EXPLAIN执行计划分类
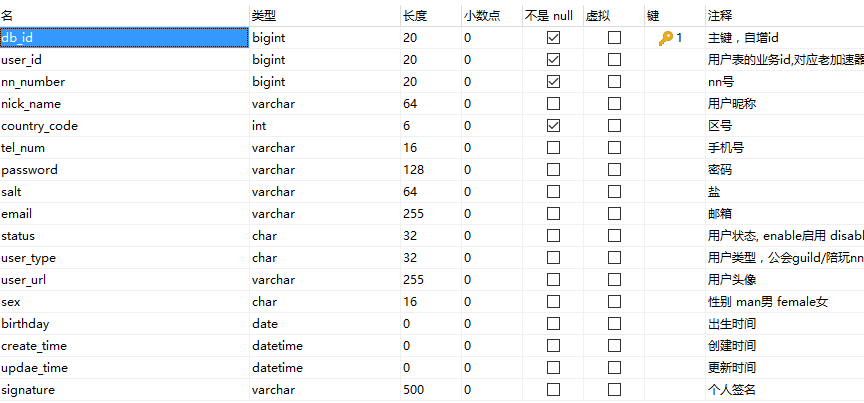
案例表结构:
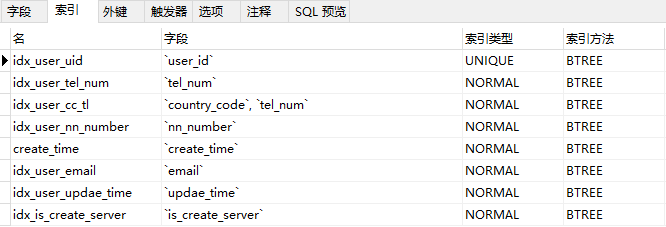
索引结构:
1.all 全表扫描
MYSQL扫描全表来找到匹配的行
例如:
EXPLAIN SELECT * FROM `t_user` WHERE nick_name='鹅鹅鹅'

例如
EXPLAIN SELECT nn_number FROM `t_user` WHERE nick_name='鹅鹅鹅'

2.index 索引全扫描
索引全扫描,MYSQL遍历整个索引来查找匹配的行。(虽然where条件中没有用到索引,但是要取出的列nn_number是索引包含的列,所以只要全表扫描索引即可,直接使用索引树查找数据)
例如:
EXPLAIN SELECT nn_number FROM `t_user`

3.range 索引范围扫描
索引范围扫描,常见于<、<=、>、>=、between等操作符(因为nn_number是索引,所以只要查找索引的某个范围即可,通过索引找到具体的数据)
例如:nn_number 为 普通索引时
EXPLAIN SELECT * FROM `t_user` WHERE nn_number between 200000 and 800000

例如: user_id 是唯一索引时
EXPLAIN SELECT * FROM `t_user` WHERE user_id between 200000 and 800000

注意:
range类型: 在查询数据量不同的情况下,不一定走索引,MySQL 优化器会可能会优化成全表扫描 type为all
例如:数据量较小的情况下 ,可以看到是可以走索引的
EXPLAIN SELECT * FROM `t_user` WHERE nn_number > 1000 and nn_number < 145000

例如:数据量较大的情况下,SQL不会走索引
EXPLAIN SELECT * FROM `t_user` WHERE nn_number > 1000 and nn_number < 145000000

原因:
MySQL 索引不总是会起作用,MySQL 优化器会判断SQL是否走索引查的更快,若是,就走索引
数据量超过30%是优化器判断是否走索引的一个标准,还有其他标准,
参考MySQL 文档: https://dev.mysql.com/doc/refman/5.7/en/range-optimization.html

Each table index is queried, and the best index is used unless the optimizer believes that it is more efficient to use a table scan.
表中的每个索引都会被访问,当中最佳的那个则会被使用,除非优化器认为使用全表查询比使用所有查询更高效。
At one time, a scan was used based on whether the best index spanned more than 30% of the table, but a fixed percentage no longer determines the choice between using an index or a scan.
曾经,是否进行全表扫描取决于使用最好的索引查出来的数据是否超过表的30%的数据,但是现在这个固定百分比(30%)不再决定使用索引还是全表扫描了。
The optimizer now is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size.
优化器现在变得更复杂,它考虑的因素更多,比如表大小、行数量、IO块大小。
可以使用强制SQL走索引,改变MySQL 优化器对SQL 的优化
例如:
EXPLAIN SELECT * FROM `t_user` force INDEX(idx_user_nn_number) WHERE nn_number > 1000 and nn_number < 145000000

4.ref
使用非唯一性索引或者唯一索引的前缀扫描,返回匹配某个单独值的记录行。
EXPLAIN SELECT * FROM `t_user` WHERE nn_number ='10086'

5.eq_ref
相对于ref来说就是使用的是唯一索引,对于每个索引键值,只有唯一的一条匹配记录(在联表查询中使用primary key或者unique key作为关联条件)
6.const / system
单表中最多只有一条匹配行,查询起来非常迅速,所以这个匹配行中的其他列中的值可以被优化器在当前查询中当做常量来处理。例如根据主键或者唯一索引进行的查询。
EXPLAIN SELECT * FROM `t_user` WHERE user_id=146484531

7.null
MYSQL不用访问表或者索引就直接能到结果。dual是一个虚拟的表,可以直接忽略
EXPLAIN select 1 from dual

MYSQL不用访问表或者索引就直接能到结果。