一:将数据导入hive(六种方式)
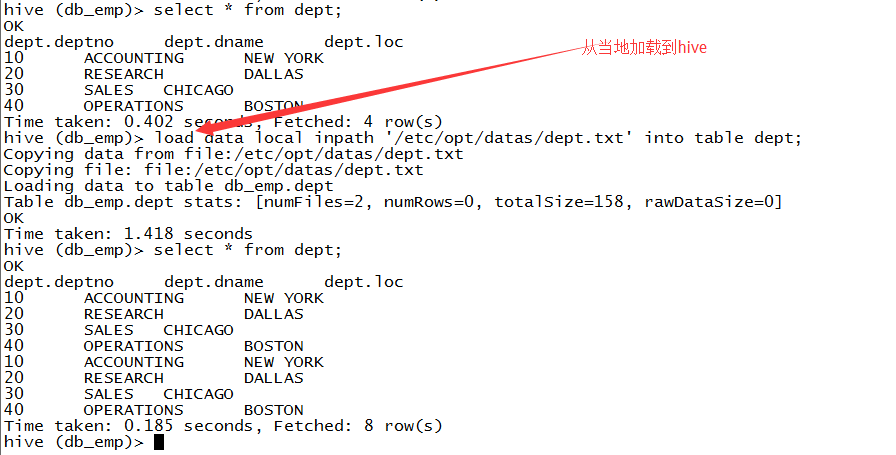
1.从本地导入
load data local inpath 'file_path' into table tbname;
用于一般的场景。
2.从hdfs上导入数据
load data inpath ‘hafd_file_path’ into table tbname;
应用场景:使用与大数据的存储
3.load方式的覆盖
load data local inpath 'file_path' overwrite into table tbname;
应用场景:用于临时表。

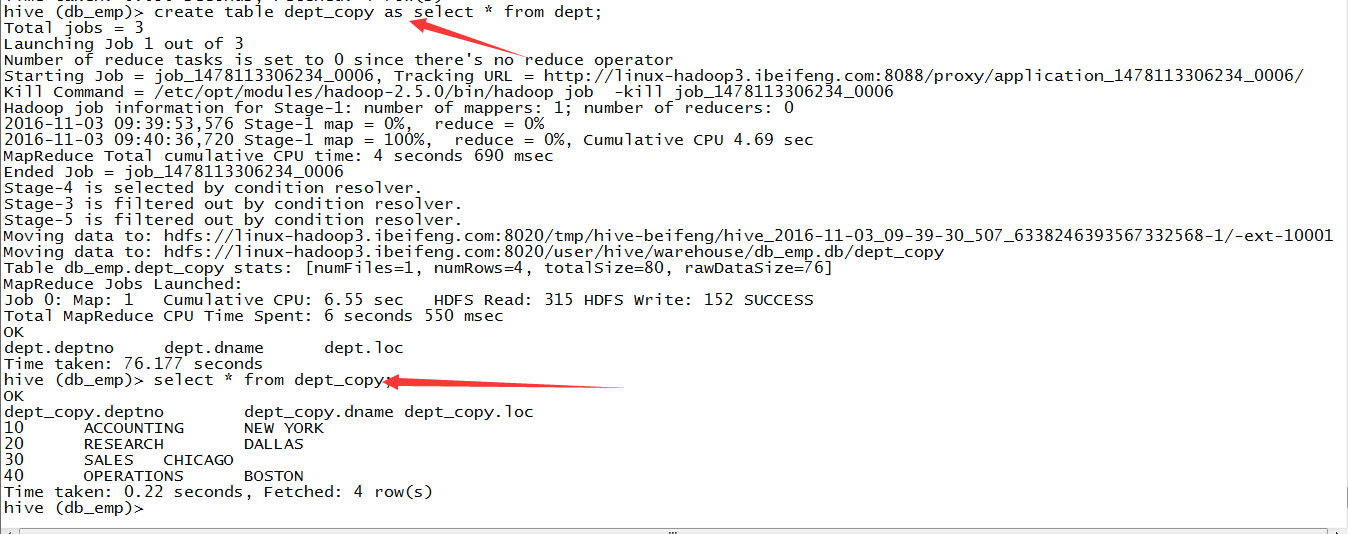
4.子查询方式
应用场景:对于数据查询的结构的保存。
create table tb2 as select * from tb1;
5.insert into
应用场景:和上面的应用场景相同,因为后面接的都是select查询。
不需要as,直接后接入select。
insert into table tb2 select q1;

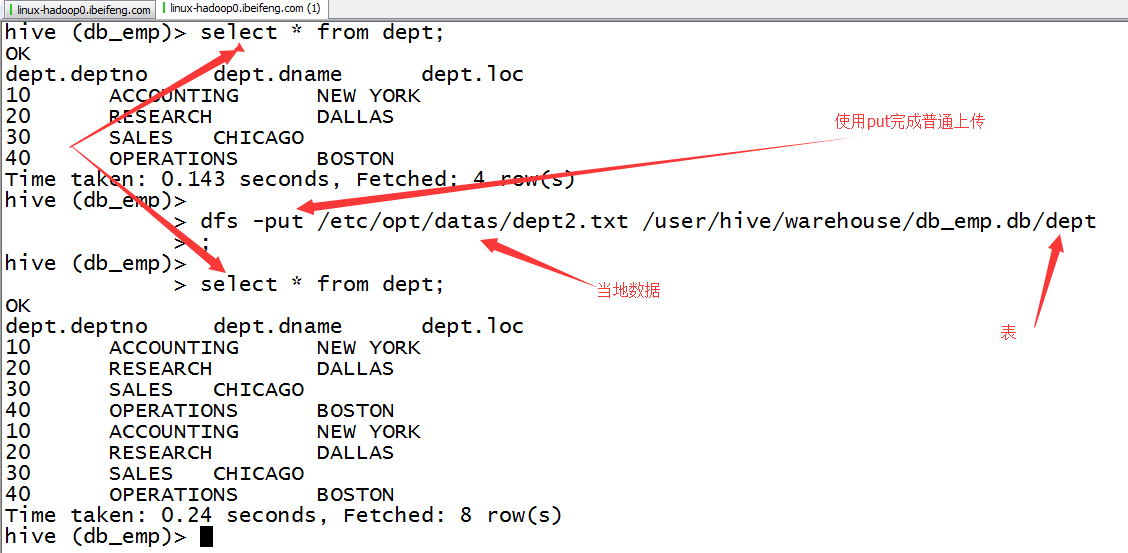
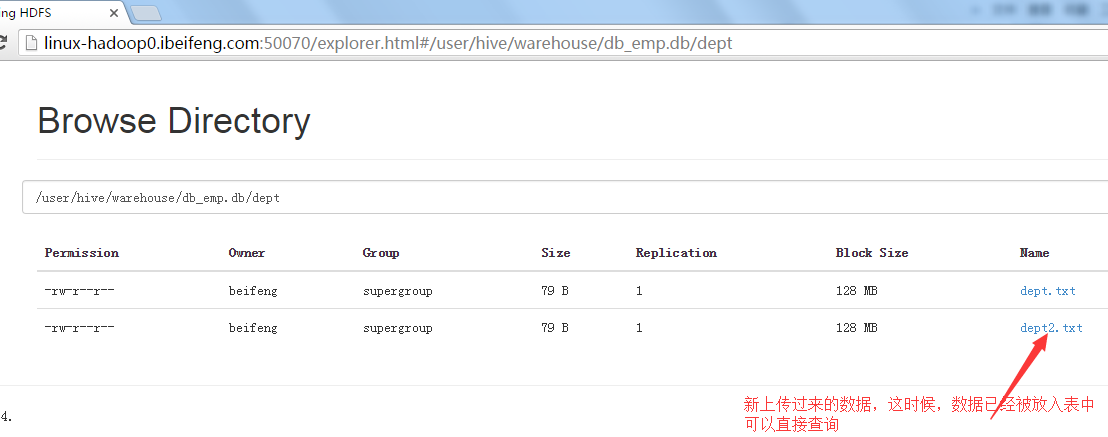
6.location
这种情况适用于前面说的外部表,或者管理表中对于表数据的指定。
然后put就好。
我想,前提是需要先建一个表。
在HDFS上看效果
二:将数据从hive里导出(四种方式)
1.insert方式
1)保存到本地
语句:insert overwrite local directory 'path' select q1;
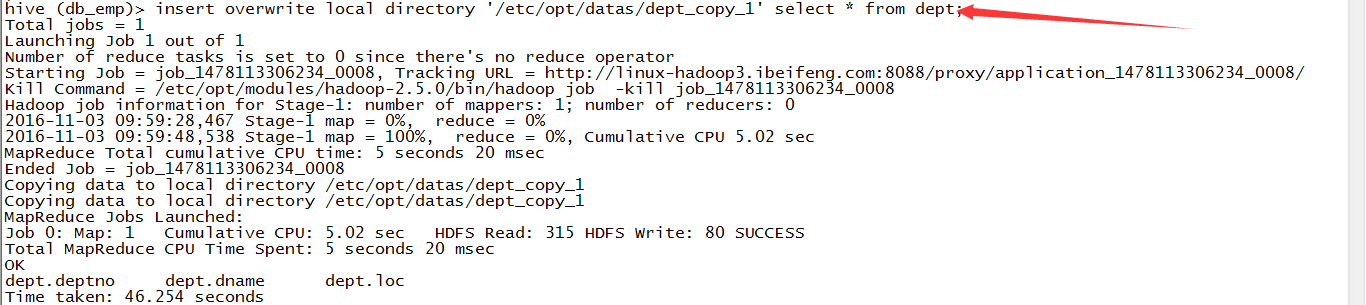
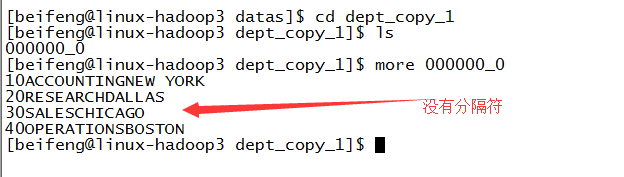
效果:但是效果不好,没有分隔符
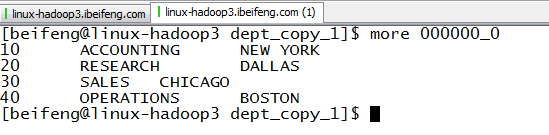
改造:insert overwrite local directory 'path' row format delimited fields terminated by ' ' select q1;

效果:
2)保存到HDFS上
insert overwrite directory 'hdfs_path' select * from dept;
注意点:hdfs_path必须存在,这个说的是多级目录,但是最后一级的目录是自动生成的。
2.bin/hdfs -get
与put一样,属于HDFS的基本操作。
dfs -get .............
3.linux命令行执行HQL
使用 -e
使用 -f
然后重定向到指定的文件。
4.sqoop协作框架。
后面将会有关于sqoop的专门篇章。
HDFS与关系型数据库之间的数据导入与到出。