一个小小的地铁名,就是一座城市风貌的一部分,它反映着不同地方的水土,也承载着各个城市的文化和历史。
本文试图从地铁站名出发,一探这一个个名字能否反映出每一寸土地的性格,文化。
参考文章:183条地铁线路,3034个地铁站,发现中国地铁名字的秘密。
-
数据集准备:
-
爬取高德地图地铁图:http://map.amap.com/subway/index.html
1 ''' 2 获取地铁线路图数据 3 存为metro.csv 4 ''' 5 import urllib 6 import re 7 import json 8 import requests 9 from lxml import etree 10 11 header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
-
-
首先对城市信息进行处理,需要获得城市对应ID,城市名英文名称,根据xpath进行对应字段爬取。
-
1 def City(): 2 ''' 3 爬取城市名及对应ID 4 ''' 5 url = 'http://map.amap.com/subway/index.html' 6 response = requests.get(url,header) 7 #print(response.encoding) #编码格式为 ISO-8859-1 8 html =response.text 9 html =html.encode('ISO-8859-1').decode('utf-8') #对网页内容编码再解码,name才能正常显示中文 10 11 content = etree.HTML(html) 12 name = content.xpath("//div[@class='sw-city']//a/text()") 13 city_name = content.xpath("//div[@class='sw-city']//a/@cityname") 14 city_num = content.xpath("//div[@class='sw-city']//a/@id") 15 16 for i in range(len(name)): 17 Metro(name[i],city_name[i],city_num[i]) 18 print('正在下载'+name[i]+'地铁线路图')
-
将获得的城市信息传进相关城市地铁url,如广州地铁图为 http://map.amap.com/service/subway?_1558630393009&srhdata=4401_info_guangzhou.json
1 def Metro(name,city_name,city_num): 2 ''' 3 爬取详细地铁站名 4 ''' 5 url = 'http://map.amap.com/service/subway?srhdata='+city_num + '_drw_'+ city_name + '.json' 6 response = requests.get(url,header) 7 html = response.text 8 result = json.loads(html) 9 10 for i in result['l']: 11 for j in i['st']: 15 with open('./metro.csv','a+') as f: 16 f.write(name+','+i['ln']+','+j['n']+' ')
实际爬取网页过程中,往往从单个城市出发,再初步添加参数多城市进行爬取
-
爬取得到metro.csv文件
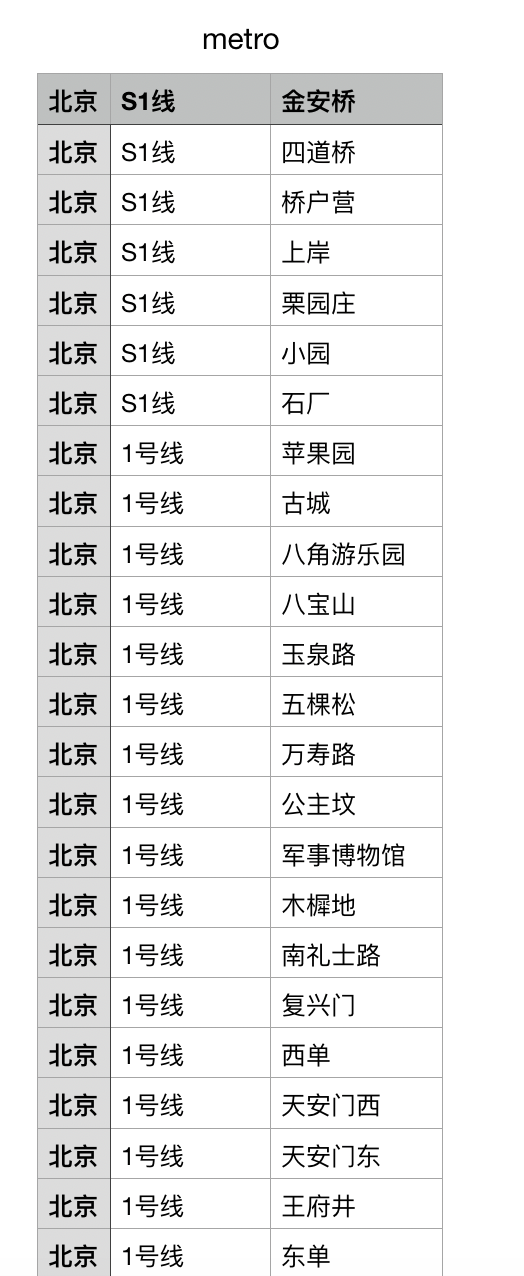
-
数据可视化
-
获得数据后,对数据进行清洗并进行可视化
1 ''' 2 对数据进行清洗及可视化 3 ''' 4 #可视化包pyecharts使用:https://blog.csdn.net/wsp_1138886114/article/details/80509375 5 #本案例使用版本为pip install pyecharts==0.5.11,最新的1.0.版本用法不同 6 7 import pandas as pd 8 from pyecharts import Bar,Geo 9 import matplotlib.pyplot as plt 10 import numpy as np 11 import seaborn as sns 12 import jieba 13 from wordcloud import WordCloud, ImageColorGenerator
-
-
打开数据集,根据城市名进行分组,将地铁站名数量相加后再放入数据集中。
-
1 def main(): 2 3 df = pd.read_csv('./metro.csv',header=None,names=['city','line','station']) 4 5 6 #按城市和线路分组,计算出每条线路的站台数量,再重新设置索引进行排序 7 df_line = df.groupby(['city','line']).count().reset_index() 8 9 #各城市的地铁线路数量 10 #df_city = df_line.groupby(['city']).count().sort_values(by='line',ascending=False).reset_index() 11 df_city = df_line.groupby(['city']).count() 12 df_city['station'] =df_line.groupby('city').sum() 13 df_city = df_city.sort_values(by='line',ascending=False).reset_index()
-
-
- print(df)

- print(df_city)
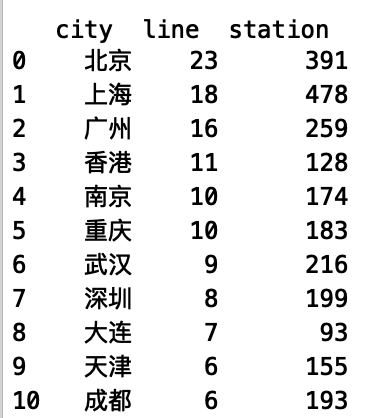
-
-
找出地铁线路最多的前十个城市
def Line_Show(df): ''' 生成城市地铁线路数量分布情况 ''' #中文显示 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False #由图可看出北上广港地铁线路最多 sns.barplot(x='city',y='line',data=df,palette='deep') #地铁站点最多的城市为上海 sns.barplot(x='city',y='station',data=df,palette='rocket') plt.show()
df_city_10 = df_city[:10]
Line_Show(df_city_10)
-
下图可看出北上广拥有的地铁线路排名前三,反映出了其大城市的定位及土地面积之大。
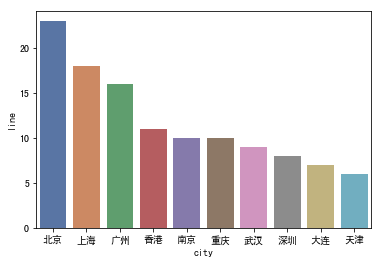
-
北京拥有最多的地铁线路,而上海确实拥有地铁站台最多的城市
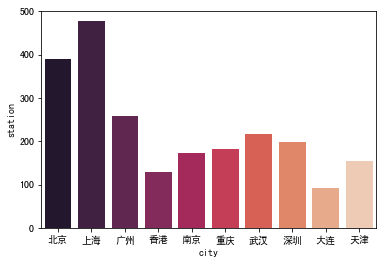
-
地铁名的标配词
- 如此多的地铁名词,那些词汇会是热门呢?
- 对地铁名进行词频分析
1 def Word_Cloud(df): 2 ''' 3 生成地铁名词云 4 ''' 5 text='' 6 for i in df: 7 text += ' '.join(jieba.cut(i,cut_all=False)) 8 text +=' ' 9 #print(text) 10 background_image = plt.imread('./地铁.jpg') 11 wc = WordCloud( 12 background_color='white', #背景颜色 13 mask = background_image, #背景图片 14 font_path = './simhei.ttf', #字体设置 15 max_words=1000, 16 max_font_size=150, 17 min_font_size=15, 18 prefer_horizontal=1, 19 random_state=50, 20 ) 21 wc.generate(text) 22 wc.to_file('./地铁云.png')
1 Word_Cloud(df['station'])
-
对词频进行分词,传入地铁形状的背景图,对相关参数进行设置,生成地铁名词云。
-
火车站,广场,公园,大道是出现频率最高的词汇

看到这个图的时候,你是不是会心一笑,马上能想到相应的地铁站?
住在长春的你,此时的脑袋里必定会浮现出“胜利公园”或“人民广场”;如果你住广州,第一个想到的或许是“公园前”;到了武汉,你可能会想起“中山公园”“洪山广场”……
对一座城市来说,“公园”“广场”是重要的文化地标,以这两类文化地标来命名,一方面指向性非常明确,可以给市民或游客提供清晰的地理定位;另一方面,将这些地标作为地铁名字,也可以帮助推广城市文化。
在“公园”“广场”之外,地铁站名里还有另外一种常见的重要地标建筑,那就是“火车站”。
在跨越城市或省份的交通中,火车站往往担负着重要的任务,也因为这个原因,它成为了各个城市的地标建筑。
但是,火车站一般处于城市的边缘地带,自驾或公交都会增加人们的交通成本,所以,为了方便人们的出行,附近都设有地铁站,地铁名也会与火车站同名。
-
地铁命名的“关键字”
- 一个好的地铁名字,反映的土地之上的人文景观且通俗易懂,让人们能第一时间联想到该区域的特性。
- 对全国各条地铁线路的站名文本做字频分析
1 def Word_Fre(df): 2 ''' 3 统计词频 4 https://www.cnblogs.com/hatemath/p/8268234.html 5 ''' 6 words=[] 7 words_dict ={} 8 exclude_str = ",。!?、()【】<>《》=:+-*—“”…" 9 #添加每一个字到列表中 10 for word in df: 11 for j in word: 12 #将字符串输出为中文 13 words.append(j) 14 #print(words) 15 16 #用字典统计每个数出现的次数 17 for i in words: 18 if i not in exclude_str: #排除符号 19 #对单个字出现次数计数 20 if i.strip() not in words_dict: 21 words_dict[i]=1 22 else: 23 words_dict[i] += 1 24 #print(words_dict) 25 #print(words_dict.items()) #字典.items() 函数以列表返回可遍历的(键, 值) 元组数组 26 27 #x[1]是按字频排序,x[0]则是按字排序 28 word_frequency = sorted(words_dict.items(),key=lambda x:x[1],reverse=True)[:10] 29 #print(word_frequency) 30 Word_Bar(word_frequency) 31 32 def Word_Bar(word_frequency): 33 ''' 34 生成词频图 35 ''' 36 attr = [j[0] for j in word_frequency] 37 fre = [j[1] for j in word_frequency] 38 sns.barplot(x=attr,y=fre)
1 Word_Fre(df['station'])
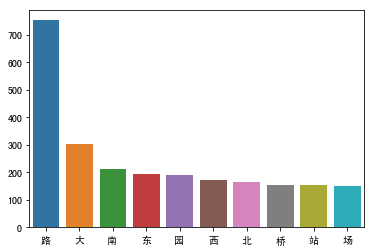
敢问路在何方,一个“路”字,以绝对优势成了出现频率最高的字,可以说,无论走到哪个城市,你都能在地铁图里,找到不同的“路”。
-
深圳地铁出现频率最高的字是?
1 ''' 2 深圳地铁站出现频率最高的字 3 ''' 4 df1 = df[df['city']=='深圳'] 5 Word_Fre(df1['station']) 6 print(df1[df1['station'].str.contains('湾')])
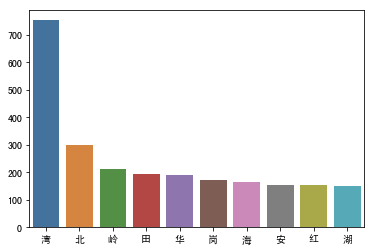
当“湾”字出现时,大脑中立刻浮现了“前海湾”,“红树湾”等多个地名,“湾“字的确能代表深圳这座城市,作为粤港澳大湾区的中心点,深圳介于香港与珠三角其他城市之间,不仅对于珠三角有着不小的影响,而且还和香港有着多年的交流和合作基础,是港澳地区与珠三角之间的桥梁与纽带。
从地理位置上来说,临海城市地铁名中出现湾的频率会否更高呢
-
选取站名出现湾最多的几个城市
1 #选取站名出现湾最多的几个城市 2 df_bay = df[df['station'].str.contains('湾|灣')] 3 #print(df_bay) 4 #香港的'湾'字为繁体字 5 df_bay_num = df_bay.groupby('city').count().sort_values(by='station',ascending=False) 6 print(df_bay_num)
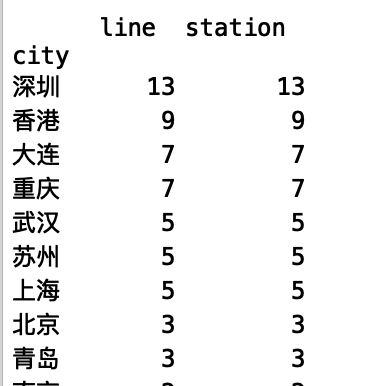
地铁站名出现”湾“字较多次数的城市,无一例外,均为临海,或者是有江河交汇的城市,深圳,大连,重庆等。
在一开始分析时,香港并未出现在名单中,原来是香港地铁站名使用了繁体字。

在一些依山傍水的地方,地铁名必定带有较多的“山山水水”。
像南京这样周边山丘众多的城市,地铁里也跟着冒出很多座“山”。搭个地铁就好像在“翻山越岭”一般:爬完4号线的九华山、聚宝山和灵山,转S7号线翻无想山,再转个S8号线,还可以看到凤凰山。
光是念这些古朴的名字,你都能想象到那秀丽、清幽的画面了。
靠山的城市,地铁名多“山”,而靠近江河湖海的城市,地铁的“含水量”也会噌噌噌地往上涨。
中国的地铁名里,值得挖掘的东西还有很多很多,比如有的地铁名非常风雅,听起来就让人心情愉悦,像北京的金台夕照,西安的桃花潭,南京的莫愁湖,香港的杏花邨......
可以说,一个小小的地铁名就是一座城市风貌的一部分,它反映着不同地方的水土,也承载着各个城市的文化和历史。
北京的庄严气派,上海的现代多元,杭州的诗意风雅,广州的岭南风情,重庆的市井气息……这些都被藏在地铁名字里了。
所以,如果你想快速地了解一座城市,不妨试试从地铁名开始吧,你一定会有很多意想不到的收获!