线性和多项式回归
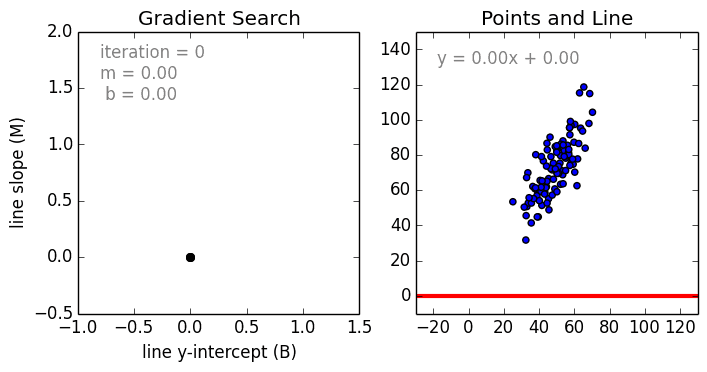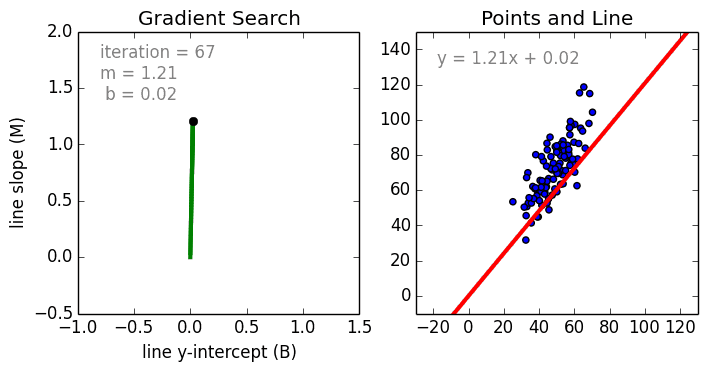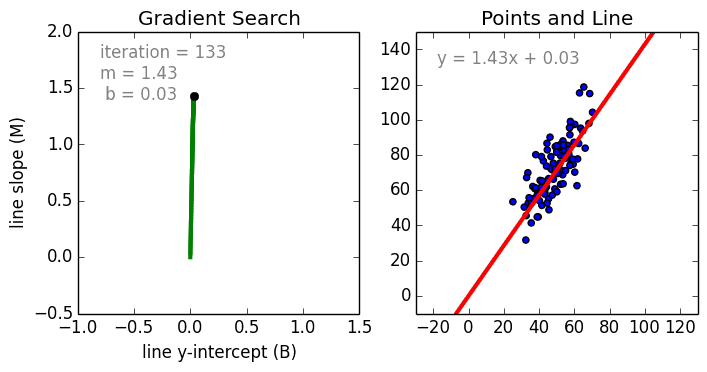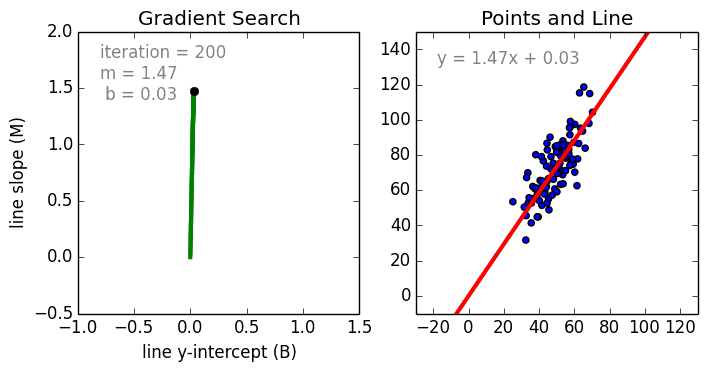
在这一简单的模型中,单变量线性回归的任务是建立起单个输入的独立变量与因变量之间的线性关系;而多变量回归则意味着要建立多个独立输入变量与输出变量之间的关系。除此之外,非线性的多项式回归则将输入变量进行一系列非线性组合以建立与输出之间的关系,但这需要拥有输入输出之间关系的一定知识。训练回归算法模型一般使用随机梯度下降法(SGD)。
优点:
建模迅速,对于小数据量、简单的关系很有效;
线性回归模型十分容易理解,有利于决策分析。
缺点:
对于非线性数据或者数据特征间具有相关性多项式回归难以建模;
难以很好地表达高度复杂的数据。
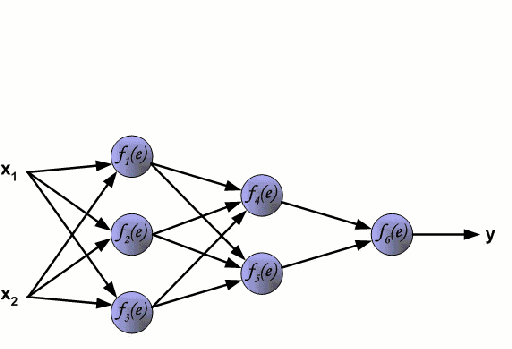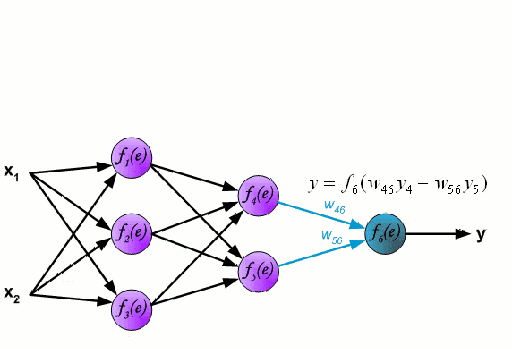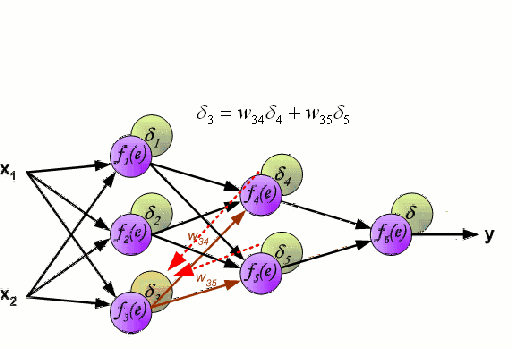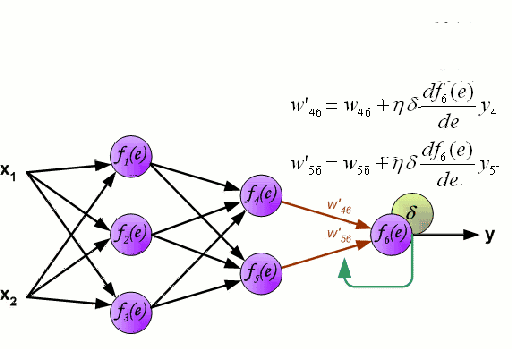
神经网络由一系列称为神经元的节点通过内部网络连接而成,数据的特征通过输入层被逐级传递到网络中,形成多个特征的线性组合,每个特征会与网络中的权重相互作用。随后神经元对线性组合进行非线性变化,这使得神经网络模型具有对多特征复杂的非线性表征能力。神经网络可以具有多层结构,以增强对于输入数据特征的表征。人们一般利用随机梯度下降法和反向传播法来对神经网络进行训练,请参照上述图解。
优点:
多层的非线性结构可以表达十分复杂的非线性关系;
模型的灵活性使得我们不需要关心数据的结构;
数据越多网络表现越好。
缺点:
模型过于复杂,难以解释;
训练过程需要强大算力、并且需要微调超参数;
对数据量依赖大,但常规机器学习问题则使用较小量数据。
回归树和回归森林
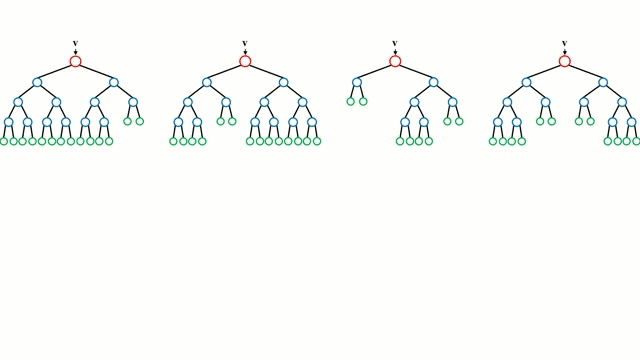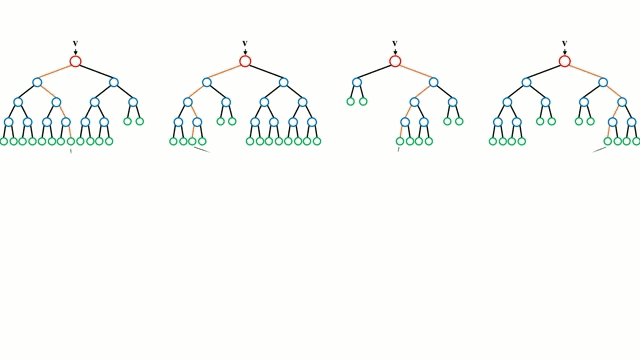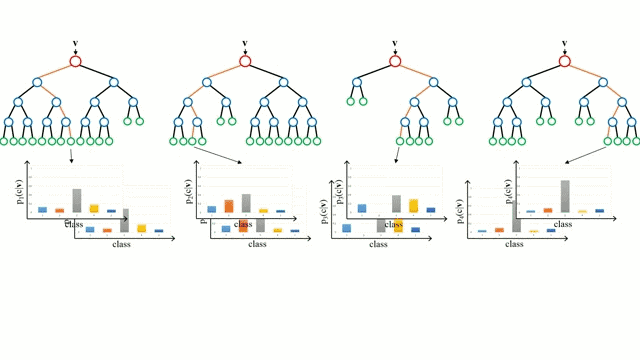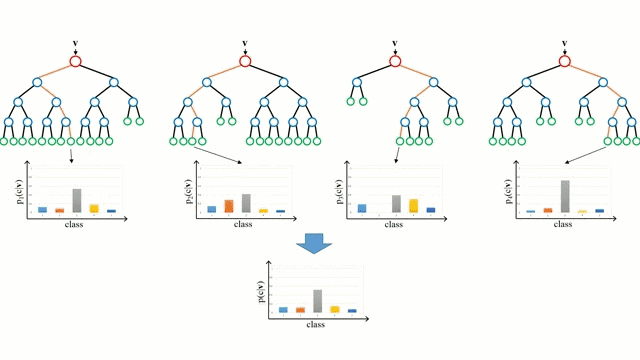
让我们从最基本的概念出发,决策树是通过遍历树的分支并根据节点的决策选择下一个分支的模型。树型感知利用训练数据作为数据,根据最适合的特征进行拆分,并不断进行循环指导训练数据被分到一类中去。建立树的过程中需要将分离建立在最纯粹的子节点上,从而在分离特征的情况下保持分离数目尽可能的小。纯粹性是来源于信息增益的概念,它表示对于一个未曾谋面的样本需要多大的信息量才能将它正确的分类。实际上通过比较熵或者分类所需信息的数量来定义。而随机森林则是决策树的简单集合,输入矢量通过多个决策树的处理,最终的对于回归需要对输出数据取平均、对于分类则引入投票机制来决定分类结果。
优点:
具有很高的复杂度和高度的非线性关系,比多项式拟合拥有更好的效果;
模型容易理解和阐述,训练过程中的决策边界容易实践和理解。
缺点:
由于决策树有过拟合的倾向,完整的决策树模型包含很多过于复杂和非必须的结构。但可以通过扩大随机森林或者剪枝的方法来缓解这一问题;
较大的随机数表现很好,但是却带来了运行速度慢和内存消耗高的问题。