这篇文章是基于上一篇文章的续集
一:需求
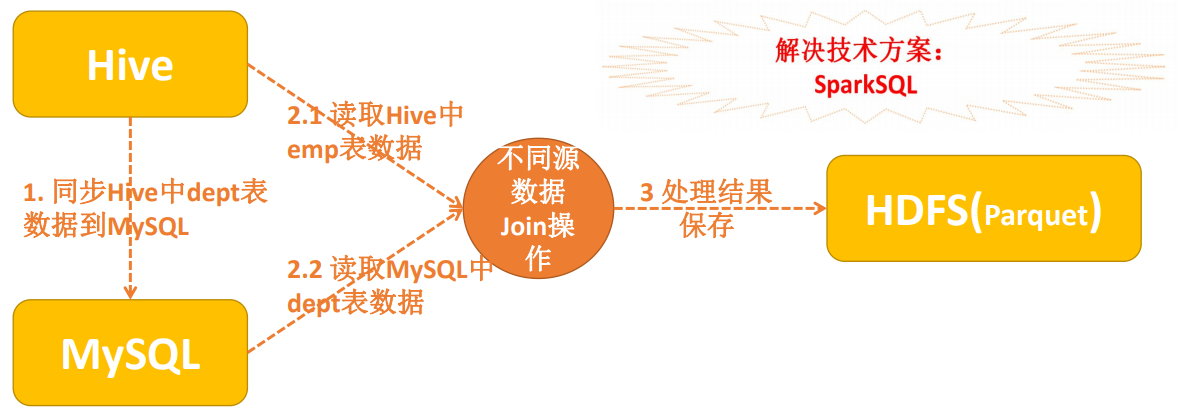
1.图形表示
二:程序
1.程序、
1 package com.scala.it 2 3 import java.util.Properties 4 5 import org.apache.spark.sql.SaveMode 6 import org.apache.spark.sql.hive.HiveContext 7 import org.apache.spark.{SparkConf, SparkContext} 8 9 object HiveToMysql { 10 def main(args: Array[String]): Unit = { 11 val conf = new SparkConf() 12 .setMaster("local[*]") 13 .setAppName("hive-yo-mysql") 14 val sc = SparkContext.getOrCreate(conf) 15 val sqlContext = new HiveContext(sc) 16 val (url, username, password) = ("jdbc:mysql://linux-hadoop01.ibeifeng.com:3306/hadoop09", "root", "123456") 17 val props = new Properties() 18 props.put("user", username) 19 props.put("password", password) 20 21 // ================================== 22 // 第一步:同步hive的dept表到mysql中 23 sqlContext 24 .read 25 .table("hadoop09.dept") // database.tablename 26 .write 27 .mode(SaveMode.Overwrite) // 存在覆盖 28 .jdbc(url, "mysql_dept", props) 29 30 // 第二步:hive表和mysql表进行数据join操作 ==> 采用HQL语句实现 31 // 2.1 将mysql的数据注册成为临时表 32 sqlContext 33 .read 34 .jdbc(url, "mysql_dept", props) 35 .registerTempTable("temp_mysql_dept") // 临时表中不要出现"." 36 37 // 第三步数据join 38 sqlContext.sql( 39 """ 40 |SELECT a.*,b.dname,b.loc 41 |FROM hadoop09.emp a join temp_mysql_dept b on a.deptno = b.deptno 42 """.stripMargin) 43 .write 44 .format("org.apache.spark.sql.execution.datasources.parquet") 45 .mode(SaveMode.Overwrite) 46 .save("/spark/join/parquet") 47 48 // 检测数据是否join成功 49 sqlContext 50 .read 51 .format("parquet") 52 .load("/spark/join/parquet") 53 .show() 54 55 } 56 }
2.效果

三:知识点
1.format
可以写包名。