GC日志分析
通过阅读GC日志,我们可以了解Java虛拟机内存分配与回收策略。
-
内存分配与垃圾回收的参数列表
-XX: +PrintGC 输出Gc日志。类似:-verbose:gc;
-XX : +PrintGCDetails 输出GC的详细日志
-XX: +PrintGCTimeStamps输出GC的时间戳(以基准时间的形式)
-XX: +PrintGCDatestamps输出GC的时间戳(以日期的形式,如2020-05-04T21 :53:59.234+0800 )
-XX: +PrintHeapAtGC在进行GC的前后打印出堆的信息,
-Xloggc:../logs/gc.log 日志文件的输出路径 -
日志信息
-
Allocation Failure 表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
-
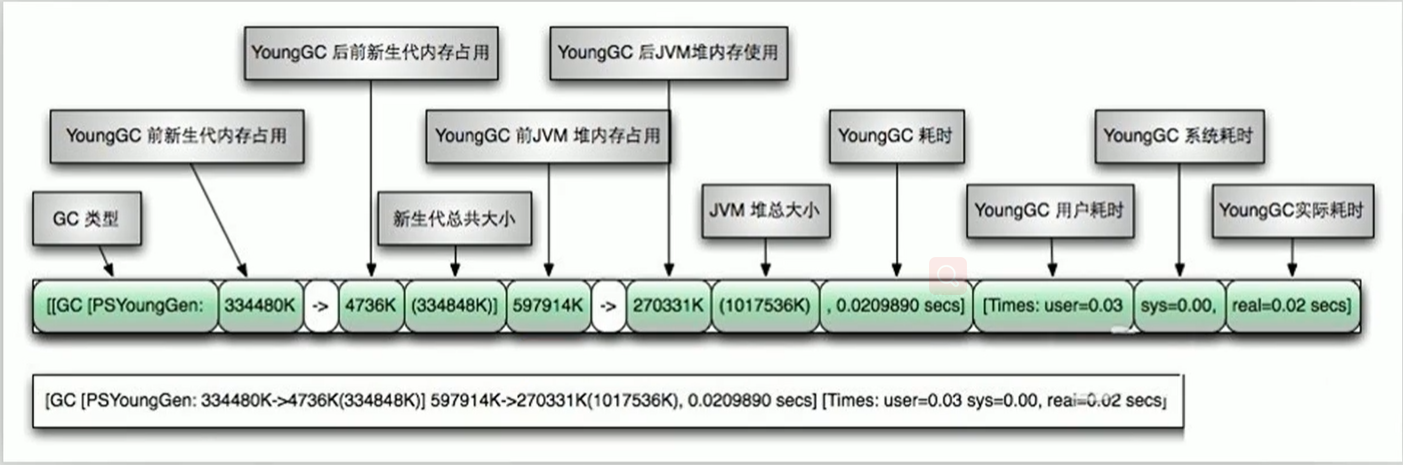
[PSYoungGen: 5986K->696K (8704K) ] 5986K-> 704K (921 6K)
中括号内: Gc回收前年轻代大小,回收后大小,( 年轻代总大小)
括号外: GC回收前年轻代和老年代大小,回收后大小,( 年轻代和老年代总大小) -
user代表用户态回收耗时,sys内核态回收耗时,rea实际耗时。由于多核的原因,时间总和可能会超过real时间
-
垃圾回收器的新发展
Open JDK12的Shenandoah GC
- 现在G1回收器已成为默认回收器好几年了。
- 我们还看到了引入了两个新的收集器:
ZGC( JDK11出现)和Shenandoah(openJDK12)。
➢主打特点:低停顿时间 - Shenandoah,无疑是众多GC中最孤独的一个。是第一款不由Oracle公司团队领导开发的HotSpot垃圾收集器。不可避免的受到官方的排挤。比如号称OpenJDK和OracleJDK没有区别的Oracle公司仍拒绝在OracleJDK12中支持Shenandoah。
- Shenandoah垃圾回收器最初由RedHat进行的一项垃圾收集器研究项目PauselessGC的实现,旨在针对JVM上的内存回收实现低停顿的需求。在2014年贡献给OpenJDK。
- Red Hat研发Shenandoah团队对外宣称,Shenandoah垃圾 回收器的暂停时间与堆大小无关,这意味着无论将堆设置为200 MB还是200GB,99 .9%的目标都可以把垃圾收集的停顿时间限制在十毫秒以内。不过实际使用性能将取决于实际工作堆的大小和工作负载。

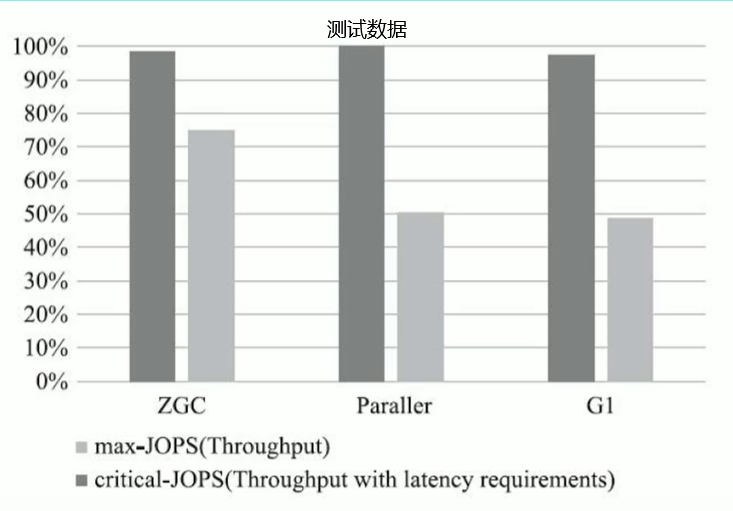
- 这是RedHat在2016年发表的论文数据,测试内容是使用ES对200GB的维基百科数据进行索引。从结果看:
➢停顿时间比其他几款收集器确实有了质的飞跃,但也未实现最大停顿时间控制在十毫秒以内的目标。
➢而吞吐量方面出现了明显的下降,总运行时间是所有测试收集器里最长的。 - 总结:
Shenandoah GC的弱项:高运行负担下的吞吐量下降。
Shenandoah GC的强项:低延迟时间。
革命性的ZGC(JDK14)
ZGC与Shenandoah目标高度相似,在尽可能对吞吐量影响不大的前提下,实现在任意堆内存大小下都可以把垃圾收集的停顿时间限制在十毫秒以内的低延迟。
《深入理解Java虚拟机》一书中这样定义ZGC: ZGC收集器是一款基于Region内存布局的,(暂时) 不设分代的,使用了读屏障、染色指针和内存多重映射等技术来实现可并发的标记-压缩算法的,以低延迟为首要目标的一款垃圾收集器。
ZGC的工作过程可以分为4个阶段: 并发标记-并发预备重分配-并发重分配-并发重映射等。
ZGC几乎在所有地方并发执行的,除了初始标记的是STW的。所以停顿时间几乎就耗费在初始标记上,这部分的实际时间是非常少的。
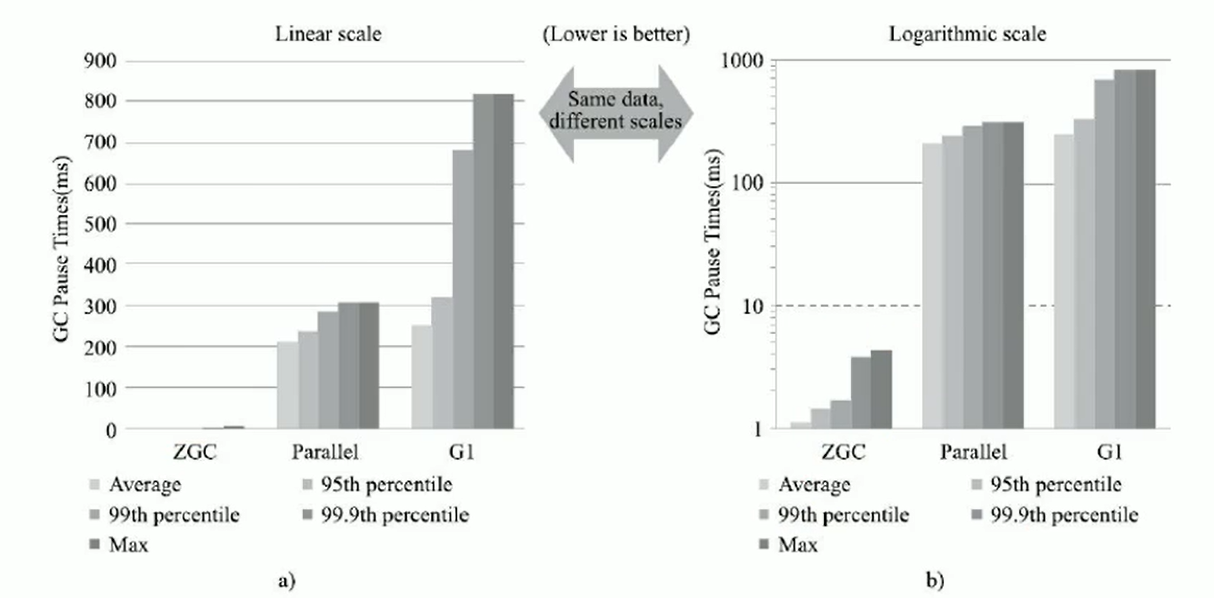
在ZGC的强项停顿时间测试上,它毫不留情的将Parallel、G1拉开了两个数量级的差距。无论平均停顿、95%停顿、99%停顿、99. 9%停顿,还是最大停顿时间,ZGC都能毫不费劲控制在10毫秒以内。
虽然ZGC还在试验状态,没有完成所有特性,但此时性能已经相当亮眼,用“令人震惊、革命性”来形容,不为过。
未来将在服务端、大内存、低延迟应用的首选垃圾收集器。
- JEP 364: ZGC应用在macOS上
- JEP 365: ZGC应用在windows上
- JDK14之前,ZGC仅Linux才支持。
- 尽管许多使用ZGC的用户都使用类Linux的环境,但在Windows 和macOs上,人们也需要ZGC进行开发部署和测试。许多桌面应用也可以从ZGC中受益。因此,ZGC特性被移植到了Windows和macos上。
- 现在mac或Windows上也能使用ZGC了,示例如下:
- XX: +UnlockExperimentalVMOptions -XX:+UseZGC
其它垃圾回收器:AliGC
AliGC是阿里巴巴JVM团队基于G1算法,面向大堆 (LargeHeap)应用场景。
指定场景下的对比:

上一篇:垃圾回收器