Java生鲜电商平台-CAP理论在大型互联网系统中的应用
说明:本文介绍在大型Java生鲜电商中,CAP理论在大型互联网系统中的应用
在计算机领域,如果是初入行就算了,如果是多年的老码农还不懂CAP 定理,那就真的说不过去了。CAP 可是每一名技术架构师都必须掌握的基础原则啊。
现在只要是稍微大一点的互联网项目都是采用分布式结构了,一个系统可能有多个节点组成,每个节点都可能需要维护一份数据。那么如何维护各个节点之间的状态,如何保
障各个节点之间数据的同步问题就是大家急需关注的事情了。
CAP 定理是分布式系统中最基础的原则。所以理解和掌握了CAP,对系统架构的设计至关重要。
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家--埃里克·布鲁尔(Eric Brewer),在2000 年的ACM PODC 上提出的一个猜想。2002 年,麻省理工学院的赛斯·吉尔伯特(Seth Gilbert)和南希·林奇(Nancy Lynch)发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。CAP 定理,指的是在一个分布式系统(指互相连接并共享数据节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲,如图4-6 所示。
图4-6 CAP 理论
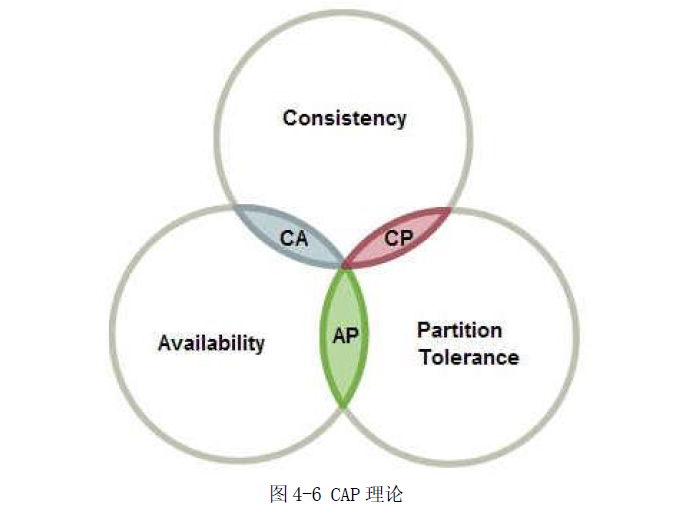
CAP 分别表示的含义:
一致性(Consistency), 对某个指定的客户端来说,读操作保证能够返回最新的写操作结
果。一致性又可分为:弱一致性、强一致性、最终一致性,感兴趣可以查看相关文档。
可用性(Availability),非故障的节点在合理的时间内返回合理的响应(不是错误和超时
的响应)。可用性模式可分成:工作到备用切换(Active-passive)、双工作切换(Active-active)
分区容错性(Partition Tolerance),当出现网络分区后,系统能够继续履行职责。
CAP 定理在互联网大型分布式系统中的应用
虽然CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考的话,我们会发
现必须选择P(分区容错)要素,因为网络本身无法做到100%可靠,有可能出故障,所以分区是
一个必然的选项。
如果我们选择了CA 而放弃了P,那么当发生分区现象时,为了保证C,系统需要禁止写入,
当有写入请求时,系统返回error,这又和A 冲突了,因为A 要求返回no error 和no timeout。
因此,分布式系统理论上不可能选择CA 架构,只能选择CP 或者AP 架构。
图4-7 CP - Consistency/Partition Tolerance
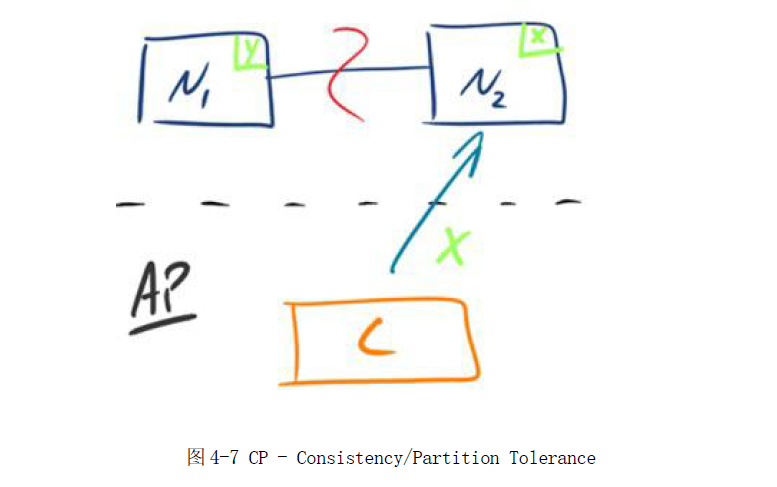
如图4-7 所示,为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到y,但由于N1 和N2 之间的复制通道中断,数据y 无法同步到N2,N2 节点上的数据还是这时客户端C 访问N2 时,N2 需要返回Error,提示客户端面C:“系统现在发生错误”,
这种处理方式违背了可用性(Availability)的要求,因此CAP 三者只能满足CP。
图4-8 AP - Availability/Partition Tolerance
如图4-8 所示,为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到y,但
由于N1 和N2 之间的复制通道中断,数据y 无法同步到N2,N2 节点上的数据还是x。
这时客户C 访问N2 时,N2 将当前自己拥有的数据x 返回给客户端C 了,而实际上当前最
新的数据已经是y 了,这就不满足一致性(Consistency)的要求了,因此CAP 三者只能满足
AP。
注意:这里N2 节点返回的x,虽然不是一个“正确”的结果,但是一个“合理”的结果,
因为x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
CAP 定理的应用,有哪些注意事项?
了解了CAP 定理后,对于开发者而言,当我们构建服务的时候,就需要根据业务特性进行
权衡考虑,哪些点是当前系统可以取舍的,哪些是应该重点保障的。
CAP 关注的粒度是数据,而不是整个系统。
C 与A 之间的取舍可以在同一系统内以非常细小的粒度反复发生,而每一次的决策可能因
为具体的操作,乃至因为牵涉到特定的数据或用户有所不同。
以一个商家管理系统为例,商家管理系统包含商家账号数据(商家ID、密码)、商家信息
数据(行业类别、公司规模、营收规模等)。通常情况下,商家账号数据会选择CP,而商家信
息数据会选择AP,如果限定整个系统为CP,则不符合用户信息的应用场景;如果限定整个系统
为AP,则又不符合商家账号数据的应用场景。
所以在CAP 理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分
类,每类数据选择不同的策略(CP 或AP),而不是直接限定整个系统所有数据都是同一策略。
CAP 是忽略网络延迟的。
这是一个非常隐含的假设,布鲁尔在定义一致性时,并没有将延迟考虑进去。即当事务提
交时,数据能够瞬间复制到所有节点。但实际情况下,尤其是互联网架构之下,从节点A 复制
数据到节点B,总是需要花费一定时间的。如果在相同机房可能是几毫秒,如果跨机房,可能
是几十毫秒。这也就是说,CAP 理论中的C 在实践中是不可能完美实现的,在数据复制的过程
中,节点A 和节点B 的数据并不一致。
正常运行情况下,不存在CP 和AP 的选择,可以同时满足CA。
CAP 理论告诉我们分布式系统只能选择CP 或者AP,但其实这里的前提是系统发生了“分区”
现象。如果系统没有发生分区现象,也就是说P 不存在的时候(节点的网络连接一切正常),我
们就没有必要放弃C 或者A,应该C 和A 都可以保证,这就要求架构设计的时候即要考虑分区
发生时选择CP 还是AP,也要考虑分区没有发生时如何保证CA。
这里我们还以用户管理系统为例,即使是实现CA,不同的数据实现方式也可能不一样:用
户账号数据可以采用“消息队列”的方式来实现CA,因为消息队列可以比较好地控制实时性,
但实现起来就复杂一些;而用户信息数据可以采用“数据库同步”的方式来实现CA,因为数据
库的方式虽然在某些场景下可能延迟较高,但使用起来简单。
放弃并不等于什么都不做,需要为分区恢复后做准备。
CAP 理论告诉我们三者只能取两个,需要“牺牲”(sacrificed)另外一个,这里的“牺
牲”是有一定误导作用的,因为“牺牲”让很多人理解成什么也不做。实际上,CAP 理论的“牺
牲”只是说在分区过程中我们无法保证C 或者A,但并不意味着什么都不做。分区期间放弃C
或者A,并不意味着永远放弃C 和A,我们可以在分区期间进行一些操作,从而让分区故障解决
后,系统能够重新达到CA 的状态。
最典型的就是在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,
使得重新达到CA 状态。
CAP 是非常重要的架构理论,有志于成为架构师的朋友,对于CAP、ACID、BASE 等定理,
一定要有比较深的理解和认识,把基础打扎实。
结语
复盘与总结.
总结:
做Java生鲜电商平台的互联网应用,无论是生鲜小程序还是APP,系统中台的CAP系统设计的思路是非常重要的,本文只是起一个抛砖引玉的作用,
希望用生鲜小程序的系统CAP的概念架构思路实战经验告诉大家一些实际的项目经验,希望对大家有用.
QQ:137071249
共同学习QQ群:793305035