一、集合概览
1. 集合与数组:数组是定长的,集合是变长的
2. 集合的接口是Collection,数据结构有Map/List/Set
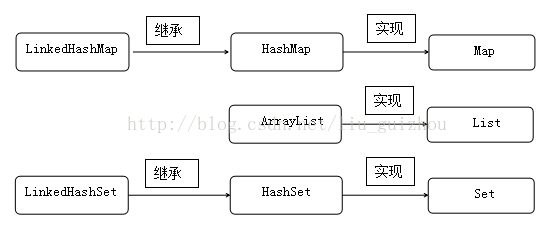
3. 集合继承关系
二、HashMap定义:
1. Hash表(key-value),根据key(hash code)找到对应的value;会有hash冲突
2. 是基于Hash表的Map实现,Map即key-value的接口
public class HashMap<K,V>
extends AbstractMap<K,V> // 继承AbstractMap抽象类,这个抽象类提供了Map接口的最主要功能的实现
implements Map<K,V>, Cloneable, Serializable // 实现Map接口,这个接口定义了键映射到值的规则
三、数据结构
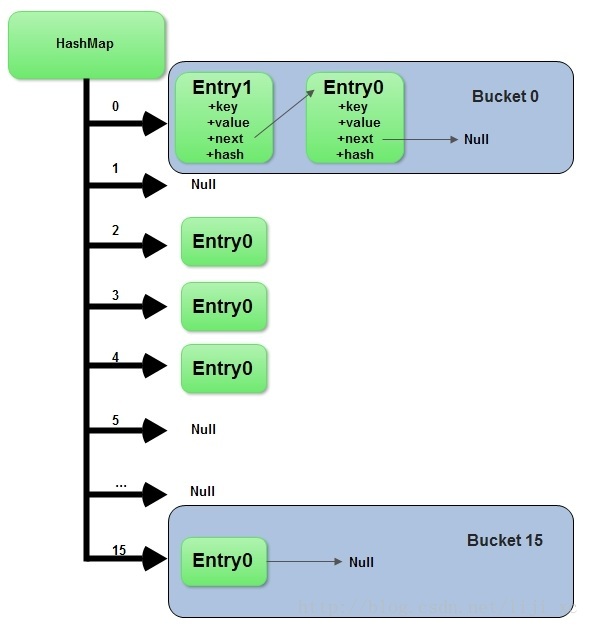
1. JDK1.7的HashMap是由数组和链表组合实现的,一个数组的值加上其链表,叫做一个散列桶

2. 链表的每一项为Entry,Entry为HashMap的内部类,包含4个字段:key(键),value(值),next(下一节点),hash(hash值)
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; /** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } ....... }
3. JDK1.8的HashMap是由数组+链表/红黑树组成
a. 当链表长度大于8,会转换成红黑树,树高比链表短,可以提高查询效率
b. 当红黑树节点小于6,会转化为链表
四、 装载因子和扩容:
1. 装载因子表示hash表中元素的填满程度,装载因子越大则空间利用率高,冲突机会也大,查找耗时也越大
2. HashMap容量:即数据结构中数组的大小,默认16,默认装载因子0.75,即阈值12,一旦大于等于阈值,2倍扩大空间,最大容量2^30
3. 扩容会使key进行rehash,即重新计算hash值,损耗性能,如果能预估HashMap中元素个数,预设个数能避免扩容,提高性能
HashMap():默认初始容量(16)和加载因子(0.75)
HashMap(int initialCapacity):可以自定义初始容量,预估个数能提高性能,因为动态扩容会损耗性能
HashMap(int initialCapacity, float loadFacotor):可以自定义初始容量和加载因子
4. JDK1.7的HashMap扩容会存在条件竞争,多线程下扩容,会造成死锁,因此不是线程安全的
5. JDK1.8的HashMap解决了扩容死锁的问题;扩容时也不再进行rehash,提高了扩容效率;
五、存储实现过程:put(key,value)
1. key可以为null,当key为null时,调用putForNullKey方法
2. 通过key的hashCode()方法计算key的hash值,根据hash值确认在table数组中的索引位置
3. 如果table中没有元素,直接插入
4. 否则遍历Entry,通过equals()方法比较key,如果不同则插入链表头,调用addEntry方法;否则替换掉旧值,所以没有相同的key
5. 如果链表长度超过了阈值8,就把链表转成红黑树,链表长度低于6,就把红黑树转回链表;
a. 使用红黑树,因为红黑树是平衡二叉树
b. 不使用二叉树,因为二叉树在极端的情况下,会变成一条线性结构
6. 如果数组容量超过了装载因子,就需要扩容
public V put(K key, V value) { //当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因 if (key == null) return putForNullKey(value); //计算key的hash值 int hash = hash(key.hashCode()); ------(1) //计算key hash 值在 table 数组中的位置 int i = indexFor(hash, table.length); ------(2) //从i出开始迭代 e,找到 key 保存的位置 for (Entry<K, V> e = table[i]; e != null; e = e.next) { Object k; //判断该条链上是否有hash值相同的(key相同) //若存在相同,则直接覆盖value,返回旧value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; //旧值 = 新值 e.value = value; e.recordAccess(this); return oldValue; //返回旧值 } } //修改次数增加1 modCount++; //将key、value添加至i位置处 addEntry(hash, key, value, i); return null; }
六、读取实现过程:get(key)
1. 根据key的hash值找到Entry
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
2. 通过keys.equals()方法找到链表中正确的位置
七、如何减少碰撞
1. 使用扰动函数,使不相等的对象返回不同的hashcode
2. 使用包装类(例如Integer, String)作为key,String是不可变的,作为key,键值就是不变的,可以缓存其hashcode
八、 HashMap和HashTable的区别(几乎可以等价,HashTable已经过时,不推荐使用):都实现了Map接口
1. HashMap不是同步(synchronized)的,所以不是线程安全的,即多线程环境下可能有问题
a. 可以用ConcurrentHashMap解决线程安全问题
b. 用Collections.synchronizeMap(hashMap)方法解决线程安全问题
2. HashTable是同步的,是线程安全的,但在单线程比较慢,同步会加同步锁,意味着一次仅有一个线程能够更新对象
3. HashMap可以接受key为null,而HashTable不行
4. HashMap的迭代器(Iterator)是fail-fast迭代器,可能在多线程环境下更改结构时出ConcurrentModificationException异常;而HashTable的迭代器(Enumerator)不是
5. HashMap不能保证元素的排列次序,所以次序可能会变,即不是有序的,可以使用TreeMap或者LinkedHashMap代替
6. TreeMap实现了SortMap接口,基于红黑树,对key进行排序
7. LinkedHashMap通过插入排序和访问排序,让key变得有序
九、使用线程安全的集合类:ConcurrentHashMap和CopyOnWriteArrayList
1. 同步的集合类(HashTable和Vector),同步的封装类(使用Collections.synchronizeMap()和Collections.synchronizeList()方法返回的对象)是线程安全的
2. 但是不适合高并发的系统,它们仅有单个同步锁,并且对整个集合加锁,以及为了防止ConcurrentModificationException异常经常在迭代的时候将集合锁定一段时间
十、ConcurrentHashMap和HashTable的区别
a. HashTable的大小增加到一定的时候,性能会急剧下降,因为迭代的时候会对整个对象锁定很长时间
b. ConcurrentHashMap引入了分割(Segmentation),在迭代的过程中,仅仅锁定map的某个部分,而HashTable是锁住整个Map,因此比HashTable性能好
十一、HashMap与HashSet的区别,存储不同数据类型
1. HashMap实现了Map接口,存储键值对,不允许有重复的Key;HashSet实现了Set接口,存储对象,不允许有重复的值
2. 添加元素:HashMap: put(Object key, Object value); HashSet: add()
引申:
1. 为什么扩容只能是2个n次方?
求余数操作太耗时,位操作能快速得到hash值在数组中的位置,2的n次方会方便位操作(与操作,异或操作)
2. 为什么默认装载因子是0.75?
3. 为什么链表长度是8的时候,会转为红黑树?
4. 为什么JDK1.7的HashMap扩容会死锁?
扩容的时候,链表是倒序插入新的HashMap中,用变量e和next指向链表的当前节点和下一个节点,当前线程指向节点后,切换到另一个线程,另一个线程倒序生成了链表,next会发生变化,就产生了循环链表
5. 为什么重写对象的equals方法时,要重写hashcode方法?
如果用到了hashMap,把对象作为key,另一个对象equals当前对象,但get另一个对象的时候会获取不到值,因为get方法会判断对象的hashcode是否相等
6. 为什么hashMap的key要用不可变类型,比如String,或者加final?
如果对象改变了,key就变了,用这个对象get的时候就获取不到了