|
问题导读
1.哪些情况会遇到io受限制?
2.哪些情况会遇到cpu受限制?
3.如何选择机器配置类型?
4.为数据节点/任务追踪器提供的推荐哪些规格?
随着Apache Hadoop的起步,云客户的增多面临的首要问题就是如何为他们新的的Hadoop集群选择合适的硬件。
尽管Hadoop被设计为运行在行业标准的硬件上,提出一个理想的集群配置不想提供硬件规格列表那么简单。 选择硬件,为给定的负载在性能和经济性提供最佳平衡是需要测试和验证其有效性。(比如,IO密集型工作负载的用户将会为每个核心主轴投资更多)。
在这个博客帖子中,你将会学到一些工作负载评估的原则和它在硬件选择中起着至关重要的作用。在这个过程中,你也将学到Hadoop管理员应该考虑到各种因素。
结合存储和计算
过去的十年,IT组织已经标准化了刀片服务器和存储区域网(SAN)来满足联网和处理密集型的工作负载。尽管这个模型对于一些方面的标准程序是有相当意义 的,比如网站服务器,程序服务器,小型结构化数据库,数据移动等,但随着数据数量和用户数的增长,对于基础设施的要求也已经改变。网站服务器现在有了缓存 层;数据库需要本地硬盘支持大规模地并行;数据迁移量也超过了本地可处理的数量。
大部分的团队还没有弄清楚实际工作负载需求就开始搭建他们的Hadoop集群。
硬件提供商已经生产了创新性的产品系统来应对这些需求,包括存储刀片服务器,串行SCSI交换机,外部SATA磁盘阵列和大容量的机架单元。然 而,Hadoop是基于新的实现方法,来存储和处理复杂数据,并伴随着数据迁移的减少。 相对于依赖SAN来满足大容量存储和可靠性,Hadoop在软件层次处理大数据和可靠性。
Hadoop在一簇平衡的节点间分派数据并使用同步复制来保证数据可用性和容错性。因为数据被分发到有计算能力的节点,数据的处理可以被直接发送到存储有数据的节点。由于Hadoop集群中的每一台节点都存储并处理数据,这些节点都需要配置来满足数据存储和运算的要求。
工作负载很重要吗? 在几乎所有情形下,MapReduce要么会在从硬盘或者网络读取数据时遇到瓶颈(称为IO受限的应用),要么在处理数据时遇到瓶颈(CPU受限)。排序是一个IO受限的例子,它需要很少的CPU处理(仅仅是简单的比较操作),但是需要大量的从硬盘读写数据。模式分类是一个CPU受限的例子,它对数据进行复杂的处理,用来判定本体。
下面是更多IO受限的工作负载的例子:
下面是更多CPU受限的工作负载的例子:
Cloudera的客户需要完全理解他们的工作负载,这样才能选择最优的Hadoop硬件,而这好像是一个鸡生蛋蛋生鸡的问题。大多数工作组在没有彻底剖 析他们的工作负载时,就已经搭建好了Hadoop集群,通常Hadoop运行的工作负载随着他们的精通程度的提高而完全不同。而且,某些工作负载可能会被 一些未预料的原因受限。例如,某些理论上是IO受限的工作负载却最终成为了CPU受限,这是可能是因为用户选择了不同的压缩算法,或者算法的不同实现改变 了MapReduce任务的约束方式。基于这些原因,当工作组还不熟悉要运行任务的类型时,深入剖析它才是构建平衡的Hadoop集群之前需要做的最合理 的工作。
接下来需要在集群上运行MapReduce基准测试任务,分析它们是如何受限的。完成这个目标最直接的方法是在运行中的工作负载中的适当位置添加监视器来 检测瓶颈。我们推荐在Hadoop集群上安装Cloudera Manager,它可以提供CPU,硬盘和网络负载的实时统计信息。(Cloudera Manager是Cloudera 标准版和企业版的一个组件,其中企业版还支持滚动升级)Cloudera Manager安装之后,Hadoop管理员就可以运行MapReduce任务并且查看Cloudera Manager的仪表盘,用来监测每台机器的工作情况。
第一步是弄清楚你的作业组已经拥有了哪些硬件
在为你的工作负载构建合适的集群之外,我们建议客户和它们的硬件提供商合作确定电力和冷却方面的预算。由于Hadoop会运行在数十台,数百台到数千台节 点上。通过使用高性能功耗比的硬件,作业组可以节省一大笔资金。硬件提供商通常都会提供监测功耗和冷却方面的工具和建议。
为你的CDH(Cloudera distribution for Hadoop) Cluster选择硬件 选择机器配置类型的第一步就是理解你的运维团队已经在管理的硬件类型。在购买新的硬件设备时,运维团队经常根据一定的观点或者强制需求来选择,并且他们倾 向于工作在自己业已熟悉的平台类型上。Hadoop不是唯一的从规模效率上获益的系统。再一次强调,作为更通用的建议,如果集群是新建立的或者你并不能准 确的预估你的极限工作负载,我们建议你选择均衡的硬件类型。
Hadoop集群有四种基本任务角色:名称节点(包括备用名称节点),工作追踪节点,任务执行节点,和数据节点。节点是执行某一特定功能的工作站。大部分你的集群内的节点需要执行两个角色的任务,作为数据节点(数据存储)和任务执行节点(数据处理)。
这是在一个平衡Hadoop集群中,为数据节点/任务追踪器提供的推荐规格:
名字节点角色负责协调集群上的数据存储,作业追踪器协调数据处理(备用的名字节点不应与集群中的名字节点共存,并且运行在与之相同的硬件环境上。)。 Cloudera推荐客户购买在RAID1或10配置上有足够功率和企业级磁盘数的商用机器来运行名字节点和作业追踪器。
NameNode也会直接需要与群集中的数据块的数量成比列的RAM。一个好的但不精确的规则是对于存储在分布式文件系统里面的每一个1百万的数据块,分 配1GB的NameNode内存。于在一个群集里面的100个DataNodes而言,NameNode上的64GB的RAM提供了足够的空间来保证群集 的增长。我们也推荐把HA同时配置在NameNode和JobTracker上,
这里就是为NameNode/JobTracker/Standby NameNode节点群推荐的技术细节。驱动器的数量或多或少,将取决于冗余数量的需要。
记住, 在思想上,Hadoop 体系设计为用于一种并行环境。
如果你希望Hadoop集群扩展到20台机器以上,那么我们推荐最初配置的集群应分布在两个机架,而且每个机架都有一个位于机架顶部的10G的以太网交 换。当这个集群跨越多个机架的时候,你将需要添加核心交换机使用40G的以太网来连接位于机架顶部的交换机。两个逻辑上分离的机架可以让维护团队更好地理 解机架内部和机架间通信对网络需求。
Hadoop集群安装好后,维护团队就可以开始确定工作负载,并准备对这些工作负载进行基准测试以确定硬件瓶颈。经过一段时间的基准测试和监视,维护团队 将会明白如何配置添加的机器。异构的Hadoop集群是很常见的,尤其是在集群中用户机器的容量和数量不断增长的时候更常见-因此为你的工作负载所配置的 “不理想”开始时的那组机器不是在浪费时间。Cloudera管理器提供了允许分组管理不同硬件配置的模板,通过这些模板你就可以简单地管理异构集群了。
下面是针对不同的工作负载所采用对应的各种硬件配置的列表,包括我们最初推荐的“负载均衡”的配置:
(注意Cloudera期望你配置它可以使用的2×8,2×10和2×12核心CPU的配置。)
下图向你展示了如何根据工作负载来配置一台机器:
<ignore_js_op>
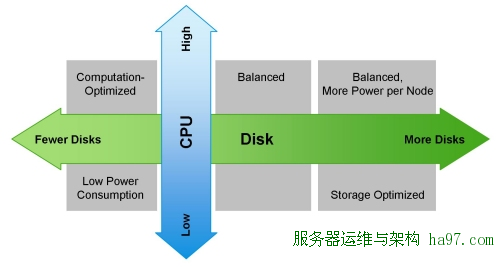 其他要考虑的
记住Hadoop生态系统的设计是考虑了并行环境这点非常重要。当购买处理器时,我们不建议购买最高频率(GHZ)的芯片,这些芯片都有很高的功耗 (130瓦以上)。这么做会产生两个问题:电量消耗会更高和热量散发会更大。处在中间型号的CPU在频率、价格和核心数方面性价比是最好的。
当我们碰到生成大量中间数据的应用时-也就是说输出数据的量和读入数据的量相等的情况-我们推荐在单个以太网接口卡上启用两个端口,或者捆绑两个以太网 卡,让每台机器提供2Gbps的传输速率。绑定2Gbps的节点最多可容纳的数据量是12TB。一旦你传输的数据超过12TB,你将需要使用传输速率为捆 绑方式实现的4Gbps(4x1Gbps)。另外,对哪些已经使用10Gb带宽的以太网或者无线网络用户来说,这样的方案可以用来按照网络带宽实现工作负 载的分配。如果你正在考虑切换到10GB的以太网络上,那么请确认操作系统和BIOS是否兼容这样的功能。
当计算需要多少内存的时候,记住Java本身要使用高达10%的内存来管理虚拟机。我们建议把Hadoop配置为只使用堆,这样就可以避免内存与磁盘之间 的切换。切换大大地降低MapReduce任务的性能,并且可以通过给机器配置更多的内存以及给大多数Linux发布版以适当的内核设置就可以避免这种切 换。
优化内存的通道宽度也是非常重要的。例如,当我们使用双通道内存时,每台机器就应当配置成对内存模块(DIMM)。当我们使用三通道的内存时,每台机器都应当使用三的倍数个内存模块(DIMM)。类似地,四通道的内存模块(DIMM)就应当按四来分组使用内存。
超越MapReduce Hadoop不仅仅是HDFS和MapReduce;它是一个无所不包的数据平台。因此CDH包含许多不同的生态系统产品(实际上很少仅仅做为 MapReduce使用)。当你在为集群选型的时候,需要考虑的附加软件组件包括Apache HBase、Cloudera Impala和Cloudera Search。它们应该都运行在DataNode中来维护数据局部性。
HBase是一个可靠的列数据存储系统,它提供一致性、低延迟和随机读写。Cloudera Search解决了CDH中存储内容的全文本搜索的需求,为新类型用户简化了访问,但是也为Hadoop中新类型数据存储提供了机会。Cloudera Search基于Apache Lucene/Solr Cloud和Apache Tika,并且为与CDH广泛集成的搜索扩展了有价值的功能和灵活性。基于Apache协议的Impala项目为Hadoop带来了可扩展的并行数据库技 术,使得用户可以向HDFS和HBase中存储的数据发起低延迟的SQL查询,而且不需要数据移动或转换。
由于垃圾回收器(GC)的超时,HBase 的用户应该留意堆的大小的限制。别的JVM列存储也面临这个问题。因此,我们推荐每一个区域服务器的堆最大不超过16GB。HBase不需要太多别的资源 而运行于Hadoop之上,但是维护一个实时的SLAs,你应该使用多个调度器,比如使用fair and capacity 调度器,并协同Linux Cgroups使用。
Impala使用内存以完成其大多数的功能,在默认的配置下,将最多使用80%的可用RAM资源,所以我们推荐,最少每一个节点使用96GB的RAM。与MapReduce一起使用Impala的用户,可以参考我们的建议 - “Configuring Impala and MapReduce for Multi-tenant Performance.” 也可以为Impala指定特定进程所需的内存或者特定查询所需的内存。
搜索是最有趣的订制大小的组件。推荐的订制大小的实践操作是购买一个节点,安装Solr和Lucene,然后载入你的文档群。一旦文档群被以期望的方式来 索引和搜索,可伸缩性将开始作用。持续不断的载入文档群,直到索引和查询的延迟,对于项目而言超出了必要的数值 - 此时,这让你得到了在可用的资源上每一个节点所能处理的最大文档数目的基数,以及不包括欲期的集群复制此因素的节点的数量总计基数。
结论购买合适的硬件,对于一个Hapdoop群集而言,需要性能测试和细心的计划,从而全面理解工作负荷。然而,Hadoop群集通常是一个形态变化的系统, 而Cloudera建议,在开始的时候,使用负载均衡的技术文档来部署启动的硬件。重要的是,记住,当使用多种体系组件的时候,资源的使用将会是多样的, 而专注与资源管理将会是你成功的关键。
我们鼓励你在留言中,加入你关于配置Hadoop生产群集服务器的经验!
Kevin O‘Dell 是一个工作于Cloudera的系统工程师。
英文原文:How-to: Select the Right Hardware for Your New Hadoop Cluster
翻译:http://www.oschina.net/translate/how-to-select-the-right-hardware-for-your-new-hadoop-cluster
附:
淘宝Hadoop集群机器硬件配置
国内外使用Hadoop的公司比较多,全球最大的Hadoop集群在雅虎,有大约25000个节点,主要用于支持广告系统与网页搜索。国内用Hadoop的主要有百度、淘宝、腾讯、华为、中国移动等,其中淘宝的Hadoop集群属于较大的(如果不是最大)。
淘宝Hadoop集群现在超过1700个节点,服务于用于整个阿里巴巴集团各部门,数据来源于各部门产品的线上数据库(Oracle, MySQL)备份,系统日志以及爬虫数据,截止2011年9月,数量总量已经超过17个PB,每天净增长20T左右。每天在Hadoop集群运行的MapReduce任务有超过4万(有时会超过6万),其中大部分任务是每天定期执行的统计任务,例如数据魔方、量子统计、推荐系统、排行榜等等。这些任务一般在凌晨1点左右开始执行,3-4个小时内全部完成。每天读数据在2PB左右,写数据在1PB左右。
<ignore_js_op> 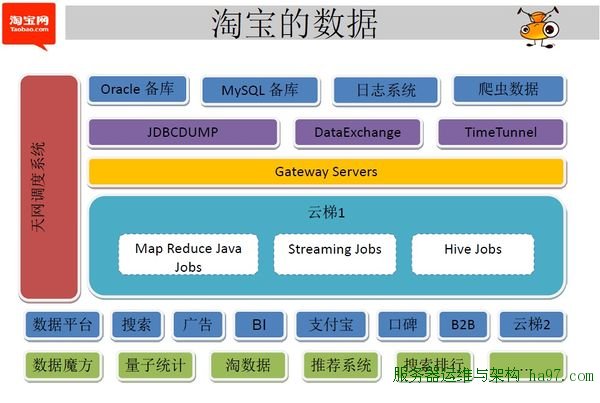 this picture is from Taobao Hadoop包括两类节点Master和Slave节点,
所有作业会进行分成多个Group,按照部门或小组划分,总共有38个Group。整个集群的资源也是按各个Group进行划分,定义每个Group的最大并发任务数,Map slots与Reduce slots的使用上限。每个作业只能使用自己组的slots资源。
|