一、使用背景
目前项目中,采用的是微服务框架,对于日志,采用的是logback的配置,每个微服务的日志,都是通过File的方式存储在部署的机器上,但是由于日志比较分散,想要检查各个微服务是否有报错信息,需要挨个服务去排查,比较麻烦。所以希望通过对日志进行聚合,然后通过监控,能够快速的找到各个微服务的报错信息,快速的排查。
二、ELK分析
对于ELK,主要是分为Elastic Search、Logstash和Kibana三部分:其中Logstash作为日志的汇聚,可以通过input、filter、output三部分,把日志收集、过滤、输出到Elastic Search中(也可以输出到文件或其他载体);Elastic Search作为开源的分布式引擎,提供了搜集、分析、存储数据的功能,采用的是restful接口的风格;Kibana则是作为Elastic Search分析数据的页面展示,可以进行对日志的分析、汇总、监控和搜索日志用。
本次使用ELK主要则是作为日志分析场景。
三、ELK部署
1、Elastic Search安装
本次部署的目录为【/data/deploy/elk】下,首先需要下载,下载命令为:
# cd /data/deploy/elk # wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.3.tar.gz
解压到当前目录:
# tar -zxvf elasticsearch-6.4.3.tar.gz
相关配置:
# cd elasticsearch-6.4.3/config # vim elasticsearch.yml -- 增加如下内容: network.host: 0.0.0.0 http.port: 9200 http.cors.enabled: true http.cors.allow-origin: "*"
Elastic Search启动:由于ES的启动不能用root账号直接启动,需要新创建用户,然后切换新用户去启动,执行命令如下:
-- 创建新用户及授权 # groupadd elsearch # useradd elsearch -g elsearch -p elasticsearch # cd /data/deploy/elk/ # chown -R elsearch:elsearch elasticsearch-6.4.3 -- 切换用户,启动 # su elsearch # cd elasticsearch-6.4.3/bin # sh elasticsearch &
启动过程中,会出现一些报错信息,如:
1、max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
2、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决问题(1):将当前用户的软硬限制调大。
# vim /etc/security/limits.conf -- 在后面增加一下配置后,保存退出 es soft nofile 65535 es hard nofile 65537 -- 不需要重启,重新登录即生效 -- 查看修改命名是否生效 # ulimit -n 65535 # ulimit -n -- 结果65535 # ulimit -H -n 65537 # ulimit -H -n -- 结果65537
解决问题(2):调大elasticsearch用户拥有的内存权限
-- 切换到root用户 # sysctl -w vm.max_map_count=262144 -- 查看修改结果 # sysctl -a|grep vm.max_map_count -- 结果显示:vm.max_map_count = 262144 -- 永久生效设置 # vim /etc/sysctl.conf -- 在文件最后增加以下内容,保存后退出: vm.max_map_count=262144
解决以上问题后,再次启动:
# su - elsearch # cd /data/deploy/elk/elasticsearch-6.4.3/bin/ # sh elasticsearch &
启动成功后,访问:http://ip:9200,可以有json格式的返回信息,判断安装成功。
2、Kibana的安装
下载安装包:
-- 切换到root用户 # su -- 下载 # cd /data/deploy/elk/ # wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.2-linux-x86_64.tar.gz
解压配置:
# tar -zxvf kibana-6.4.2-linux-x86_64.tar.gz # cd kibana-6.4.2-linux-x86_64/config/ # vim kibana.yml -- 增加如下配置: server.port: 5601 server.host: "0.0.0.0" elasticsearch.url: "http://localhost:9200" kibana.index: ".kibana"
启动Kibana:
# cd /data/deploy/elk/kibana-6.4.2-linux-x86_64/bin # sh kibana &
启动成功后,访问http://ip:5601,查看是否启动成功。
3、Logstash安装
下载安装包:
-- 切换到root账号 # su # cd /data/deploy/elk # wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.2.tar.gz
解压配置:
# tar -zxvf logstash-6.4.2.tar.gz
# cd logstash-6.4.2/bin
-- 新增编辑配置文件
# vim logstash.conf
-- 增加以下内容:
input {
tcp {
port => 5044
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}
启动Logstash:
# cd /data/deploy/elk/logstash-6.4.2/bin # nohup sh logstash -f logstash.conf &
查看日志,无报错信息,默认启动成功。
四、微服务配置
在微服务中,需要两步操作:
1、pom.xml文件增加依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.1</version>
</dependency>
2、修改logback.xml配置文件
-- 新增appender
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.11.199:5044</destination>
<queueSize>1048576</queueSize>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity":"%level",
"service": "%contextName",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message->%ex{full}"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
-- <root>节点中,增加:
<appender-ref ref="LOGSTASH" />
五、Kibana的使用
通过以上的配置,基本上ELK和微服务之间,已经配置完成,接下来需要通过在Kibana中创建索引等进行日志的搜索和查看。
1、创建索引
可以新建一个全局的索引,【Index pattern】设置为【*】,点击下一步至完成为止。
2、日志搜索

如截图所示,可以通过Discover和新建的索引,对日志进行详细的查看,并且可以选择具体的字段进行查看。在右上角,可以通过选择不同的时间段,对日志进行查看和搜索。
3、创建查询
如2中截图所示,可以通过添加filter,对日志进行过滤查询。然后点击Save后,可以创建新的查询。
4、创建Visualize和Dashboard
创建完查询后,可以在Visualize中,创建一个新的图示,通过查询进行创建。创建Dashboard,依赖Visualize图示,进行展示。
即依赖关系:Dashboard -》 Visualize -》 Search
在本项目中,Search主要是通过增加了两个Filter:①service:“ff-watersource” ②severity:“ERROR”,查询的是微服务为ff-watersource的error级别的日志。然后根据本Search,依次创建Visualize和Dashboard,最终在Dashboard中,可以监控日志信息的页面为:
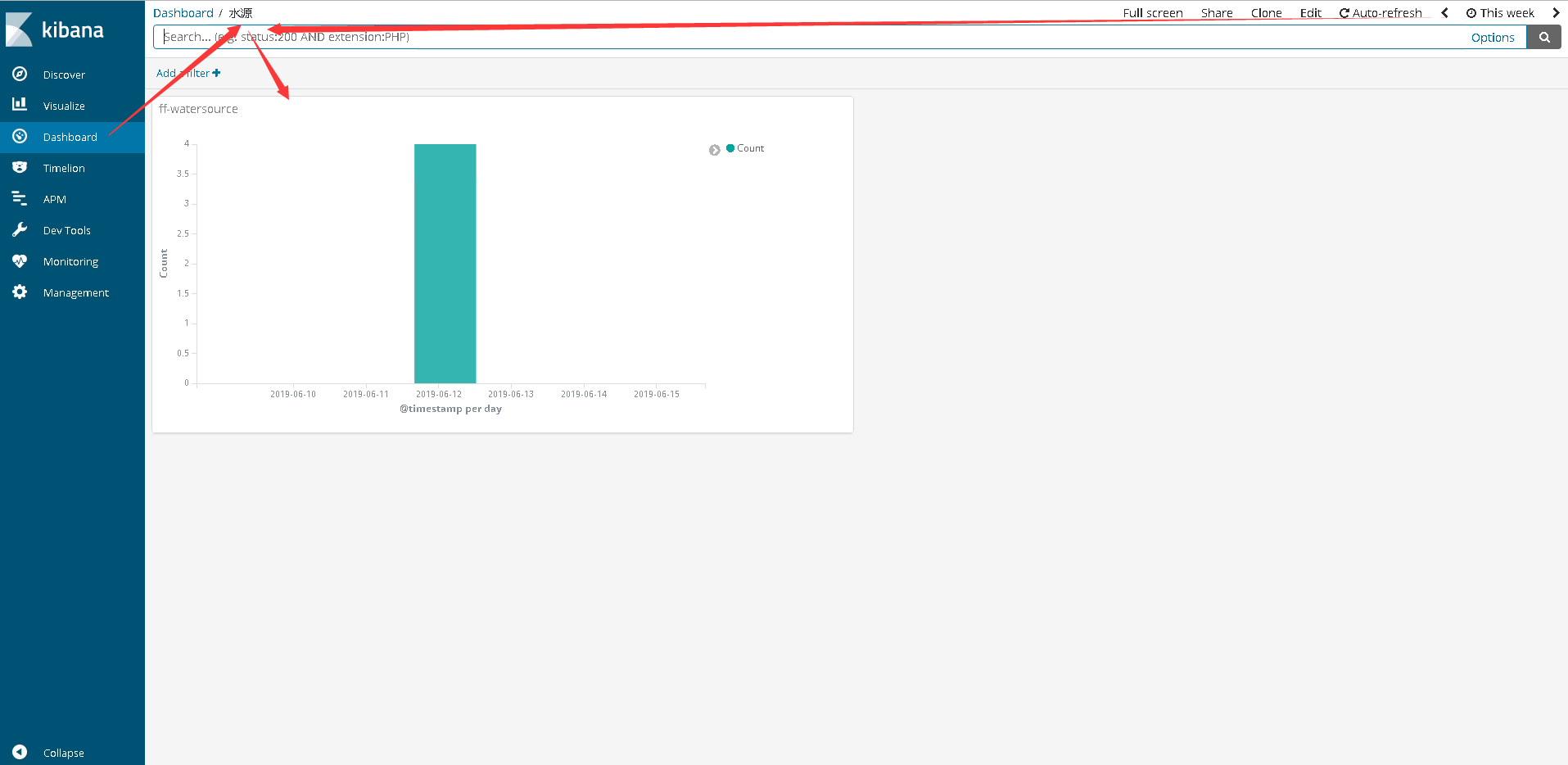
以上,日志聚合分析的实现,就算完成了。