最近一个朋友问我怎么把一个指定区域的内容转成pdf,网上查了一下python里面有个wkhtmltopdf模块可以将str、file、url转成pdf,我们今天不聊怎么转PDF,聊聊怎么获取页面中指定区域的html源码。用到的模块是lxml和requests这两个模块,没有装的小伙伴可以装一下 pip install lxml requests
主要思想是利用xpath获取到指定区域的Element对象,然后再将Element对象传给etree.tostring(),即可得到指定区域的html代码,看一下需求:
1、我们要得到 http://www.w3school.com.cn/ w3c首页中的这个位置的html代码:

看一下页面源码是这样的

2、下面开始编码:
1 from lxml import etree 2 import requests 3 4 res=requests.get('http://www.w3school.com.cn/') 5 tree=etree.HTML(res.content) 6 div=tree.xpath('//div[@id="d1"]')[0] 7 div_str=etree.tostring(div,encoding='utf-8') 8 print div_str
3、结果如下:
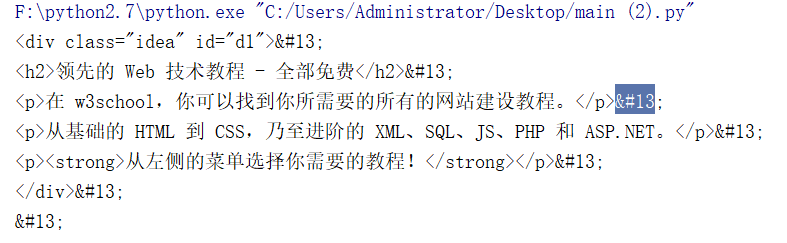
4、成功获取到了指定区域的html代码。