身为一个搬砖小能手,每周必刷Git,开源项目一日不刷心痒难耐,独乐乐不如众乐乐,七仔,灵机一动,分享出来让大家看看七仔的品位,不赘述看项目:
目录
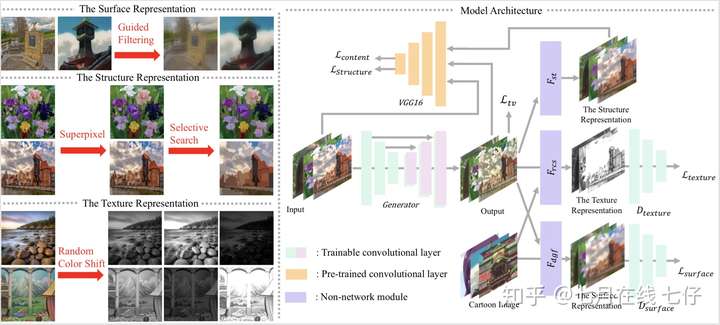
- White-box-Cartoonization 论文“使用白盒卡通表示进行卡通化学习”的tensorflow官方实现
- text_data_enhancement_with_LaserTagger基于lasertagger的中文文本数据增强
- pfrl基于PyTorch的深度强化学习库
- deep-person-search PyTorch实现的深度学习人员搜索5、UnilmUniLM模型开源实现
- medical_entity_recognize医疗实体识别
- dslp-repo-template数据科学生命周期项目的模板8、MTCNN全平台实时人脸检测和姿态估计
1、White-box-Cartoonization 论文“使用白盒卡通表示进行卡通化学习”的tensorflow官方实现
项目环境:
- 训练代码使用Linux或者Windows
- NVIDIA GPU + CUDA CuDNN
- 推理代码使用Linux,Windows或者MacOs
- tensorflow-gpu 1.12.0或者1.13.0rc0
- scikit-image 0.14.5
数据集:
- 从新海诚,宫崎骏和细田守拍摄的风景图像
- 将影片剪辑成帧并随机裁剪并调整为256x256
- 肖像图像来自京都动画和PA Works
- 使用此仓库(https://github.com/nagadomi/lbpcascade_animeface)检测面部区域
训练:
- 将训练数据放在/ dataset中的相应文件夹中
- 运行pretrain.py,结果将保存在/ pretrain文件夹中
- 运行train.py,结果将保存在/ train_cartoon文件夹中
- 可以在以下网址找到预训练的VGG_19模型:https://http://drive.google.com/file/d/1j0jDENjdwxCDb36meP6-u5xDBzmKBOjJ/view?usp = sharing



项目地址:https://github.com/SystemErrorWang/White-box-Cartoonization
电商推荐系统实战特训

2、text_data_enhancement_with_LaserTagger 基于lasertagger的中文文本数据增强
文本复述任务是指把一句/段文本A改写成文本B,要求文本B采用与文本A略有差异的表述方式来表达与之意思相近的文本。
改进谷歌的LaserTagger模型,使用LCQMC等中文语料训练文本复述模型,即修改一段文本并保持原有语义。复述的结果可用于数据增强,文本泛化,从而增加特定场景的语料规模,提高模型泛化能力。谷歌在文献《Encode, Tag, Realize: High-Precision Text Editing》中采用序列标注的框架进行文本编辑,在文本拆分和自动摘要任务上取得了最佳效果。在同样采用BERT作为编码器的条件下,本方法相比于Seq2Seq的方法具有更高的可靠度,更快的训练和推理效率,且在语料规模较小的情况下优势更明显。
实验效果:
- 在公开数据集Wiki Split上复现模型:Exact score=15,SARI score=61.5,KEEP score=93,ADDITION score=32,DELETION score=59
- 在自己构造的中文数据集训练文本复述模型:对25918对文本进行复述和自动化评估 Exact score=29,SARI score=64,KEEP score=84,ADDITION score=39,DELETION score=66.
项目地址:https://github.com/tongchangD/text_data_enhancement_with_LaserTagger
3、pfrl 基于PyTorch的深度强化学习库

PFRL是一个深度强化学习库,它使用PyTorch在Python中实现了各种最新的深度强化算法。实现算法:
| 算法 | 离散动作 | 连续动作 | 循环模型 | 批量训练 | CPU 异步训练 |
| DQN (including DoubleDQN etc.) | ✓ | ✓ (NAF) | ✓ | ✓ | x |
| Categorical DQN | ✓ | x | ✓ | ✓ | x |
| Rainbow | ✓ | x | ✓ | ✓ | x |
| IQN | ✓ | x | ✓ | ✓ | x |
| DDPG | x | ✓ | x | ✓ | x |
| A3C | ✓ | ✓ | ✓ | ✓ (A2C) | ✓ |
| ACER | ✓ | ✓ | ✓ | x | ✓ |
| PPO | ✓ | ✓ | ✓ | ✓ | x |
| TRPO | ✓ | ✓ | ✓ | ✓ | x |
| TD3 | x | ✓ | x | ✓ | x |
| SAC | x | ✓ | x | ✓ | x |
环境要求:
- torch>=1.3.0
- gym>=0.9.7
- numpy>=1.10.4
项目地址:https://github.com/pfnet/pfrl
4、deep-person-search PyTorch实现的深度学习人员搜索
该项目开发了具有高性能的基线模型,并实现了广泛使用的基线OIM和NAE。
- 纯PyTorch代码,要求PyTorch版本> = 1.1.0
- 支持多图像批处理训练。
- 端到端的训练和评估。PRW和CUHK-SYSU均受支持。
- 大多数研究论文使用的标准协议(包括PRW-mini)
- 高度可扩展(易于添加模型,数据集,训练方法等)
- 可视化工具(建议,培训损失)
- 高性能基准。

效果比较:
CUHK-SYSU PRW MethodmAPrank1mAPrank1OIM88.189.236.076.7NAE89.890.737.977.3baseline90.091.040.581.3
项目地址:https://github.com/DeepAlchemist/deep-person-search
5、UnilmUniLM模型开源实现
UniLM模型既可以应用于自然语言理解(NLU)任务,又可以应用于自然语言生成(NLG)任务。论文来自微软研究院。训练环境:torch 1.4.0transformers 2.6.0数据集CSL 中长文本摘要生成:
| 模型 | rouge-1 | rouge-2 | rouge-L | BLUE | 参数 |
| bert_base | 61.71% | 50.97% | 60.51% | 41.10% | batch_size=24, length=512, epoch=5, lr=1e-5 |
| unilm | 62.13% | 51.20% | 60.61% | 41.81% | batch_size=24, length=512, epoch=5, lr=1e-5 |
微博新闻摘要数据,从新闻摘要数据中随机挑选10000篇作为训练集,1000篇作为测试集。
| 模型 | rouge-1 | rouge-2 | rouge-L | BLUE | 参数 |
| bert_base | 39.74% | 28.69% | 38.68% | 20.02% | batch_size=24, length=512, epoch=5, lr=1e-5 |
| unilm | 40.58% | 29.60% | 39.21% | 21.35% | batch_size=24, length=512, epoch=5, lr=1e-5 |
项目地址:https://github.com/YunwenTechnology/Unilm
6、medical_entity_recognize 医疗实体识别
用BILSTM+CRF做医疗实体识别,框架为pytorch。项目环境:
- python=3.6.2
- torch=1.1.0
- jieba=0.42.1
数据集:提供了40M左右的医疗NER数据集,已经标注好了,并划分为了训练集/验证集/测试集。训练集/验证集/测试集的样本量(一个句子为一个样本)为:101218 / 7827 / 16804.模型的效果:模型在测试集上的F1值可达0.976,效果比较好。代码的优化点:
- 样本和标签前后不需加入和标记,因为pytorch-crf这个包自动会加上这两个标记的转移概率;
- 加入了分词特征,做成20维的嵌入,和100维字向量拼接;
- 3 batch分桶,减少zero pad;
- 在计算loss时对pad进行mask;
- 用CoNLL-2000的评估脚本来评估,权威。
参考代码:BILSTM+CRF的模型主要参考了以下代码https://github.com/Alic-yuan/nlp-beginner-finishCoNLL-2000的python版评估脚本来自https://github.com/spyysalo/conlleval.py项目地址:https://github.com/DengYangyong/medical_entity_recognize
7、dslp-repo-template 数据科学生命周期项目的模板
用作使用数据科学生命周期过程的数据科学项目的模板项目。此项目旨在作为启动点。我们的目标是在此项目的结构中仅引入最低限度的可行意见,以使该项目/框架在各种数据科学项目和工作流程中有用。因此,如果我们不确定某个东西的广泛用途或认为它过于自以为是,那么我们往往会倾向于忽略该东西。这不应该阻止您分叉此存储库,并使其适应项目/团队/组织的需求。
├── .cloud # for storing cloud configuration files and templates (e.g. ARM, Terraform, etc)
├── .github
│ ├── ISSUE_TEMPLATE
│ │ ├── Ask.md
│ │ ├── Data.Aquisition.md
│ │ ├── Data.Create.md
│ │ ├── Experiment.md
│ │ ├── Explore.md
│ │ └── Model.md
│ ├── labels.yaml
│ └── workflows
├── .gitignore
├── README.md
├── code
│ ├── datasets # code for creating or getting datasets
│ ├── deployment # code for deploying models
│ ├── features # code for creating features
│ └── models # code for building and training models
├── data # directory is for consistent data placement. contents are gitignored by default.
│ ├── README.md
│ ├── interim # storing intermediate results (mostly for debugging)
│ ├── processed # storing transformed data used for reporting, modeling, etc
│ └── raw # storing raw data to use as inputs to rest of pipeline
├── docs
│ ├── code # documenting everything in the code directory (could be sphinx project for example)
│ ├── data # documenting datasets, data profiles, behaviors, column definitions, etc
│ ├── media # storing images, videos, etc, needed for docs.
│ ├── references # for collecting and documenting external resources relevant to the project
│ └── solution_architecture.md # describe and diagram solution design and architecture
├── environments
├── notebooks
├── pipelines # for pipeline orchestrators i.e. AzureML Pipelines, Airflow, Luigi, etc.
├── setup.py # if using python, for finding all the packages inside of code.
└── tests # for testing your code, data, and outputs
├── data_validation
└── unit
8、MTCNN 全平台实时人脸检测和姿态估计
MTCNN提出了一个新的统一的包含3个网络的多任务学习框架来融合检测和对齐两个任务, 在第一个阶段使用浅层网络快速筛选出所有可能的候选滑窗,在第二个阶段使用更复杂的网络拒绝大量非人脸滑窗,在最后一个阶段使用更有力的网络来进一步修正框并输出5个点的位置.得益于这种多任务学习的方式,MTCNN性能提升非常明显, 其三个主要贡献在于:
- 提出了一种新的联合人脸检测和对齐的级联CNN框架,并且为实时性能精心设计了轻量级的网络结构
- 提出了一种有效的在线难例挖掘来提高性能
- 在具有挑战性的评估集上进行了大量的实验,并取得了最好的性能
本项目集成了其在OpenCV dnn、caffe、ncnn和pycaffe、tensorflow等框架以及不依赖任何第三方库的使用,可以跨Windows、Linux和Mac运行, 此外还提供了android端apk包,其可以在一加6(高通845)上实时运行. 在cpp工程里还提供了基于5个点进行姿态估计的示例.

使用方法:1.首先按照MRHead描述的方法配置好opencv跨版本和平台编译环境2.配置依赖的库,不是所有的库都是必须的,如果只是想看看效果,第一个只配置opencv就可以了.Fast-MTCNN使用opencv的dnn模块进行预测,需要使用3.4.*以上,或者3.*以上并自行打开开关编译dnn支持,只要配置好opencv即可运行MTCNN-light使用openblas进行运算加速,在github下载其预先编译好的库即可 , 比如OpenBLAS-0.3.10-x64.zip, 其可以直接移植到Android和iOS上.cpp需要依赖caffe1.0,可参考教程
项目地址:https://github.com/imistyrain/MTCNN
秒杀福利:请点击查看↓