Spring源码解析(一) -- beanfactory
spring的源码其实来来回回看过不下5次,但是之前没有总结的习惯,总是看了又忘。今天开始计划重新看一遍spring,并做记录和总结。
进入主题,我们来分析一下beanfactory的创建。
1 beanfactory的创建
AbstractApplicationContext的refresh()方法是spring容器启动的入口,而创建beanfactory又是其中的第一步。
一路分析到 AbstractRefreshableApplicationContext的refreshBeanFactory()
protected final void refreshBeanFactory() throws BeansException {
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
注意下 DefaultListableBeanFactory 的继承关系
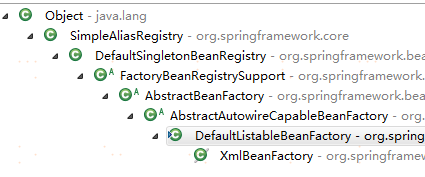
注意下这个类DefaultSingletonBeanRegistry可以说,所有实例化好了的Bean都是放在这个类里的。
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactory implements ConfigurableListableBeanFactory, BeanDefinitionRegistry, Serializable
DefaultListableBeanFactory 是实现了 BeanDefinitionRegistry接口的,说明出了用作bean的容器,他另外的作用就是注册BeanDefinition。所以上面代码中的
loadBeanDefinitions(beanFactory)就是我们要重点分析的方法
public abstract class AbstractBeanFactory 中的Map就是用来保存所有解析出来的BeanDefinition的
/** Map from bean name to merged RootBeanDefinition */ private final Map<String, RootBeanDefinition> mergedBeanDefinitions = new ConcurrentHashMap<String, RootBeanDefinition>(256);
2 loadBeanDefinitions
继续跟代码找到一个重要的类XmlBeanDefinitionReader,它是解析xml,并且把xml中的节点转换成BeanDefinition的关键
它有一个成员变量,待会也是我们要讲解的重点
private NamespaceHandlerResolver namespaceHandlerResolver;
一路分析就找到 XmlBeanDefinitionReader的 doLoadBeanDefinitions,进一步找到DefaultBeanDefinitionDocumentReader的 doRegisterBeanDefinitions。doRegisterBeanDefinitions才是我们要分析的重点
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
先说结论,该方法做的事情很明确就是解析xml文件中的各个节点,delegate.isDefaultNamespace判断该节点是否是默认命名空间,所谓默认命名空间就是指beans这种节点所在的命名空间。而对一些非beans的节点,比如我们也比较常用的aop,还有做定时调度的task标签,走的就是else分支也就是delegate.parseCustomElement。
对于节点的解析,不必细讲。接下来重点分析BeanDefinitionParserDelegate 及其相关的源码,和spring的命名空间解析机制。
3 Spring的命名空间解析机制
要分析命名空间,可以从上一节的 BeanDefinitionParserDelegate 入手。
public BeanDefinitionParserDelegate(XmlReaderContext readerContext) {
Assert.notNull(readerContext, "XmlReaderContext must not be null");
this.readerContext = readerContext;
}
构造方法是要传入一个XmlReaderContext,继续分析 XmlReaderContext
public class XmlReaderContext extends ReaderContext {
private final XmlBeanDefinitionReader reader;
private final NamespaceHandlerResolver namespaceHandlerResolver;
XmlReaderContext包含着一个重要的成员变量 NamespaceHandlerResolver
ReaderContext是在把配置文件解析成beandefinition过程中创建的,代码在 XmlBeanDefinitionReader 的 registerBeanDefinitions 方法
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
一路追踪终于找到了 上面说的那个重要的成员变量 namespaceHandlerResolver的初始化位置。
public DefaultNamespaceHandlerResolver(ClassLoader classLoader) {
this(classLoader, DEFAULT_HANDLER_MAPPINGS_LOCATION); // DEFAULT_HANDLER_MAPPINGS_LOCATION 值为 META-INF/spring.handlers
}
以及里面的重要方法
@Override
public NamespaceHandler resolve(String namespaceUri) {
Map<String, Object> handlerMappings = getHandlerMappings();
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
其中的getHandlerMappings就是去扫描classloader能找到范围内,所有jar包里的META-INF/spring.handlers中内容
我们可以看一下具体的实现
public static Properties loadAllProperties(String resourceName, ClassLoader classLoader) throws IOException {
Assert.notNull(resourceName, "Resource name must not be null");
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = ClassUtils.getDefaultClassLoader();
}
Enumeration<URL> urls = (classLoaderToUse != null ? classLoaderToUse.getResources(resourceName) :
ClassLoader.getSystemResources(resourceName));
Properties props = new Properties();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
URLConnection con = url.openConnection();
ResourceUtils.useCachesIfNecessary(con);
InputStream is = con.getInputStream();
try {
if (resourceName.endsWith(XML_FILE_EXTENSION)) {
props.loadFromXML(is);
}
else {
props.load(is);
}
}
finally {
is.close();
}
}
return props;
}
resourceName就是 META-INF/spring.handlers
再来看一眼 META-INF/spring.handlers里面是什么样子,以aop为例,
 内容是
内容是
http://www.springframework.org/schema/aop=org.springframework.aop.config.AopNamespaceHandler
这样 每个命名空间和他对应的解析类绑定在一起
再回到 BeanDefinitionParserDelegate的代码中
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(ele);
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
每一个spring xml中的节点都有一个命名空间,这是定义在每一个xsd文件中的,而且spring配置文件的beans的属性中有每个命名空间对应的xsd的名字,这样每个节点标签对应的命名空间就能够获取到了
总结:
在AbstractApplicationContext中第一步就是拿到beanfactory,这一步做完之后,通过BeanDefitionReader获取到的BeanDefinition,并注册到beanfactory的map中缓存起来。我这里没说全部的BeanDefinition,因为考虑到Spring如果是以Configuration标签方式而不是xml方式的话,拿到beanfactory的时候只能拿到一个beanfactorypostprocessor,就是ConfigurationClassPostProcessor这个 beanFactoryPostProcessor,再由它去完成BeanDefinition的注册。