ExecutorService-执行器服务
零. 线程池的好处
- 降低资源消耗
通过重复利用已创建的线程降低线程创建和销毁造成的消耗。 - 提高响应速度
当任务到达时,任务可以不需要等到线程创建就能立即执行。 - 提高线程的可管理性
进行统一分配、调优和监控。
一. 概述
- ExecutorService本质上是一个线程池,用以减少服务器端的线程的创建和销毁,提高线程资源利用率。
- 线程池在刚创建的时候是空的,每过来一个请求,就会在线程池中创建一个核心线程(Core Thread)(组件)来处理该请求。核心线程的数量在定义线程池的时候需要指定。
- 核心线程在处理完请求后不会销毁。
- 若核心线程未创建满(没有达到指定数量),每一个请求都会触发创建一个新线程,即使此时有空闲线程。
- 若核心线程已满(全部占用),新来的请求进入工作队列(work Queue)(组件)暂时等待。工作队列实际上是一个阻塞式队列。阻塞队列在创建时需要指定容量,且不能再变。
- 若工作队列也被占满,新来的请求会被交给临时线程(Temporary thread)处理(组件)。临时线程也需要在创建线程池的时候定义数量,且是短连接,处理完请求后不会一直存在,会存活一段时间来等待请求,若一直没有新的请求则被销毁。只得注意的是:临时线程不会处理工作队列中的请求。(为了提高核心线程的利用率)
- 若上述三个组件已满负荷作用,则新到的请求就给拒绝执行处理器(Rejected Execution Handle)处理。
【案例】
/**
* corePoolSize - 核心线程数
* maximumPoolSize - 总线程数= 核心线程数+临时线程数
* KeepAliveTime - 临时线程的存活时间
* TimeUnit - 时间单位
* workQueue - 工作队列
* handler - 拒绝执行处理器 如果有拒绝流程则给出
* 例如:日志记录(请求,时间,IP等),
* 跳转页面(努力加载中,失败了)
*/
ExecutorService es = new ThreadPoolExecutor(5, 12, 5000, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(5),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor){
System.out.println(r+"你被拒绝了");
}
});
二. 缓存线程池
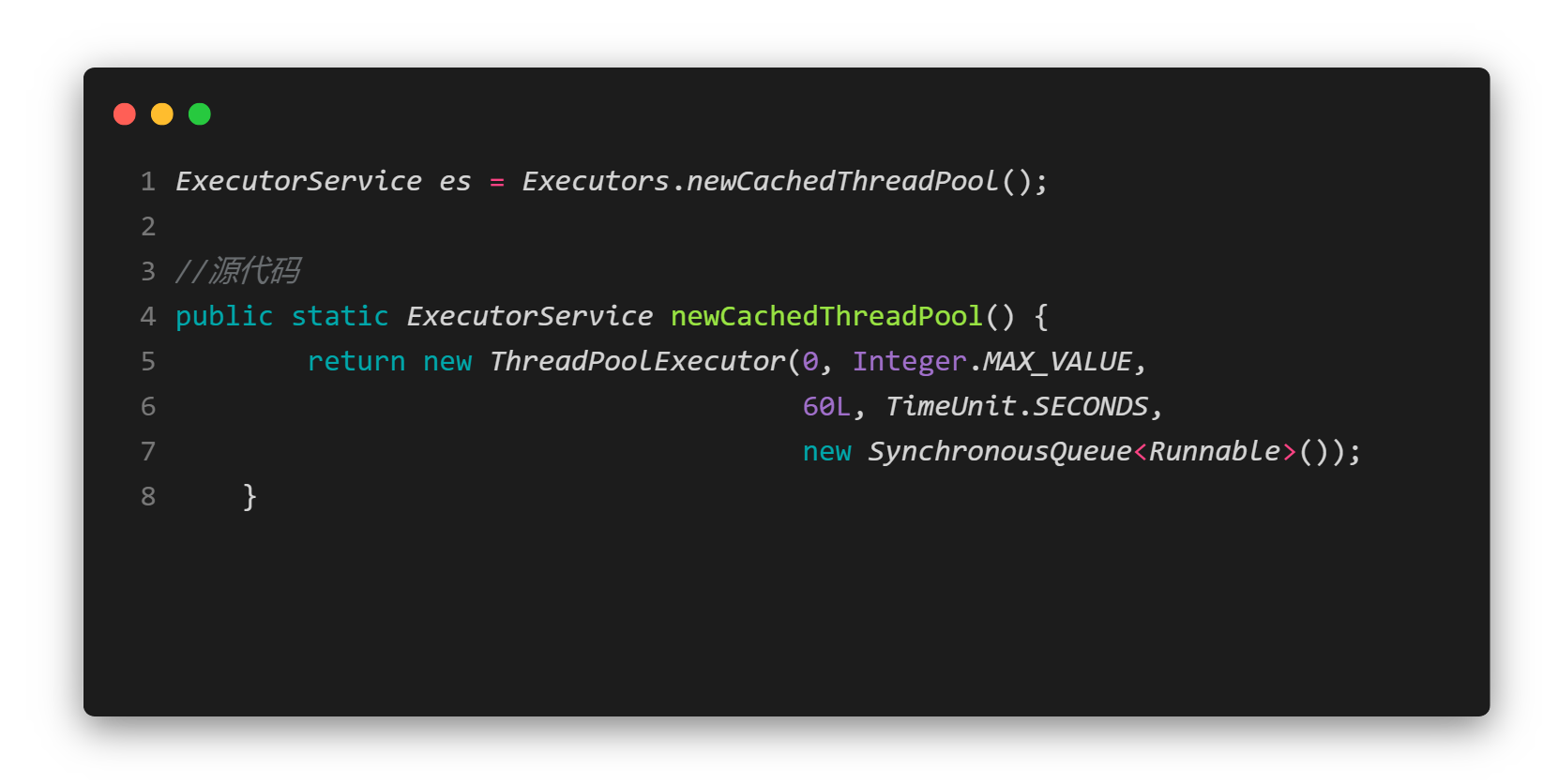
由源代码可以看出缓存线程池有以下特点:
- 核心线程数为0
- 临时线程数为2^31-1(很明显单台服务器能承受的数量远远小于该值,所以认为这个线程池能处理无限多的请求)
- 临时线程用完之后最多存活60s
- 工作队列是一个同步队列SynchronousQueue(只能存一个元素),实际过程中,在测试阶段会利用空请求将这个工作队列填充。此时可以认为这个线程池没有工作队列。
- 如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CachedThreadPool会不断创建新线程 ,可能会耗尽CPU和内存资源
总结:缓存线程池是大池子小队列,适用于高并发的短任务的场景,比如发微信消息这样的即时通讯。(长任务比如下载影片)
三. 固定线程池
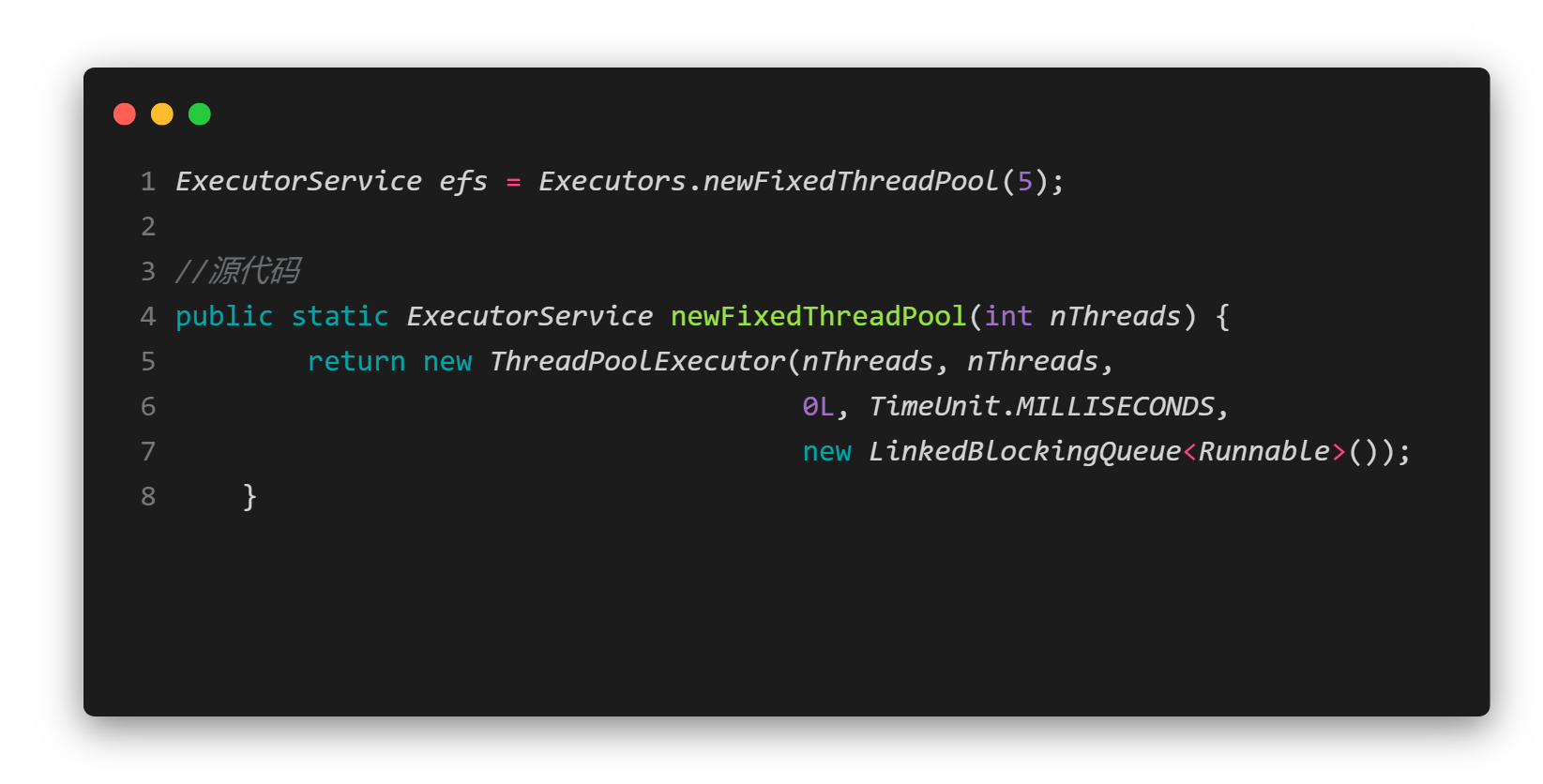
由源代码可以看出缓存线程池有以下特点:
- 没有临时线程
- 工作队列是LinkedBlockingQueue,默认容量2^31-1,一般认为都储存无限多的请求。
- 创建时需要给出核心线程数。
总结:固定线程池是小池子大队列,适用于并发低的长任务场景,例如百度网盘下载,不适用于高并发的短场景。
四. 单例线程池
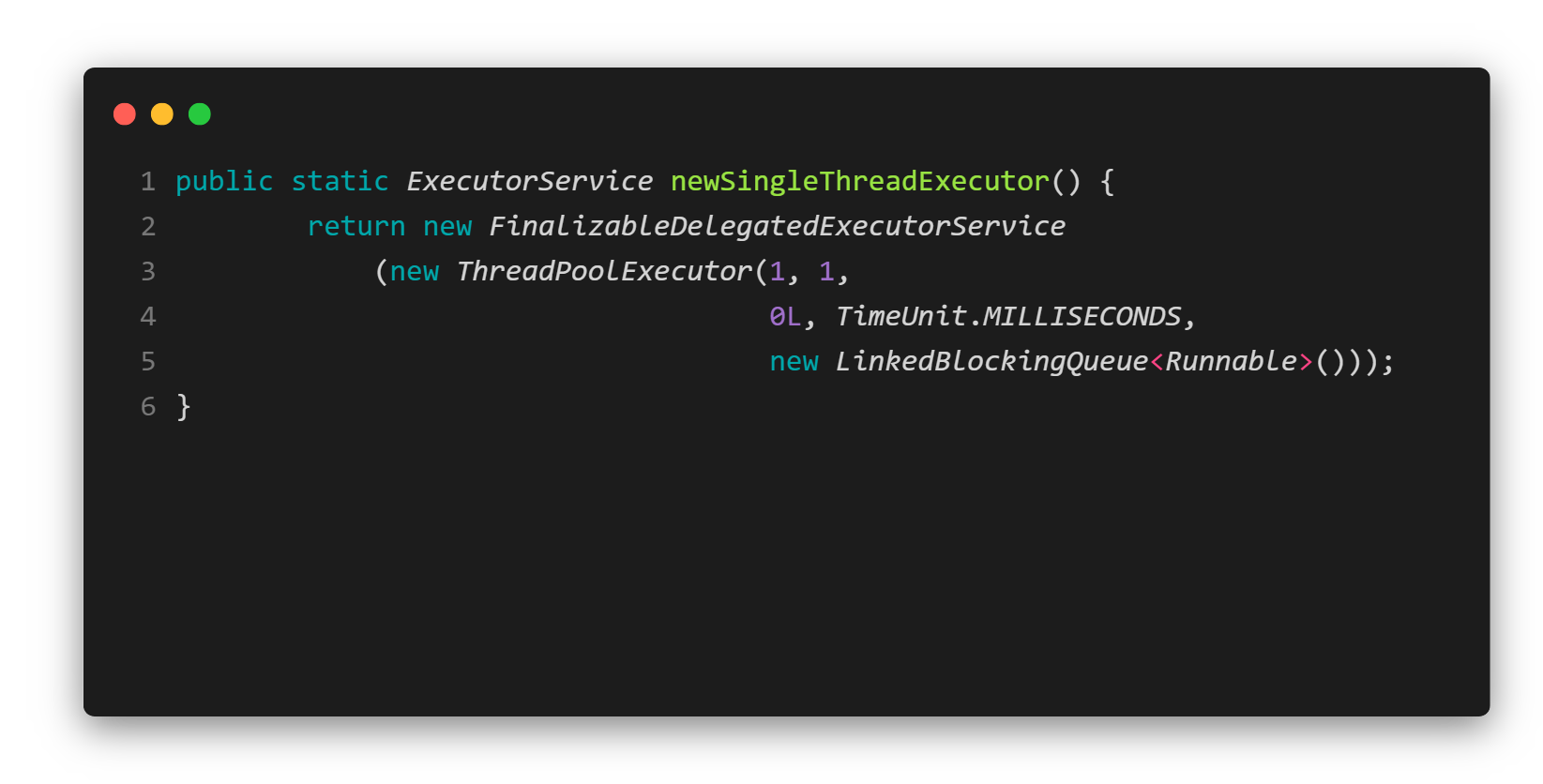
- 使用单个worker线程的Executor
- LinkedBlockingQueue作为WorkerQueue
五. 定时线程池
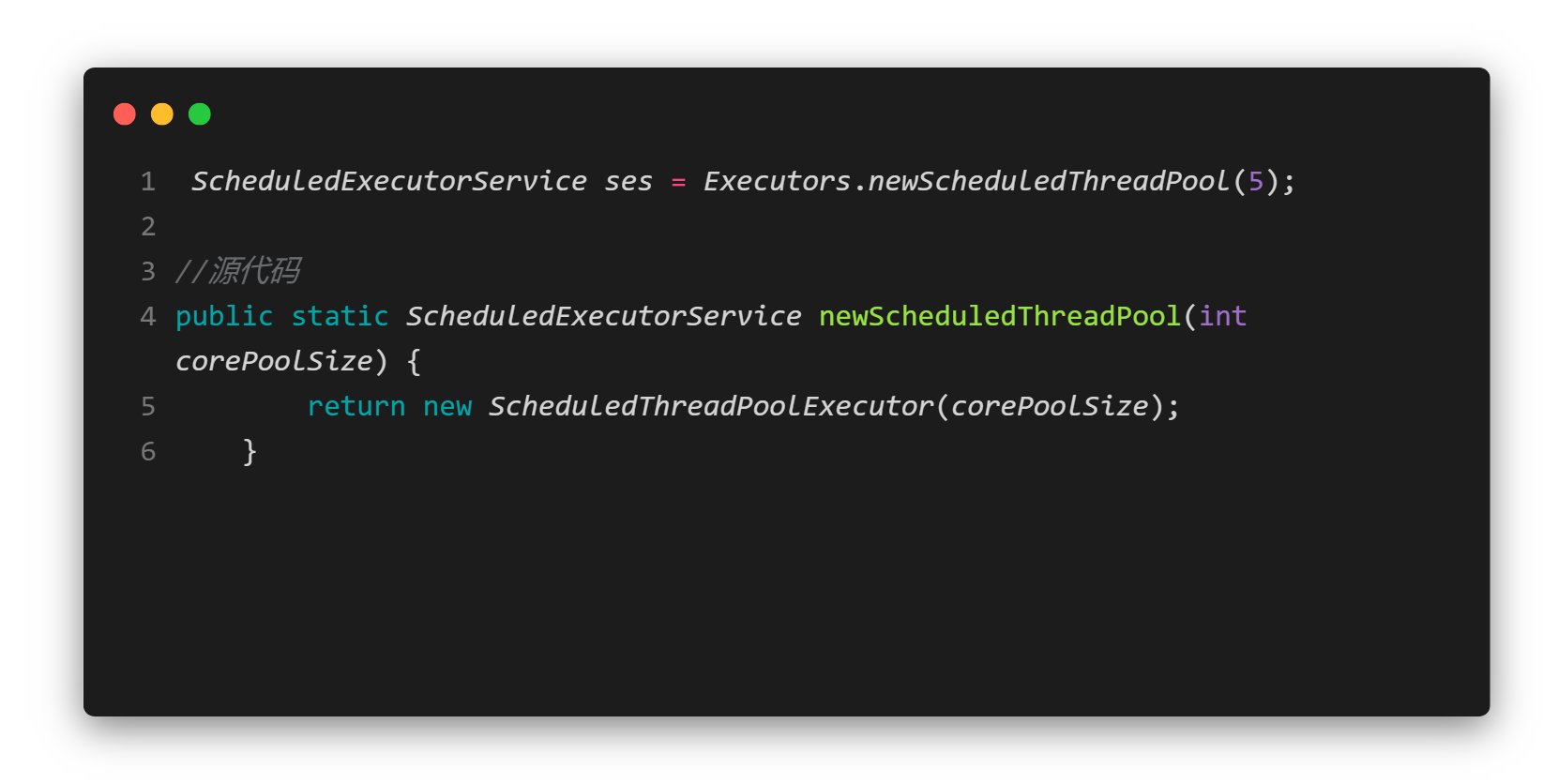
- 在图1中创建了定时线程池,给出核心线程数为5,返回的类型是ScheduledExecutorService-定时调度执行器服务器,这个线程池有“定时”的效果,是许多定时器的底层。
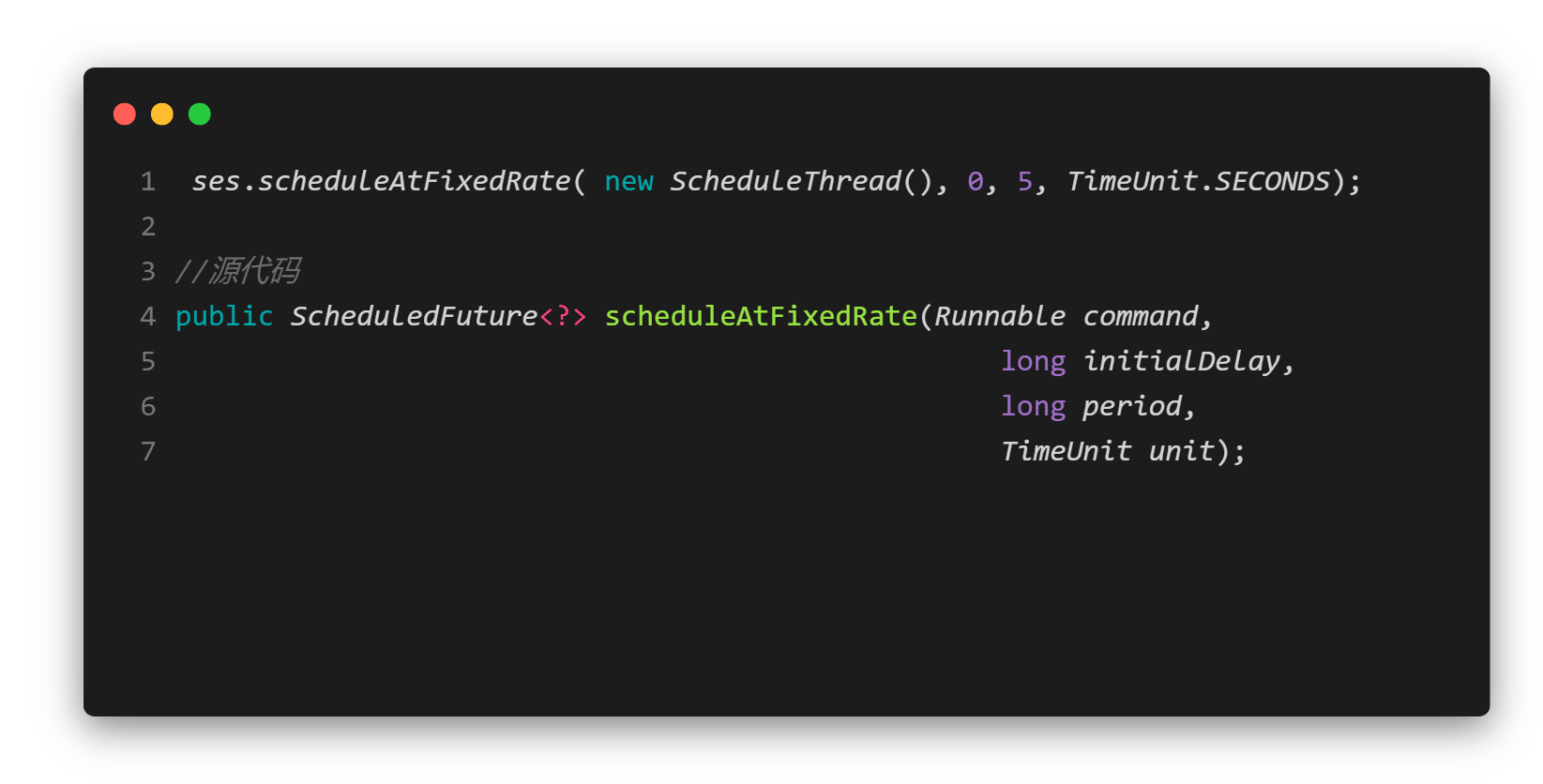
- 图2中执行了一个线程(new ScheduleThread()),给出了延迟时间:0,周期执行时间:5,和时间的单位。在此方法中,是从上一次启动时开始计算下一次的启动时间,间隔时间取执行时间和指定时间的最大值
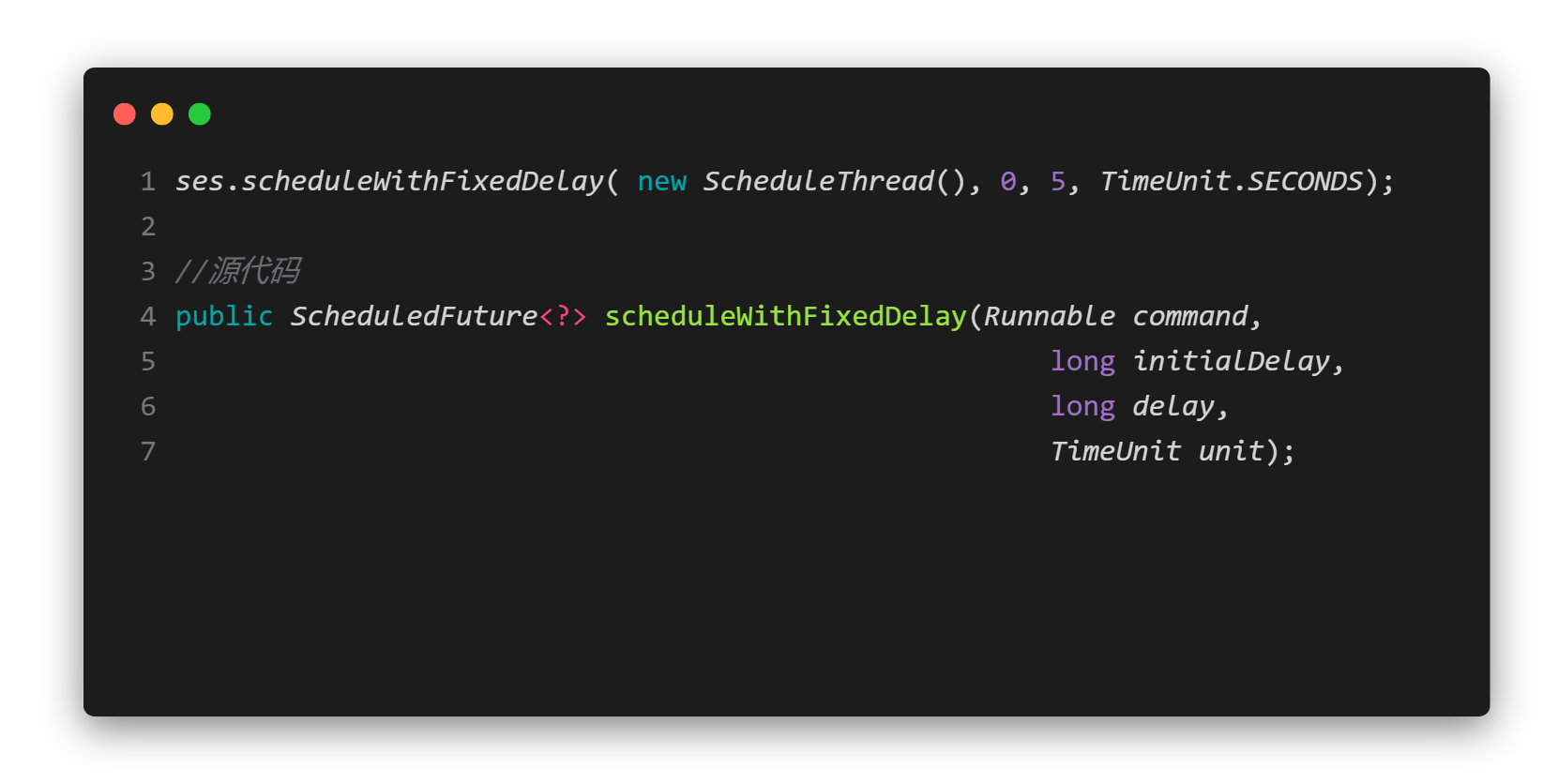
- 图3中执行了一个线程(new ScheduleThread()),给出了延迟时间:0,周期执行时间:5,和时间的单位。与图2的区别是,在该方法中,是从上一次结束,开始计算下一次的启动时间,间隔时间也取执行时间和指定时间的最大值。
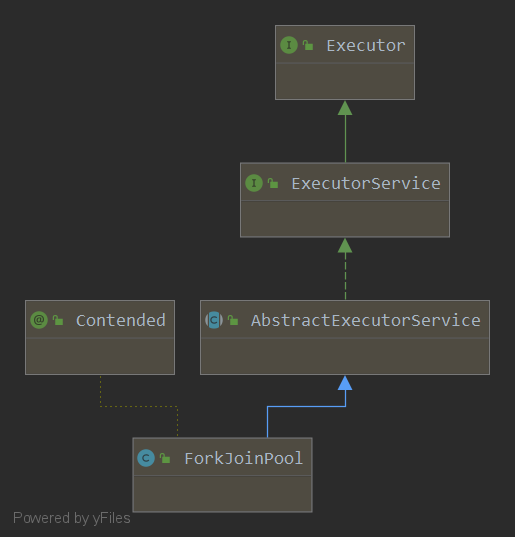
五. 分叉合并池——ForkJoinPool
- 将一个大任务拆分成多个小任务,这个过程称之为分叉。将分叉出来的任务结果进行汇总,这个过程称之为合并。
- 能有效的提高cpu效率。
- 和单纯的循环相比,数据量越小,循环的优势越明显;数据量越大,分叉处理的效率越明显。
- 分叉合并为了提高效率,会尽量均衡的将任务分配到各个核上。
- 在分叉合并中,如果有某个核空闲下来,会随机扫描一个核,从这个核的任务队列尾端偷取一个任务处理执行,这种方式称之为work-stealing(工作窃取)策略,因为该策略涉及底层cpu调度,由c语言处理。
- 处理分叉合并的类,需要继承
RecursiveTask<>,并复写其中的compute()方法。 - 其继承关系如下: