- 索引类型
- innodb存储引擎结构
- sql的IO执行
- 二叉树
- btree结构
mysql索引类型
主键索引
唯一索引
单列索引(普通索引)
组合索引(普通索引)
全文索引
覆盖索引(索引效率最好的索引)
索引可以提升检索速度,但也会减低更新速度,斟酌考虑
alter table article add index idx_name(name);
innodb如何存储我们的数据呢?在新增时间与修改时间的执行有无影响
innodb索引结构:
独享表空间:一个表一个表空间,innodb会有多个段空间组成,分别为:
叶子段:索引b+tree信息
非叶子段:索引b+tree信息
回滚段:总的索引位置记录
索引段:总的索引位置记录
行空间:存放实际表数据,文件头信息等
页空间:16kb,多个行空间
区空间:一个区64个页,不满足就会重新申请一个空间,一个区大概1mb。
段空间:一个段空间是有多个区组成
innodb引擎使用的是b+tree算法来检索数据的。
先了解二叉树以及二分算法,在了解B+tree
数据不是存在非叶子节点的,所有数据是存储在叶子节点。
索引失效和最优索引
不要在列上进行运算,这将导致索引失效而进行全表扫描,例如 where format(time)。。。。
sql的IO执行流程
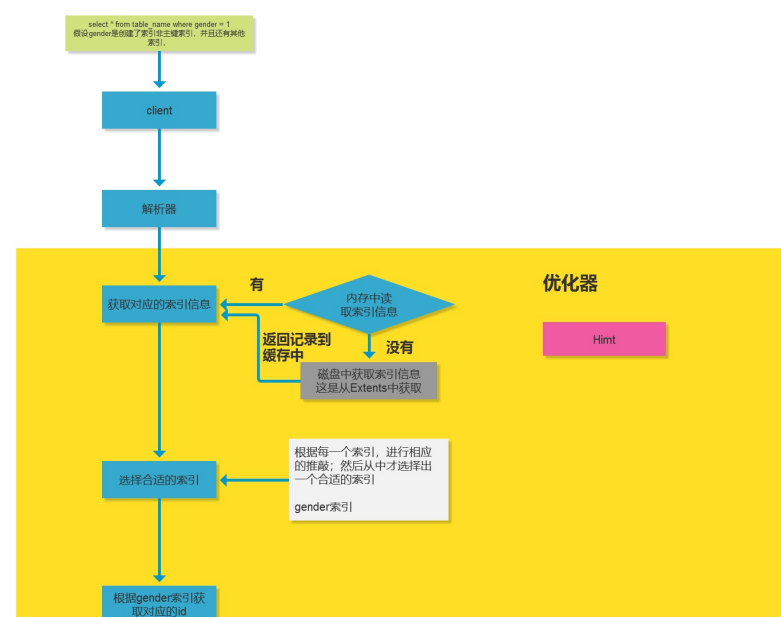
我们来分析一个查询执行流程:
select * from table where g = 1; 假设g是普通索引
进入客户端通过权限验证,解析器解析,获取对应的索引信息。
判断内存中是否有索引信息,有返回,没有的话,磁盘获取索引信息(这就是从extents中获取),然后返回记录到缓存中。
选择合适的索引(根据每个索引,进行响应的推敲,然后从中选择出一个适合的索引,gender索引),
根据gender索引获取对应的id
根据id获取,获取对应的page所在的磁盘中的地址。
获取sql需要的数据。
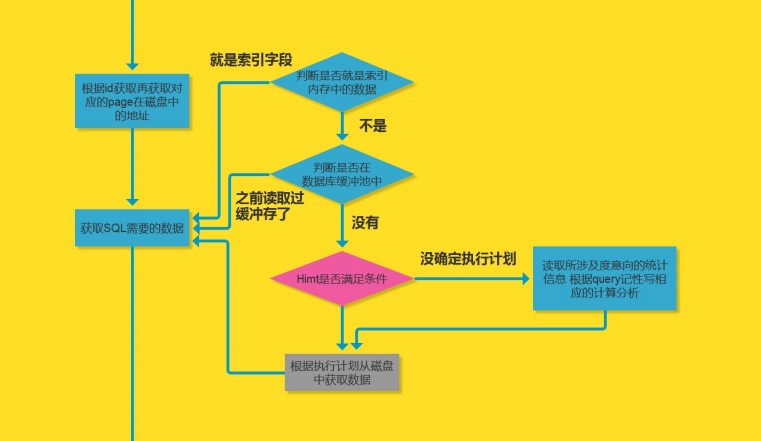
获取到叶子节点的data后,判断是否就是索引内存中的数据,如果是的话直接返回存储的索引字段,如果不是判断是否在数据库缓冲池中,
如果之前读取缓存过,那就返回缓存数据。如果没有Himt优化器,判断是否满足优化器的条件,如果满足执行计划,从磁盘中读取数据。
如果不满足,读取所涉及意向的统计信息,根据query记性写相应的计算分析。然后再执行计划。
最后返回数据
不理解的地方:
读取索引信息(是把整个表的索引信息都索取过来嘛)
数据库缓冲池的理解:命中缓存是一样的嘛