写一个排序函数,将字符串按优先级排序(出现次数高的、同样频率字典序在前的优先级高)。最后提取前十个优先级最高的。
其他的字符统计之类的,只要采用函数进行封装,从文档内读取并计数即可。
struct node{ string sss; int num; //int value; }q[10005]; map<string, int>word; FILE *fp, *os, *infile; char ch = 'a'; ll characters = 0, lines = 0, words = 0;
void get_characters(ofstream &os) //得到字符数,用字符逐个输入 void get_words(const int &cnt, ofstream &os) //以字符串读入,遇到分隔符再记录是否是单词,单词用桶装 void get_lines(ofstream &os) //以字符读入,定义一个字符变量动态记录上一读入的字符,若连续出现两个' '则行数不变。 void priority_words(ofstream &os) //采用结构体排序,输出前十 //排序算法 bool cmp(node t1, node t2) { if(t1.num!=t2.num) return t1.num > t2.num; int len1 = t1.sss.length(); int len2 = t2.sss.length(); int i; for(i = 0; i < len1 && i < len2; i++) { if(t1.sss[i] != t2.sss[i]) { return t1.sss[i] < t2.sss[i]; break; } } if(i == len1) return true; if(i == len2) return false; } sort(q, q+v, cmp);
唉,请让我发一条有声评论:“好难过,这不是我要的结果”。
在我所想到的所有bug攻克后,代码轰轰烈烈的出炉。然后,然后,请唱出git是什么鬼!

就这样,在最后的几个小时里,我百度,我翻文件,但是,.git我都找不到。最后找到的时候看了下时间,咳咳~~~
找到的时候我在干嘛呢?在这里跟大家分享我的心情。为什么呢,因为已经没有时间了。
我只能说,多么痛的领悟,原来代码已是我的全部,曾经做时的每一步,都好辛苦,唔~~~

留下此篇博客,当我今后之教训,以后作业发布的第一天,我就要开始做!开始做!开始做!这样的经历使我心痛!!!
请同样有如此感悟的同学联系我吧!咱们约学习啊!不做完不睡觉那种。
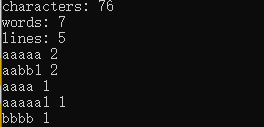
测试用例:
aaaaa
aaaaa1
aaaaa
aaaa bbbb
aabb1,123aacc123aacc123aacc,aabb1
结果:
耗时:
< Elapsed Time: 0.007 >
完整的博客下周把其他内容块补上再重新发吧!