1、order by:全局排序
select * from emp order by sal;
对于一个reduce才有用。
2、sort by:对于每个reduce进行排序
set mapreduce.job.reduces=3;
这里设置了reduce为3。
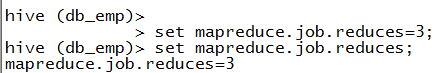
原本的结果放在控制台上,看的效果不是太清楚,所以将hive的结果到出到本文件。
insert overwrite local directory '/opt/datas/emp_sort' row format delimited fields terminated by ' ' select * from emp sort by sal;

结果:

3、distribute by :底层就是mapreduce 的分区,一般与sort by连用
先按照deptno进行分区,然后sort by每个reduce。
insert overwrite local directory '/opt/datas/emp_dis' row format delimited fields terminated by ' ' select * from emp distribute by deptno sort by sal;

4、cluster by:等价于distribute by 与sort by的字段相同时
分区与排序都是一个字段,可以使用这个。
应该说,这个是上面的一种特殊情况,我感觉可能会用的少一些。
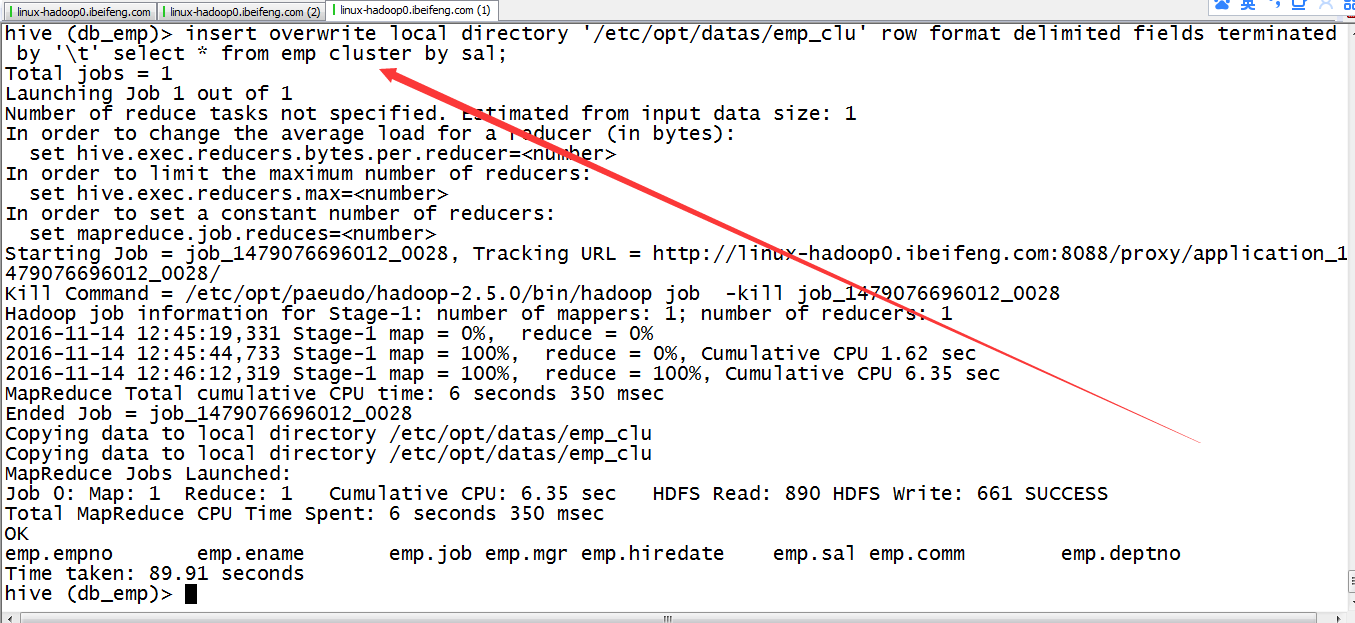
insert overwrite local directory '/opt/datas/emp_cls' row format delimited fields terminated by ' ' select * from emp cluster by sal;